本文是一篇计算机论文,本文提出了一种基于分类器与遗传算法相结合的特征选择方法(GACFS),研究分析了该方法在两种UCI数据集上得到的分类精度;提出了一种基于特征选择和改进的SENet的点击率预测模型(FSISC),研究分析了该模型在Criteo数据集上的点击率预测效果、运行时间和稳定性。
第一章 绪论
1.1 研究背景和意义
互联网和大数据时代的飞速发展、移动互联网的繁荣改变了人类的生产和生活,人们可以简单地通过互联网进行购物、学习、工作、娱乐等活动,这不仅产生了大量的用户和需求,这股信息浪潮为人工智能算法的研究提供了庞大数据,而且也在不断地改变广告等传统行业。早期的传统广告大多是线下的,通常通过报纸、杂志、广播、电视等进行展示,这种传统的广告展示方式存在几个问题:广告没有对用户进行区分,例如电视中的广告是在固定时间播放的,所有观众都可以看到广告,但只有少数人是广告的潜在客户,也就是说传统的广告展示方式缺乏针对性;广告商很难知道用户对于广告的关注度、用户购买率、持续购买率等;不仅投资成本高,而且宣传需要大量人力,因此很难对其进行优化。大数据技术与互联网广告模式的结合将解决这些传统广告中存在的问题,大数据分析技术可以分析潜在客户的特点,从而向潜在客户展示定向广告,互联网广告更容易评估广告效果,并根据用户的点击、转化等行为来衡量广告投资效果的量化指标。与传统广告和最近流行的户外广告相比,互联网广告的传播范围广、受众多、覆盖面广,具有无时间限制、广告效果持久等压倒性优势。
互联网技术作为国家经济发展的动力之一和最具影响的技术成就之一,它对于促进国民经济发展、提高企业劳动生产率、改善人们生产生活方式具有很大的推动作用,尤其是人们接触信息方式的转变使得广告行业中出现了互联网广告模式。由于我国的广告行业数量大,客户集中度较低,因此近年来我国企业的高速成长使广告在规模上也得到了较大的增长,广告主数目及客户消费支出均在增长。中国广告业在2015至2019年呈现出了较大的发展势头,2015年的行业规模已达5973亿元,到2019年这一数字将达到8937亿元,平均每年以10.6%的速度增长;然而互联网广告市场凭借互联网的增长惯性、用户增长红利及疫情给在线商务带来的机遇,2020年仍保持13%左右的增长率,与 2020年相比,2021年整体广告市场的增长率超过11%。尽管在线广告市场增速放缓,互联网广告市场渗透率持续提升,由2018年的51.3%上升到2020年的59.5%,预计2022年将达到60.7%。从这些数据可以看出互联网广告市场占据绝对优势,未来互联网广告市场还有很大的成长空间。
.................................
1.2 国内外研究现状
广告点击率的准确性不仅会对用户的使用带来很大的冲击,而且对广告主和广告商的收益也有很大的影响。此外,互联网的快速发展使得用户的点击量不断增加,广告的精准预测也越来越难以实现,这也成为了学术界和工业界普遍关心的问题,本节将简要阐述国内与国外的相关研究状况。
1.2.1 基于机器学习的点击率预测模型
最早流行的预测点击率的算法是线性模型,比如,逻辑回归(Logistic Regression,LR)模型[12,13]。随着数据量的增加,McMahan等人[14]于2013年提出了在线稀疏学习算法(Follow the Regularized Leader,FTRL),以解决LR模型的在线学习问题。点击率预测的关键是学习特征组合,例如,在现实生活中,可以发现女性比男性更喜欢化妆品,因此特征之间存在关联性。2014年Facebook发布了GBDT(Gradient Boost Decision Tree)+LR模型,将决策树模型与LR模型相结合,可以自动学习有效的特征组合。点击率预测任务的一个特点是存在大量的离散特征,然而,树模型善于处理连续特征,故GBDT模型尚未得到广泛应用[15]。
1.2.2 基于FM的点击率预测模型
由于线性模型不能用于组合特征,在使用模型之前必须手动构建特征,这不仅需要大量的时间,还需要一定的知识和经验。因此CTR任务中最常用的因子分解机(Factorization Machine,FM)模型随即产生,FM模型可以自动学习两个特征之间的相互作用,减少了一部分的组合特征选择工作。
Rendle于2015年提出了FM模型,在隐向量内积中学习元素级特征组合以解决特征组合问题;将高维稀疏的特征向量映射到低维连续的向量空间以解决数据稀疏问题[16]。由于FM模型没有考虑到不同的特征组合实际上会带来不同的信息,2016年Juan等人在FM模型的基础上提出了Field-aware Factorization Machines(FFM)模型,利用特征域的思想将具有相同属性的数据特征划分到同一个特征域(特征域和特征之间是一对多的关系),并使用不同的映射向量与其他特征域进行组合,以增强模型的表达能力[17]。2018年Pan等人[18]提出的Field-weighted Factorization Machine (FwFM)模型在二阶组合特征的基础上增加了一个参数,以便在建模不同域中不同特征的交互时可以更高效地消耗内存。2020年Pande[19]提出了Field-Embedded Factorization Machine(FEFM)模型,该模型中引入对称场对矩阵嵌入来学习特征交互的场特异性,增强了场对交互的可解释性,其模型复杂度明显低于FFM,类似于FM和FwFM。
............................
