本文是一篇酒店管理论文,本文通过对一定量用户的历史行为数据进行机器学习模型的训练,通过比较得出随机森林训练出的模型精度更高,接下来就可以用训练好的模型来对未来的数据进行预测,来识别出那些更有消费倾向的用户,然后对这些用户再进行更精准的识别,利用现在的互联网算法技术对这些用户进行更精准的千人千面的推送。
1绪论
1.1 选题背景和研究意义
1.1.1 选题背景
酒店管理论文怎么写
21世纪以来,我国经济建设方面取得了长足的进步,人们的物质生活越来越丰富,越来越多的人开始享受精神世界的满足,他们想体验不一样的生活,越来越多的人开始选择走出家门去见识外面的大千世界,根据最新的统计数据显示,我国国内游客的人数在2008年的时候还只有171200万人次,但是近十几年一直保持稳定增长,在2018年的时候国内旅游人数已经超过了554000万人次,是2008年旅游人数的三倍多。我国2019年全国的GDP总量超过了99万亿元,对比2018年增长了超过6个百分点,全国人民的人均可支配收入也达到了3万元以上,相比2018年增长接近6%,2019年国内旅游人数也超过了60亿次,比2018年增长了8.4%,旅游业对GDP的贡献也越来越高,约占10.94万亿元,占GDP的11.05%,旅游业的高速发展势必会带动酒店行业的发展,我国酒店行业的市场规模也在不断向大规模,向高质量发展。
移动互联网已经快实现全国的普及,我国的网络用户数以及快要追上我国的人口数了,人们在日常生活中体会到了网络带来的便捷,现在人们一切的生活消费等都转移到互联网上进行,手机支付已经养成了习惯,信息的获取渠道也越来越多。互联网的发展势必还会带动国内与国外的旅游市场不断成熟,不断向在线酒店与旅游行业进行渗透,与此同时游客的消费观念也在不断的转变,对于旅游和酒店的要求也越来越多样化,消费者越来越喜欢便捷的在线预订方式,在线预订酒店领域,顾客可以通过在线上专门的预订平台或者酒店自己的平台进行在线预订,用户通过线上向旅游或酒店服务提供方进行产品和服务的预订,在付款的时候也可以选择线下付款或者直接在线上进行支付,各个服务的提供商为了让用户的需求得到更好的满足,更是提供了从酒店、机票、旅游攻略等一条龙的服务。在这样的大环境下,许多传统的行业都需要顺应时代的潮流改变现有的经营模式,将现有的模式向互联网上进行转变,是所有企业为了应对信息化的必经之路,这也是为了符合全球发展的大趋势,增强自身的竞争力。
............................
1.2 国内外研究现状
1.2.1国外相关研究
国外针对在线用户的行为研究从20世纪就开始了,由于当时互联网的发展的受限,也没有现在这样的计算能力,用户的数据量也比较少,所以在线研究一直发展很慢,到了21世纪,互联网的快速兴起与机器学习掀起的热潮,使得互联网和现实生活日益结合紧密起来,一些科技公司开始注重对数据的研究,希望通过计算机对日益增加的数据进行研究,以从数据中挖掘商机,用数据驱动公司前进。其中,Srikant R和 Yang Y就曾在2001年提出过可以通过用户在网站上页面的浏览行为来进行预测没有被浏览的页面的算法,主要思路是根据浏览者的点击行为和点击行为发生的时间来区分页面是否会被点击,这就造成一个缺点就是由于划分的依据是时间,所以浏览者会有同化的趋势。Mihara等人在2007年发现可以根据用户在某页面的浏览时长当成用户对访问页面的喜好指标之一,用启发式的方法对用户的访问模式进行提取,然后对用户进行个性化推荐。Fabian Abel在2011年通过研究Twitter 用户在网络上发布的几十万条文字内容,通过语言处理可以总结出内容所表达的主题词和内容所属类型,并且将外界网站与主题内容相关的数据来对内容进行丰富,进而通过这些数据来描画用户的行为,然后根据这些数据建立模型,从而根据不同用户的便好进行有针对性的信息推送。Allahyari Soeini 等人在2010年用机器学习聚类方法中的K-means 对用户聚类分析,用CART决策树来进行数据挖掘,分析出用户流失的原因,然后分析出解决流失的策略,用来降低用户的流失。还有很多的学者通过对银行的信用卡用户数据进行分析,由于银行的信用卡数据一般都是不均衡的,他们就设计出用来解决数据不均衡的方法,现在用的较多的就是SMOTE方法,也有采用重采样的。
......................
2 机器学习算法原理
2.1 机器学习概述
机器学习是对算法的一个统称,使用这些算法可以在我们平时不能观测出来规律的海量数据中挖掘出其内隐含的汇率,一般是用来做预测或者做分类。更详细的说是机器学习就是一个通过输入海量的数据,找出一个有规律的函数的过程,相当于一个黑盒,你输入进去的是数据,盒子机会输出计算的结果,一般输出的这个函数会比较复杂,有时不太容易用表达式的形式进行表达。我们使用机器学习最终的目的不是为了对我们的样本数据进行训练,而是将学习到的函数应用到新的数据中,且能在新样本中有很好的表现,我们将这样的能力称之为泛化能力。
为了得到一个好的函数,可以分为以下三步:
第一,根据我们对于数据和模型的理解,选择一个适用的模型,这个有时候需要我们进行多个模型的试探,最终才能得到一个较好的模型,有时候为了追求模型的精度还要将多个模型进行组合。
第二,从第一步得到模型之后,我们如何判断一个模型的好坏呢,这里通常有一个衡量的标准那就是损失函数,需要根据研究的问题和数据的特性进行损失函数的选择,如回归问题一般采用欧式距离,分类问题一般采用交叉熵代价函数。
第三,为了找到最好的那个函数,我们经常会用到很多处理方法,比如用到梯度下降法、最小二乘法等算法。
.........................................
