
第一章 绪论
1.1 研究背景及意义
随着大数据、云计算、互联网、物联网等一系列新兴技术的快速发展与广泛应用,人类已经进入了一个数据爆炸的大数据时代. 在社会活动、科学研究、移动互联网等诸多领域,数据正以前所未有的速度产生并被广泛收集、存储和处理,呈现出规模大、种类多、增长快等特点. 例如,每一秒,一个大型医院会增加 12 万笔健康数据;每一分钟,YouTube 网站会收到民众上传的总长达 72 小时的视频数据;每一天,一家银行会产生 500 万笔有关信用卡交易的金融数据,时间分秒走过的同时,大量的数据也在快速累积[1]. 大数据蕴含着巨大的价值,为人们更深入地感知、认识和控制物理世界提供了前所未有的丰富信息,在经济、社会、科学研究等方面具有重要的战略意义[2,3]. 例如,通过对微博等网络空间大数据的分析挖掘能够及时反映经济社会动态与情绪,对突发和敏感事件(如流行疾病爆、群体异常)进行预警,协助提高社会公共服务应急能力. 国际著名学术期刊《Nature》和《Science》相继分别出版专刊围绕目前科学研究数据规模的海量增加展开讨论,指出海量数据对科学研究的重要性,标志着大数据已成为科学研究的热点问题之一[4,5].
如何充分挖掘大数据的潜在价值,关系着国防安全和国计民生,已成为国内外产业界、学术界和政府部门的共识. 从应用维度来看,大数据分析挖掘已成为当前信息服务和科学发现的基石;从技术维度来看,大数据分析挖掘是传统数据处理技术的一次变革,是大数据环境下技术和应用发展的必然趋势. 作为一种重要的无监督机器学习方法和大数据信息粒化以及信息压缩的一个基本工具,聚类分析成为了大数据分析和挖掘中的首要任务. 经过半个多世纪的发展,研究者针对不同的应用领域,已经提出了不同的聚类模型和算法,并在图像处理、信息检索、社交网络和生物信息学等领域得到了广泛应用. 然而,近年来,在社会活动、科学研究、移动互联网等诸多领域积累的数据呈现出大规模与复杂性的特征. 具体来讲,数据的大规模性主要体现在样本规模的海量性和特征规模的高维性两个方面;复杂性主要体现在特征表示的混合性、内在结构的复杂性两个方面. 这些特点都将对聚类分析的已有计算模式、理论和方法产生深远的影响,无论从模型、算法还是应用层面,都给聚类分析提出了严峻挑战. 因此,开展大规模复杂数据的聚类分析方法研究,是大规模复杂数据特点对聚类建模的必然要求,具有重要的理论意义与应用价值.
...............................
1.2 聚类分析面临的挑战
聚类分析是指根据一定的相似度准则,将物理或抽象数据对象划分为不同的类的过程,使得同一类内对象之间相似度较大,而不同类的对象之间相似度较小. 经过半个多世纪的发展,聚类分析在理论、方法和应用方面都取得了重要突破,已成为一种重要的智能信息处理技术,其作用日渐重要并得到广泛关注[6–8]. 然而,随着信息技术的不断发展,各个领域积累的数据呈现出样本规模的海量性、特征规模的高维性、特征表示的混合性以及内在结构的复杂性等特点,这些都为传统聚类算法的有效性、时效性以及鲁棒性提出了新的挑战,具体体现在以下几个方面.
(1)如何对大规模数据进行高效聚类
近年来,各个领域的大规模数据频繁出现,对聚类分析的可计算性要求提出了新的挑战[9]. 面对大规模数据,传统的聚类分析算法普遍存在计算效率低、参数确定困难、结果有效性难以保证等问题. 例如,许多聚类算法在小样本数据上能够表现出良好性能,但对大规模数据集进行分析时可能会产生有偏结果. 目前,针对大规模数据聚类,主要从设计复杂度较低算法、对原数据进行采样或压缩降低样本规模两方面进行考虑. 尽管研究者针对该挑战已经开展了一些有益的探索,但是对特定领域大规模数据进行高效聚类,以高效准确地从中获取有价值的、可理解的信息,仍然面临着严峻挑战.
