本文是一篇计算机论文,本文在轨迹表达和轨迹挖掘效率两个方面开展研究,针对两个研究内容,在分布式计算框架的基础上,提出并设计了轨迹表达处理中线段聚类算法和频繁轨迹挖掘算法,分别开展了实验分析对比,并验证了所提算法合理性和有效性。
第一章绪论
1.1研究背景及意义
随着大数据时代到来,数据挖掘的重要性日益凸显。数据挖掘是人工智能和数据库领域研究的热点问题,所谓数据挖掘是指从大量数据中揭示出隐含的、先前未知的并有潜在价值的信息的非平凡过程。数据挖掘的核心工作是从看似杂乱的事务数据集中挖掘出可以帮助人类分析事物和规律的信息。因此,从大量信息中快速、有效地发现信息之间的关联规则成为一个重要的探索方向,其中,频繁模式挖掘是发现关联规则的重要部分。
在如今这个通讯技术与传感定位技术极速发展的时代,我们可以在各类带有定位功能的智能终端上获取到大量的运动对象定位数据记录。通过利用定位数据我们不仅能够浏览位置信息,而且能够从这些数据中挖掘发现出隐藏的有效轨迹行为模式。然而,随着人们的日常活动轨迹数据在日益不断地增加,怎样从大量轨迹数据中挖掘提取信息以提供准确的定位服务成为位置感知计算的首要问题。所以,轨迹频繁模式挖掘最近也引起了越来越多的关注及研究,相应的许多有关技术也已经发展出来,用于发现人们的运动模式。在分析了大量的数据资料后,冈萨雷斯等人[1]发现,人们的运动轨迹在时间和空间两方面具有很高的规律性。用户具有对某些已知位置的高频访问权限,这意味着位置是轨迹数据的关键信息。个人位置是基于位置的服务[2]的关键组成部分,从轨迹数据中准确地识别单个位置,可以使位置感知应用程序更加智能[3]。例如,导航器可以使用个人位置来指导用户[4]。此外,基于位置的推荐系统可以推送与人位置相关的信息[5]。位置预测系统还可以根据个体当前的位置来推测个体的下一个目的地[6],空间查询系统可以提供情境化的信息[7]等。
..............................
1.2研究现状
与传统频繁模式挖掘方法相比,轨迹频繁模式挖掘的时空轨迹数据具有时间、位置和语义三大特征。针对轨迹数据的特征,挖掘时空轨迹的频繁模式方法主要有三类:(1)基于地理信息的轨迹频繁模式挖掘。(2)基于时间周期的轨迹频繁模式挖掘。(3)基于语义信息的轨迹频繁模式挖掘。
1.2.1基于地理信息的轨迹频繁模式挖掘
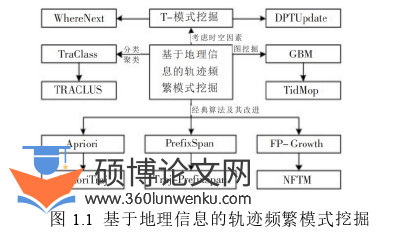
基于地理信息的轨迹频繁模式挖掘主要利用了轨迹数据中与地理位置信息有关的一些数据进行了轨迹频繁模式挖掘,从而能够找到在时空轨迹数据集中不断重复产生的频繁位置序列。目前已经涌现出了诸多经典的基于地理信息的轨迹频繁模式挖掘方法,如图1.1所示。
计算机论文参考
ApripriTraj[8]、Traj-PrefixSpan[9]、NFTM[10]算法是基于频繁模式挖掘著名算法Apriori、PrefixSpan和FP-Growth改进的,并且应用在轨迹位置频繁项挖掘上。这些方法全部是以支持度为基础的,旨在找出全部的频繁轨迹数据集,但由于该方法要多次扫描数据,导致该算法在效率上表现较差。Lee A等提出了一种能够生成用于扫描时空轨迹数据集的映射图与数据表的全新图挖掘GBM算法[11],降低了数据集的扫描次数。胡军光等人提出一种基于寻求交点的方法来实现对轨迹标识表循环更新的TidMOP算法使算法提升了效率[12]。Jiang Z等人通过提前计算出路网的Hausdorff长度来使轨迹数据表的更新速率提升[13]。
...................................