2.2 Logistic回归模型
逻辑回归实际上也是一种线性回归,它的模型的表达式和线性回归的表达式十分的相似。逻辑回归为了实现将函数值从(−∞,+∞)映射到(0,1)从而对函数进行对数的变化,我们可以使用默认的分类数值,也可以自己选择一个阈值来进行划分类别。逻辑回归虽然叫回归却是分类模型,主要用来对连续型自变量和离散型因变量的计算。离散型因变量就是指取值为0,1,2⋯⋯等离散值的变量,根据取值的不同特点,离散型变量又分为二元变量、多分变量和计数变量,因变量是取值分别为0和1的二元变量,通常用y来表示,当y的取值为1时就表示某件事情或某种风险的发生,当y取值为0时表示某件事情或某种风险不发生。
最近邻算法是哈特等人在20世纪70年代提出来的,它也是一种分类算法,在数据挖掘算法领域算是一种比较经典的算法,距离现在已经有四十多年的历史,K近邻算法的原理就是,输入我们的样本量,然后我们设定K值,并且可以选择计算距离的方法,然后算法就会根据我们设定的K值将样本分成K类,这样一个最近邻的算法就计算成功了,之后再像模型中加入新的样本,会根据之前计算好的方法来计算新的样本距离之前训练模型的样本的距离,通过多数投票或者设定权重的方法将其归于哪类样本,所以我们无法观测到最近邻算法的学习过程。
.........................
3旅游酒店行业发展现状分析 ........................... 15
3.1在线酒店的概念.......................... 15
3.2旅游酒店行业现状........................... 15
3.3在线酒店的优势................................ 20
4 描述性统计及预定倾向分析与识别.......................... 21
4.1数据来源与描述性统计....................................... 21
4.1.1变量的描述性统计 ...................................... 21
4.1.2数值型变量的描述性统计 ................................ 22
5结论与建议 .......................... 36
5.1结论.............................. 36
5.2建议................................ 37
4 描述性统计及预定倾向分析与识别
4.1 数据来源与描述性统计
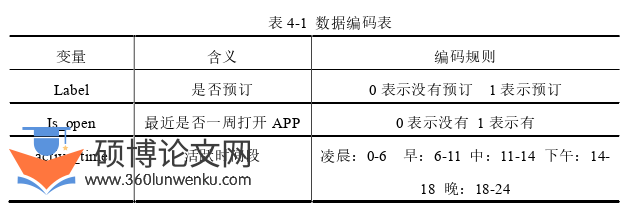
本文所用的数据来自国内某酒店预订平台一段时间的用户行为数据,考虑个人信息安全本数据不包含个人基本数据,数据经过脱敏处理,本文最终选取58904条数据,其中包含一个因变量label,18个特征变量,因变量表示是否预订酒店,特征变量主要有lastpvgap(距上次浏览时间)、Visit_detailpagenum(观看酒店详情数)、cr(转化率)、preference(平台满意度)、Open_num(打开APP次数)、Price_sensitive(价格敏感系数)、lowestprice(首次预订酒店价格)、Consuming_capacity(消费能力)、businessrate_pre(星级偏好)、avgprice(平均价格)等。算上标签(label)总共有三个分类特征,我们采取对分类特征进行哑变量处理,使用R语言中的as.factor函数对三列数据进行哑变量处理。几个变量的含义如下:
酒店管理论文参考
....................
5 结论与建议
5.1 结论
大数据算法近些年在处理极速增长的数据方面,解决了很多人们生活中的很多难题。在互联网行业应用尤其广泛,越来越多的人选择使用互联网来帮助自实现出行自由化。面对海量的客户,企业没有足够的资源和精力去迎合每一个客户。对此,本文主要使用随机森林算法,并引入决策树和 logistic 回归以及KNN算法做辅助性判断,对有在平台预订倾向的客户进行识别研究,并根据模型找到影响用户预订行为的主要因素,在企业资源有限的情况下,优先关注价值度较高的用户。在实证部分我们对几个模型的识别效果进行了比较,通过混淆矩阵计算的准确率和ROC曲线计算的AUC值等形式,进行模型性能评估和比较。实验表明:
(1)在随机森林进行调优的时候,有两个重要的参数。一个是树节点预选的变量个数用mtry 表示,它决定了单颗树的深度;另外一个就是随机森林中数的个数用 ntree表示,它决定了随机森林中树的数量。通过调整这两个参数可以实现随机森林的各种组合。通过最优参数选取我们得到最优的mtry的值为2 。在确定最优 mtry 参数后,最终确定了所对应的 ntree 为 449;
(2)通过相关指标评估,在决策树、Logistic 回归、KNN和随机森林几者中,随机森林算法表现最优,具有相对较高的识别能力。无论是通过AUC值进行比较还是通过计算模型的预测精度,都是随机森林的预测效果最好,说明集成算法的优势还是很明显的,我们可以将随机森林用于实际应用中对用户是否有预订行为进行预测。
参考文献(略)