第二章 相关理论基础
2.1 相关概念的解释
2.1.1. 点击率预测问题定义
点击率预测问题的形式如式2.1所示,在学习点击率预测模型的过程中,首先需要确定所学习的模型,即????(∙)的形式,例如LR、FM、DeepFM等模型;其次根据学习的模型中用到的对数损失函数等准则确定是否已经学到最优模型,在监督学习中要学习到损失函数????(∙)最小时的模型参数,最后是求解模型的参数向量????的计算方法,常见的优化方法有梯度下降和随机梯度下降。
2.1.2. 特征组合定义
非线性问题的通俗解释是不能用简单的一条直线来很好地刻画出问题的分布情况,其解决方式可以是将两个及以上的特征进行特征交叉来对特征之间的非线性关系进行编码从而组合出新的特征。通常需要进行组合的特征包括离散特征和连续特征,但连续特征需要一定的处理才能实现特征组合。
二阶特征组合:即对两个不同的一阶特征进行交叉,假设在购买商品的场景中有性别和时间两个特征,将“女”和“双十一”组合起来则表示女性顾客会不会在双十一期间购买某商品。
高阶特征组合:即对三个及三个以上的一阶特征进行特征交叉,例如假设某主流应用中有性别特征:男性、女性,年龄段特征:少年、青年、中年和老年;游戏类型有动作游戏、角色扮演游戏、射击游戏,通过观察发现男性少年大多喜欢射击游戏,这就意味着用户的性别、年龄和游戏类型之间有着复杂的关系。
...............................
2.2 经典的点击率预测模型
如今,互联网的用户数量可能达到数亿,如何挖掘用户历史行为背后的特征交互是点击率预测问题的关键[29]。以电商平台为例,女性顾客大多喜欢化妆品、包包等店铺,大多男性顾客则喜欢浏览车、电子产品等店铺,因此可以组合性别和店铺类型来预测顾客的点击概率,更多的特征组合起来也是如此,因此高低阶特征都会在一定程度上影响最终的点击率结果[27,28]。近年来,研究者们一直在探索如何挖掘特征之间的非线性关系,本节将对经典的点击率预测模型进行详细介绍。
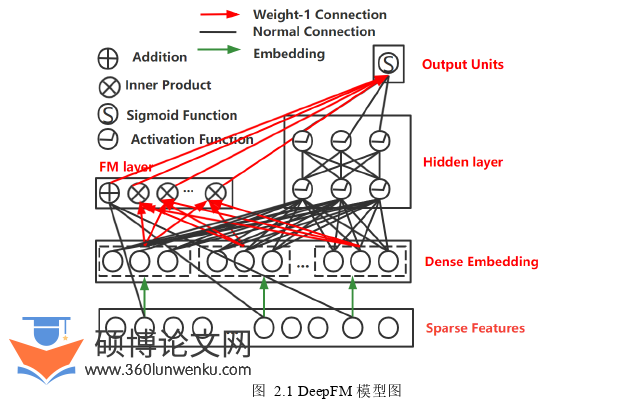
2.2.1 DeepFM模型
由于FM不需要进行特征工程即可获得低阶特征组合,故DeepFM模型将Wide&Deep模型中的LR替换为FM用于学习低阶特征组合,同时利用神经网络来实现高阶特征组合,两者都是通过深层和浅层模型进行联合来进行训练的[28]。
计算机论文怎么写
DeepFM模型结构图如图2.1所示,可以看到高维稀疏特征经过Embedding层被转换为低维稠密嵌入向量,之后嵌入向量被传到FM层和DNN层。从图中可以看出FM层和DNN层共享嵌入向量,其目的是确保模型的一致性和准确性。最后在输出层拼接FM层和DNN层的输出,并利用sigmoid函数得到最终的预测值。
...............................
