第一章 绪论
1.1 研究背景
在大数据时代,随着数据量的不断增长和计算机软硬件基础设施的升级迭代,深度学习获得井喷式发展,机器学习又一次成为了热点并应用到社会生活的诸多领域中。对于金融领域而言,目前深度学习主要应用于中低频交易,代表机构有 Two Sigma Investments,Bridgewater Associates, Renaissance Technologies 等。此外,金融市场中通常包含海量数据,这些数据具有维度高,噪声大的特点,传统的计量经济学方法有时并不适合分析这种数据,对金融数据的预测一直都是金融领域里富有挑战性的问题。传统的监督学习方法很大程度上依赖人工设计选择特征和构建标签,传统强化学习方法中智能体的结构比较简单,由于金融市场的复杂性和市场参与者行为不断变化,交易智能体捕捉股票市场信息时存在一定困难。而深度学习的表征能力可以应对金融市场复杂的高维数据,与强化学习相结合,深度强化学习具有直接从高维数据中学习控制策略的强大力量。因此,基于深度强化学习的股票交易模型不需要“外部监督”,智能体通过不断试错进行学习,并直接进行决策。这不仅有助于上述部分难题的解决,更为金融数据的分析与预测提供了一个崭新的思路。
......................
1.2 研究内容及创新点
本文强化学习模型设计思路如下:研究深度 Q 网络算法,基于长短期记忆网络构建交易模型,并用一层全连接网络将交易动作变换到指定的取值范围。交易过程中考虑交易手续费、印花税等交易成本。设置目标函数时引入了多目标马尔科夫决策过程,不仅要最大化账户平均日收益,还要控制日收益波动。在训练智能体的过程中,使用经验回放策略,即从智能体以往的状态转移中随机抽取样本进行训练,尽量保持模型的泛化能力。数据选取方面除了需要考虑基本的开盘价、闭盘价以及交易数量等基本特征,还包括了股票的相关技术指标特征。将数据进行一系列的特征工程和归一化处理后,将其输入到深度神经网络中预测下一时刻的动作。运用梯度下降法不断优化模型的损失函数,进而更新模型参数和策略,最后将经过训练的模型进行回测以验证训练效果。
本文创新点:1.本文根据马尔科夫决策过程,在传统的单目标强化学习的基础上创新性地提出了多目标深度强化学习模型,在以收益为目标的同时还以降低交易风险为目标,力求在最大化账户总收益的基础上限制总收益波动。2. 本文所用股票数据除了需要考虑基本的开盘价、闭盘价以及交易数量等基本特征,还利用了 TA-Lib 库生成了相关的股票技术指标作为特征。将长短期记忆网络用于股票数据中不同维度的特征提取。
..............................
第二章 量化投资文献综述
2.1 国内外研究现状
已有学者对传统机器学习的金融领域应用做出了研究。董素娟(2016)参考了融智评级中心对量化产品的分类,在此基础上把我国量化产品分为量化选股类、市场中性类、套利类和复合模型类四类产品。周荣喜等人(2019)利用随机森林和xgboost 等算法挖掘出6个债券违约因子,利用 XGBoost 和线性回归算法搭建了债券违约模型,并通过实证检验了模型的有效性。
国内较多学者在深度学习方面做了相关研究。张炜(2015)等学者基于神经网络构建股票预测模型,通过遗传算法降维的方式解决输入数据维度高的问题,结果显示遗传算法能够提高模型训练效率、提升预测准确率。傅聪等(2020)讨论了策略梯度算法与特征编码方式(RNN、CNN)在处理金融时序数据时的优劣。实验表明,使用 RNN 编码特征的方法有比较好的短期效果。曾志平等(2017)改进了深度信念神经网络并得到新的决策算法,该算法的准确率超过了 90%。曹雷欣,孙红兵(2017)以上证股票收益率为样本,构建后向神经网络并搭载了多变量的灰色 GM 函数,对样本进行预测,预测效果得到了提高。杨青等(2019)构造了一个深层长短期记忆神经网络并将其应用于全球 40 多个股票指数三种不同期限的预测研究,结果发现 LSTM 神经网络具有很强的泛化能力,对全部指数不同期限的预测效果均很稳定。孙达昌等(2018)选取卷积神经网络和 LSTM 神经网络分别构建涨跌分类模型,在此基础上提出高频交易策略,并以沥青期货主力合约为例进行回测检验,相比于人工神经网络高频交易策略,回测检验结果表明基于卷积神经网络和长短期记忆神经网络的高频交易策略的盈利能力较强,泛化能力较好。李章晓等(2019)利用循环神经网络建立汇率预测模型,用来预测外汇产品的价格并计算期望收益率。接着建立了一个双目标的投资组合模型,即最大化期望收益率与最小化风险。基于多个外汇产品的期望收益率与投资组合模型,利用多目标进化算法来搜索出最优的投资组合。王悦霖等(2019)使用从股票数据中提取的多种特征,作为 LSTM 模型的输入,将次日的涨幅作为该模型的输出进行训练。从而对次日股票的涨幅进行预测,在一定程度上说明股票收益的规律性,杨青等(2019)建立了考虑卖空限制的传统动量策略,和用堆叠自编码器进行特征学习后进入前馈神经网络进行训练的深度学习方法改进策略。实证表明,基于深度学习方法改进的动量策略在两个研究时间段均能够获得比传统动量策略更高且更稳健的收益。
............................