第二章基本理论及相关技术简介
2.1轨迹频繁模式挖掘基本概念
2.1.1频繁序列模式挖掘概念
作为新的数据挖掘技术,序列模式是一种通过在关联规则中添加一个时间的概念来根据时间序列搜索模式的相关性的技术。频繁序列模式挖掘是指在用户设定的最小支持度下找到所有频繁序列用来帮助解决事务间的模式的挖掘问题。用户设定最小支持阈值的作用是在挖掘的过程当中剔除掉不满足需求的模式。发现序列模式问题是受到了零售业问题的启发。而这些研究结果也适用于许多科学领域和商业领域。
关联规则作为目前国内外学术界关注的热点之一,也是在数据挖掘中一项非常必要的关键技术。关联规则体现的是事物之间的关联性,形如X→Y所表示,且设定X∩Y为空集,X⊂Y为频繁项集。关联规则X→Y的最小置信度是由用户所设定的阈值,是指在数据集中同时包含X和Y所占百分比。
项集的支持度是该项集占所在的数据集中的百分比。若项集支持度满足用户设定的最小支持度,就说它是频繁项集。挖掘频繁项集是数据挖掘问题的关键步骤,是在数据集中找出满足用户设定的最小支持阈值的支持度的所有项集,目前也已经提出了许多针对在数据集中挖掘频繁项集问题的挖掘算法。
Agrawal和Srikant又根据一些具有时间特征的交易数据提出了一种挖掘序列模式的新方法[35]。序列模式挖掘不是像关联规则挖掘那样只是注重事务间的相关性,对于发生在事务之间的顺序也十分的注重,有着深层次的分析与研究。例如,S=<(X)(Y)>可以代表消费者购买了商品X后,在一定的时间段里,有可能购买商品Y的情况。要想取得此种结果,就要寻找出频繁项集,需要对各个子序列进行支持度的计算。挖掘频繁序列模式是挖掘在序列数据集中支持度满足设定的最小支持度阈值的全部频繁序列,但挖掘的频繁序列是按照一定次序进行排列的。
......................
2.2云计算与分布式相关技术
在进行大量的数据处理工作时,处理数据的速度代表着工作的效率高低。在分布式系统出现以前,要想提高处理数据的速度,必须要提升单个处理器的性能和频率。分布式系统的诞生,使传统的限制得以突破。将一个大任务分解为若干个小份的作业,并分配在多个计算机设备上来同时并行完成,最终协同合作,这样既能保证系统的稳定,又能使系统的运行速度达到最大化。
2.2.1 MapReduce
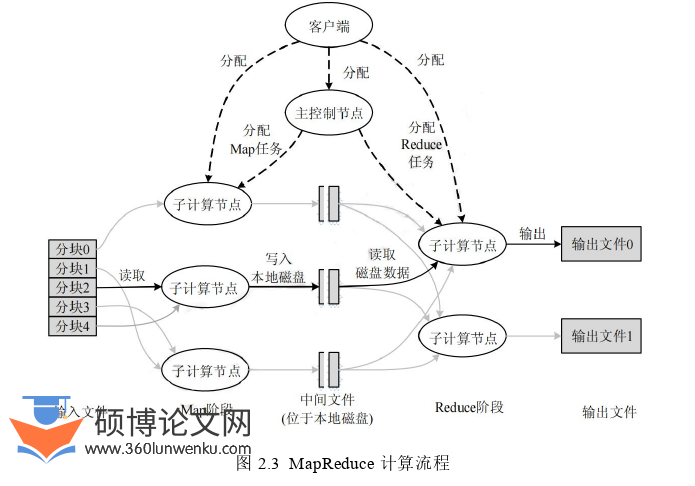
Google公司在2004年时首次将MapReduce技术公开推向了全世界。它是由Map与Reduce函数并行处理大规模数据来完成任务的一个分布式体系架构模型[56]。
MapReduce的灵感来自于Lisp编程语言中的Map与Reduce函数。其基本思想是将大量的数据处理分为几个有单独工作能力的Map作业,再把这些数据分配到各个处理器,在此过程中会生成很多结果,然后合并Reduce作业后生成文件作为输出。MapReduce是早期的数据存储、调度、通信、容错管理、负载均衡等技术的分布式体系架构[57],给后来开发分布式系统做了充分的铺垫,降低了并行开发的难度。MapReduce从复杂的细节中提炼且实现了分布式体系架构中的分配、调度、监控、容错等功能逻辑,从而使开发人员无需具备大量的并行计算能力和对分布式系统的应用经验,充分利用具有庞大规模的分布式资源。
..................................