第三章 基于分类器与遗传算法相结合的特征选择方法 .......................... 27
3.1 适应度函数的定义 ........................ 27
3.2 基于精英保留算子的选择策略 ............................ 28
第四章 基于特征选择和改进的SENet的点击率预测模型 ........................ 35
4.1 模型结构 .................................... 35
4.2 特征选择层 ................................... 36
第五章 总结与展望 ............................... 51
5.1 全文总结 .................................... 51
5.2 展望 ............................... 52
第四章 基于特征选择和改进的SENet的点击率预测模型
4.1 模型结构
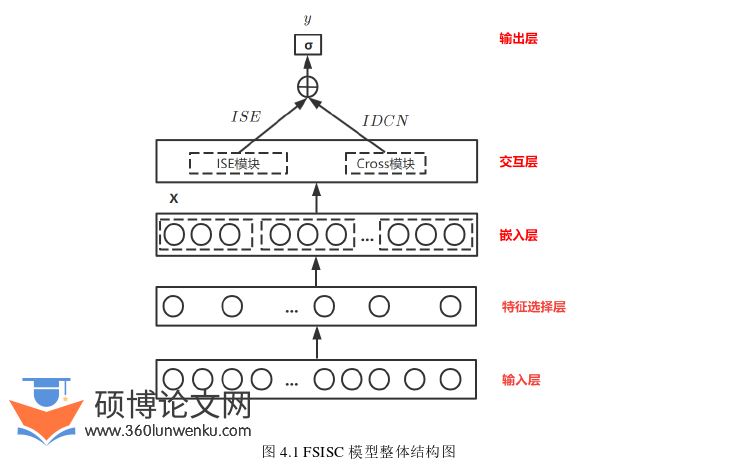
本节主要介绍FSISC模型的整体结构图以及具体步骤,该模型的整体结构图如图4.1所示,从图中可以看到,从整体上来讲该模型属于一种串行结构,中间的交互层是一种包含ISE模块和IDCN模块的并行结构。FSISC模型的大概思路为:首先将原始数据输入到最下面的输入层,然后经过中间几层结构对原始数据进行数据处理、特征及特征组合的学习,最后在顶部的输出层得到最终的预测结果。
计算机论文参考
FSISC模型的具体步骤如下:
(1) 在特征选择层中离散化原始数据中的所有特征,之后利用GACFS方法选择出一个能够代表原始数据的最佳特征子集,为最终的预测结果减少了一些干扰信息;
(2) 利用传统的嵌入层对特征子集进行嵌入表示,降低了特征子集经过独热编码后的向量维度并减少训练模型的计算量;
(3) 在交互层中对高低阶的特征组合信息同时进行学习,其实现方式是对交互层中两个模块进行并行学习,交互层中的ISE模块主要通过SEnet网络进行改进用于实现区分不同的特征对预测结果的贡献且快速地学到新特征,交互层中的IDCN模块将交叉网络和神经网络结合起来以隐式和显式结合的方式来学习高阶特征组合;
(4) 在输出层中对交互层中学到的两个模块的结果进行求和,再利用sigmoid函数计算得出最终的预测结果。
...................................
第五章 总结与展望
5.1 全文总结
本文提出了一种基于分类器与遗传算法相结合的特征选择方法(GACFS),研究分析了该方法在两种UCI数据集上得到的分类精度;提出了一种基于特征选择和改进的SENet的点击率预测模型(FSISC),研究分析了该模型在Criteo数据集上的点击率预测效果、运行时间和稳定性。下面将对本文的研究工作进行概括说明:
(1)对GACFS的实现过程、算法流程展开介绍,并针对GACFS实现特征选择之后的分类精度进行分析,为验证GACFS方法的有效性设计了不同的对比实验。
GACFS利用精英选择策略作为传统遗传算法的选择算子,然后分别结合机器学习中的几种分类器实现特征选择,其中先用训练集训练分类器,在此基础上计算测试集的分类精度以此衡量个体的质量从而逐步进行遗传算子。
在sonar和lung cancer两种UCI数据集上,GACFS在设计的几种对比实验中都实现了分类精度的提升。其中,在sonar数据集上GACFS方法与实验所用到的所有分类器结合得到的分类精度均比原数据集的分类精度有所提升,在lung cancer数据集上GACFS方法与实验所用到的除随机森林外的所有分类器结合得到的分类精度均比原数据集的分类精度有所提升;在两种数据集上遗传算法结合二次判别分析得到的分类精度与粒子群算法结合二次判别分析所得的分类精度相比分别提升了18.8%和26.5%。
(2)介绍了FSISC的模型结构,并设计了几种对比实验来对FSISC模型得到的点击率预测效果、运行时间和稳定性进行对比分析。
FSISC模型设计了一个特征选择层来实现特征降维处理,利用IGAFS得到一个较好的特征子集;之后在ISE模块实现二阶特征组合权重的分配问题,其中改进了传统的SENet学习特征权重的方式;在IDCN模块中利用深度交叉网络学习任意阶的特征组合,先将特征经过一个交叉网络学习高阶特征组合,使得交叉学习更加充分,然后再放到深度神经网络中进一步学习高阶特征组合。
参考文献(略)