2.2 文献述评
虽然国内外量化投资的研究发展情况不尽相同,但是对于量化策略的回测与应用而言,量化模型的设计和搭建至关重要,这也体现出了从量化投资的本质。而设计不同量化策略所用到的建模思路也不同,其中有些思路来源于交易员多年实盘交易的经验总结,有些出自于经济金融学术界的理论研究。
就目前而言,已有相当多的学者将传统机器学习算法应用到了金融领域中,如聚类、回归、树模型等,也有不少投资者将深度学习应用到了金融数据的挖掘分析中。尽管深度学习在图像和语音识别等许多领域内都有着出色的表现,但是目前在深度强化学习的金融应用方面的研究相对较少。本文丰富了基于深度学习和强化学习的投资理论,不仅有利于拓宽深度强化学习理论的实践应用,同时丰富了股市投资的建模工具,在量化投资的策略设计和模型搭建上做出了崭新的尝试,具有一定的理论研究价值与实际应用意义。
图 4.1 多层前馈神经网络
第三章 投资相关金融理论 ............................... 6
3.1 传统投资理论 ...................................... 6
3.2 量化投资理论 .................................. 7
第四章 深度强化学习相关理论 ........................... 9
4.1 深度学习相关理论 .................................... 9
4.2 循环神经网络 ................................... 10
第五章 基于深度强化学习的股票交易模型 ...................... 18
5.1 数据选取 ................................................ 18
5.2 智能体网络结构设计 .......................................... 18
5.3 智能体目标设置 .................................... 18
第六章 模型结果回测检验
6.1 模型回测总体表现
本文从目前中国 A 股的十个不同行业中各自选取一支有代表性的股票,组成资产池中的十支股票,并将账户初始的一百万金额平均分为十份分别对这十支股票进行投资交易。
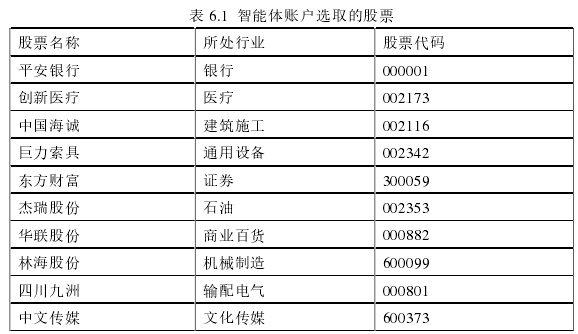
表 6.1 智能体账户选取的股票
第七章 总结与展望
7.1 研究总结
本文开头先是介绍大数据时代对数据挖掘的迫切需求和机器学习在金融投资领域的应用现状,然后叙述了文章的研究方法,研究内容,文章结构,并对文章所用模型及参数做了简单介绍。
第四章介绍了深度强化学习的相关理论,在深度学习方面,着重论述了深度神经网络的历史和结构特点,以及擅长处理序列数据的循环神经网络和长短期记忆网络的结构特征。然后介绍了强化学习、深度强化学习的基本理论,包括引入马尔科夫决策过程为强化学习建模,深度强化学习算法的分类以及这两类算法之间的区别。
第五章是利用深度强化学习运用到股票交易模型构建。本篇章节也是本论文工作的重点,首先介绍了模型训练及回测所用的数据,其次在深度 Q 网络的基础上同时考虑了交易的收益与风险,提出了多目标深度强化学习模型。之后详细介绍了智能体的目标、动作设置、训练方法和参数设置,同时选择了 Pytorch 作为本文所用的模型框架。最后选取单个股票的数据对模型进行了检验。
第六章是模型训练结果的回测检验,本章选取了 A 股市场上的十支不同行业的股票组合作为账户资产池并进行了回测,从账户的总收益、收益率、收益标准差、夏普比率进行对比分析,验证了多目标深度强化学习模型在 A 股市场上的投资有效性。
从模型的回测结果来看,模型在回测期间都取得了不错的收益。但是相对而言,监督学习模型的数据处理流程更为繁琐,除了清洗数据,归一化处理之外监督学习需要人为定义标签并将其输入模型,而强化学习的训练时没有标签的,其本质上是智能体与环境的交互,也就是智能体的“不断试错”,优化目标函数进而更新模型参数。
另一方面,监督学习的学习过程是静态的,给模型输入什么样的数据模型就会学到什么,而强化学习的学习过程是动态的,随机性更强。监督学习解决的更多是感知问题,而强化学习解决的主要是决策问题,从这个角度来说,监督学习更像是工具而强化学习更像大脑。
参考文献(略)