本文是一篇计算机论文,笔者认为针对原始策略中使用的训练集数据较为单一的问题,我们的方法在生成新的训练数据时会通过Mixup操作对其进行增强。我们通过实验表明这样做有助于在决策边界附近生成更多样的样本,从而提升重训练的效果。
第一章 绪论
1.1 课题背景及研究意义
目前,人工智能和深度学习技术[23]在计算机视觉[20]、多媒体[14]和自然语言处理[10]等多个领域都取得了巨大的成功。但是深度学习系统的大规模应用同样会带来一定的安全隐患。比如在一些安全敏感的任务中,攻击者会根据深度学习模型存在的安全漏洞,通过各种手段绕过或直接对深度模型进行攻击。以图像分类任务为例,研究[37]发现在干净的原始图片上添加一些微小的扰动可以使深度模型输出错误的分类结果。如图1.1所示,对于原始图片,模型可以将其正确分类为山雀(Chickadee),但是在添加了扰动之后,模型就会将其错分为斑马(Zebra)。这类恶意生成的样本被称为对抗样本[2,18,28](Adversarial Examples)。

计算机论文怎么写
除了计算机视觉领域之外,研究[3,48]表明在多媒体和自然语言处理等领域中同样存在对抗样本。对抗样本的广泛存在揭露了深度学习的脆弱性[1],并由此引出了关于对抗性机器学习[19](Adversarial Machine Learning)的两大类研究方向:对抗攻击(Adversarial Attack)和对抗防御(Adversarial Defense)。对抗攻击主要研究如何生成更具攻击性的对抗样本,而对抗防御则试图通过提升模型的鲁棒性从而抵御对抗样本带来的不良影响。
.............................
1.2 国内外研究现状
如前所述,根据目标模型的结构和参数是否已知,可以将对抗攻击方法分为白盒攻击和黑盒攻击。主流的对抗攻击方法包括FGSM[12],I-FGSM[19]和C&W Attack[4]等。这些方法在白盒(黑盒)场景下通过计算目标模型(源模型)上损失函数的梯度并沿着梯度方向构建对抗扰动,随后将其添加到原始输入样本中来生成对抗样本。这些方法在白盒场景下均展现出了不错的攻击效果,但是在黑盒场景下的效果均不理想。其原因在于这些方法都是基于梯度计算来生成对抗样本,其构建的扰动都利用了模型的梯度信息。因此这些方法在白盒场景下的效果越好说明其对目标模型的拟合程度越高。而在黑盒场景下这些方法对源模型的拟合程度越高就会导致其在其他模型(即目标模型)上的效果变差。
根据是否需要访问目标模型,可以将黑盒攻击进一步分为基于迁移的黑盒攻击(Transfer-based Black-box Attack)和基于查询的黑盒攻击(Query-based Black-box Attack)。
基于迁移的黑盒攻击:基于迁移的黑盒攻击强调通过增强对抗样本在不同模型上的迁移性(即泛化能力),使得在源模型上生成的对抗样本可以成功攻击目标模型。目前的研究主要是从模型和样本两个角度增强样本的迁移性。从模型的角度,如果一个对抗样本能成功攻击多个不同的源模型,则该样本也更有可能成功攻击目标模型。因此,Liu等人[26]和Li等人[24]提出了一系列有关模型集成的方法。这些方法通过对多个源模型上生成的对抗扰动进行集成,从而提升了对抗样本的迁移性。
..............................
第二章 相关工作
2.1 对抗攻击概述
自Szegedy等人[37]于2014年首次在图像分类任务中发现对抗样本的存在以来,关于如何生成对抗样本(即对抗攻击)的研究一直是对抗性机器学习领域的热点。对于原始样本(????,????????????????????),对抗攻击的目的在于通过算法构建对抗扰动????并将其添加到原始样本????中,从而生成对抗样本????????????????(????????????????=????+????)。这种扰动对于人的肉眼而言很难察觉,但是会使得模型得出错误的分类结果。
为了能够更好地分析生成对抗样本的方法,我们将对抗攻击按照不同的维度进行了分类:
1. 按照生成对抗样本时是否需要用到梯度信息,可以将对抗攻击分为基于梯度的攻击(Gradient-based Attack)和梯度无关的攻击(Gradient-free Attack)。基于梯度的攻击主要利用了输入样本在模型上的梯度信息。具体而言,对于一个样本,我们会将其输入模型进行前向和反向传播从而计算得到损失函数关于样本的梯度,然后将处理后的梯度作为扰动添加到输入样本上。而梯度无关的攻击是在不使用梯度信息的情况下,通过其他方法(比如通过生成式模型直接生成对抗样本[43])构造对抗样本。
2. 按照攻击者是否可以获得目标模型的全部信息,可以将对抗攻击分为白盒攻击(White-box Attack)和黑盒攻击(Black-box Attack)。在白盒攻击的场景下,攻击者可以获得目标模型的全部信息,包括模型的结构和参数以及样本在模型中正向/反向传播的结果,因此攻击者可以利用这些信息直接在目标模型上构建对抗样本。
..........................