第三章轨迹表达与线段聚类算法·······················21
3.1轨迹抽象表达问题定义··························21
3.2轨迹线段聚类算法实现···················28
第四章轨迹频繁模式挖掘算法研究··············35
4.1问题定义·························35
4.2轨迹频繁模式挖掘算法····················37
第五章总结与展望·······························47
5.1总结····························47
5.2展望·······················47
第四章轨迹频繁模式挖掘算法研究
4.1问题定义
计算机论文怎么写
序列数据集S是由许多序列构成的集合。其中存在一个序列s={b1b2…bm},在序列s中存在有子序列为α={a1a2…an},称序列s包含序列α,用α⊆s表示,且存在有整数1≤j1<j2<…<jn<m使得a1⊆bj1,a2⊆bj2,…,an⊆bjn。α在S中的支持度记作Suppor(tα),表示α在S中所占比例。最小支持度阈值记作为min_sup。如果序列α为频繁模式,那么Support(α)是大于等于min_sup的。用标记l-来表示频繁序列模式的长度。
定义4-1前缀。序列里的各个元素的项的排序都是依据字典的次序进行的,存在序列α=<e1e2…en>和β=<e1'e2'…em'>(m<n),若有ei'=ei(i≤m-1),集合em'⊆em且(em-em')里所有的项都是在em'的项之后,则称β为α的前缀。
定义4-2投影。存在有序列α和序列β,如果β是α的子序列,那么序列α关于序列β的投影序列为α',且需要满足的要求是序列β为序列α'的前缀,从而投影序列α'成为序列α当中的最大子序列。
定义4-3后缀。如果子序列β=<e1e2…em-1em'>在序列α中的投影序列是α'=<e1e2…en>(n>m),那么α'相对β的后缀序列是<em''em+1…en>,其中em''=(em-em')。
定义4-4投影数据集、支持度。当在数据集S中存在有序列模式α时,且序列α为序列β的前缀序列,那么在序列数据集S中,序列α的投影数据集是前缀为α的所有序列的后缀序列,用S|α表示。在α的投影数据集S|α中,β的支持度等同于在β⊆α·y的情况中序列y的数目。
................................
第五章总结与展望
5.1总结
在大数据背景下,时空轨迹频繁模式挖掘是数据挖掘与位置感知研究领域的研究热点,是对移动对象的行为模式和规律进行分析的一个重要方法,在基于位置服务的城市规划、交通运输、出行服务、旅游推荐等多个方面取得了良好应用,给经济发展和社会生活带来深远的影响。
本文在轨迹表达和轨迹挖掘效率两个方面开展研究,针对两个研究内容,在分布式计算框架的基础上,提出并设计了轨迹表达处理中线段聚类算法和频繁轨迹挖掘算法,分别开展了实验分析对比,并验证了所提算法合理性和有效性。具体总结如下:
(1)针对轨迹数据长短不一、复杂多样等特点带来的轨迹表达困难的问题,所提启发式轨迹线段分布式聚类算法利用几何学方法寻找轨迹线段簇心并对邻近的轨迹进行聚类,减少了噪声轨迹的影响。最后采用公共数据集进行了实验验证,结果表明该算法有效地提升了轨迹表达效果。
(2)针对轨迹数据规模大、单机处理效率低的问题,所提轨迹模式挖掘算法通过前缀剪枝的方式,有效减少投影数据的产生;充分利用Spark框架基于内存计算的优势,有效提高了挖掘效率。最后,从算法运行时间、性能及拓展性等方面,将该算法与其它算法进行对比,在公共数据集上的实验结果表明本文所提出的算法具有良好的性能,提升了轨迹数据挖掘效率。
参考文献(略)