2.2 黑盒攻击
如前所述,根据攻击者是否可以获得目标模型的全部信息,我们可以将对抗攻击分为白盒攻击和黑盒攻击。而之所以会有白盒和黑盒的区别,其主要原因有二。第一,在现实场景中,绝大多数深度学习系统并不会给予用户所有的权限。比如对于一些在线图像分类服务(Google Cloud Vision,Clarifai等),当用户上传了图片之后,用户能看到的只有系统对于该图片的若干个最有可能的分类结果。对于攻击者而言,攻击者并不能获取目标模型的内部信息从而构建对抗样本。因此我们才需要将攻击区分为白盒攻击和黑盒攻击。第二,更深入地来说,由于不同的系统中选择的模型和使用的训练集不同,这就导致了不同的系统其模型的决策边界不相同。因此对于攻击者而言,在不能获取目标模型的内部信息的情况下,攻击者不能保证从源模型上构建的对抗样本能够成功跨过目标模型的决策边界从而实现对目标模型的错分。
可以看出,对于白盒攻击我们只需要考虑如何更好地挖掘和使用目标模型的梯度信息即可。但是对于黑盒攻击而言,由于其更贴近于实际,因此也更困难。总之,对黑盒攻击和白盒攻击的研究方向与路径并不相同。目前,关于黑盒攻击的研究大致可以分为基于迁移的黑盒攻击和基于查询的黑盒攻击这两类。
.............................
第三章 基于Mixup 与迁移的黑盒对抗攻击 ................. 12
3.1 引言 ............................... 12
3.2 随机层插值对抗攻击 .......................... 13
第四章 基于Mixup与查询的黑盒对抗攻击 ........................ 27
4.1 引言 ......................... 27
4.2 源模型重训练攻击 ........................ 28
第五章 基于Python的对抗攻击算法库 ...................... 34
5.1 系统架构 ........................................ 34
5.2 算法库模块 ................................ 35
第五章 基于Python的对抗攻击算法库
5.1 系统架构
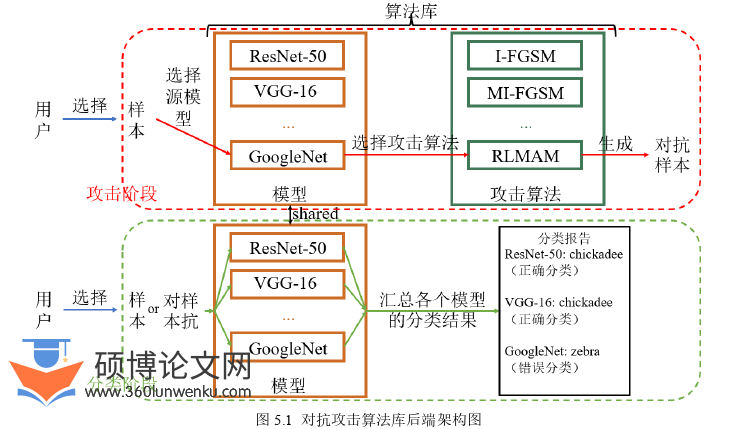
为了能直观展示各种对抗攻击算法生成的对抗样本以及比较它们的效果,我们设计了对抗攻击算法库。该算法库整体分为两个部分:前端图形用户界面与后端系统。本节将具体介绍后端的系统架构。
计算机论文参考
算法库的后端包含两个模块:模型和攻击算法。模型模块包含多种预训练过的模型(ResNet-50,VGG-16和GoogleNet等),攻击算法模块包含多种攻击算法(I-FGSM,MI-FGSM和第三章中提出的RLMAM等)。 后端实现了两个功能:对抗样本的生成和样本的分类。在对抗样本的生成功能中(对应图5.1的红色虚框),后端首先会收到用户上传的样本,随后根据用户的选择在两个模块中选择相应的模型和攻击算法,然后调用相应的算法在源模型上生成对抗样本。在样本的分类功能中(对应图5.1的绿色虚框),后端同样会收到用户上传的样本,随后将该样本分别输入到模型模块的所有模型中并汇总在所有模型的分类结果,最后生成分类报告。
................................
第六章 总结与展望
6.1 本文工作总结
本文中我们主要关注的是黑盒对抗攻击。根据攻击的具体场景不同,我们可以将黑盒攻击分为基于迁移和基于查询的黑盒攻击。我们首先对这两种不同的黑盒攻击中存在的问题进行了讨论:对于基于迁移的黑盒攻击,我们从多个角度探讨了对抗样本在源模型上的过拟合现象对其迁移性的影响。对于基于查询的黑盒攻击,我们具体分析了其中一种源模型重训练方法的缺点。随后我们将Mixup操作与黑盒攻击相结合,分别对上述两种攻击提出了改进的攻击方法。我们的方法充分利用了Mixup操作,在一定程度上解决了之前提到的问题。总的来说,本文的主要工作如下:
(1)对于基于迁移的黑盒攻击,我们提出了随机层插值对抗攻击的方法。我们的方法通过在源模型的不同层次中进行Mixup操作从而提升了输入空间和隐空间的样本复杂度,因此可以获得更多样的梯度信息并最终缓解了对源模型的过拟合现象。除此之外,我们还发现相比于频繁地更新扰动,以粗粒度的方式更新扰动可以获得更好的迁移性。因此我们对传统的动量法进行了优化并提出了内外循环策略。
(2)对于基于查询的黑盒攻击,我们在原始的源模型重训练策略的基础上加入了Mixup操作。针对原始策略中使用的训练集数据较为单一的问题,我们的方法在生成新的训练数据时会通过Mixup操作对其进行增强。我们通过实验表明这样做有助于在决策边界附近生成更多样的样本,从而提升重训练的效果。
(3)除了提出新的攻击方法之外,我们还开发了基于Python的对抗攻击算法库。该算法库实现了一系列对抗攻击算法。在算法库中,我们可以选择不同的源模型以及攻击方法生成各种对抗样本,并查看原始样本和对抗样本在各个模型中的分类结果。
参考文献(略)