(2)如何对高维数据进行有效聚类
文本数据、基因表达数据、图像数据等高维数据在实际应用领域中广泛存在.如何对其进行有效分析是聚类分析面临的重要挑战[10]. 在高维数据中,由于特征个数过多带来了稀疏性和维度灾难的问题,若直接采用传统聚类算法往往不能得到所期望的结果. 为了更好地进行高维数据的有效聚类,研究者们通常采用特征变换或特征选择的方式对特征空间进行处理,来降低特征维度以提高聚类算法的性能. 另外,在聚类过程中不同的特征对类形成的贡献不同,因此,特征加权或子空间也是两种重要的高维数据处理技术. 但是,在处理混合型高维数据时,如何更好地为各个特征分配权重仍是一个难以解决的问题.
..............................
第二章 基于分层抽样的大规模数据聚类算法
2.1 引言
随着云计算、物联网和社交网络等信息技术的迅猛发展,数据在规模上呈现出前所未有的快速增长趋势,大数据时代已经来临[3]. 大规模数据的分析挖掘已成为当今学术界和企业界面临的一个重要而富有挑战性的任务. 作为数据挖掘中一种重要的数据预处理工具,聚类分析在大数据时代变得尤为重要. 然而,传统聚类分析算法由于计算效率较低不能直接应用于大规模数据. 因此,如何在保证聚类质量的同时提高计算效率成为了大规模数据聚类分析面临的挑战.
抽样技术作为一种高效的数据约简方法,在大规模数据聚类分析中得到了广泛应用. 基于抽样技术的大规模聚类算法框架如图2.1所示. 具体来讲,该框架主要包括以下步骤:(1)运用抽样技术从原始大规模数据中抽取一部分对象作为代表样本;(2)利用传统聚类分析算法在代表样本集上得到部分聚类结果;(3)采用数据标签技术,根据部分聚类结果获得整个数据集的完整聚类结果. 基于抽样的大规模数据聚类算法的关键在于如何设计一个合理的抽样方案进而选取合适的代表性样本,使得代表性样本的分布尽可能地保持原始数据的分布特征. 为了达到这一目的,近年来研究者已经提出了一系列基于抽样的大规模数据聚类算法. 根据抽样方案的不同,已有研究主要分为基于均匀随机抽样、渐进式抽样、有偏抽样和分层抽样 4类方法.
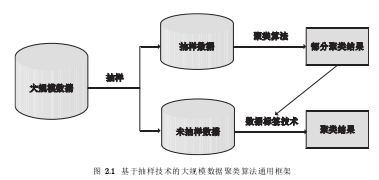
...........................
2.2 基于分层抽样的大规模数据聚类算法
本节提出了一个基于分层抽样的聚类算法 SSEFCM,主要目的在于保持聚类效果的前提下提高计算效率. 首先描述了大规模数据分层抽样过程,接着叙述了相应的数据标签技术,最后给出了算法描述并对时间复杂度进行了讨论.
2.2.1 分层抽样
在分层抽样中,首先根据一定的准则将数据对象分成相对同质(同一层内对象相似度较大)的层,然后从每一层中分别选择一部分样本组成代表性样本子集[55].作为一个常用的大规模数据分析技术,分层抽样主要包括分层和样本分配两个关键步骤. 在分层过程中,原始大规模数据集被划分为不同的层;在样本分配过程中,需要确定样本子集大小并从每一层中抽取相应的样本. 两个过程分别描述如下.
在分层抽样中,首先根据一定的准则将数据对象分成相对同质(同一层内对象相似度较大)的层,然后从每一层中分别选择一部分样本组成代表性样本子集[55].作为一个常用的大规模数据分析技术,分层抽样主要包括分层和样本分配两个关键步骤. 在分层过程中,原始大规模数据集被划分为不同的层;在样本分配过程中,需要确定样本子集大小并从每一层中抽取相应的样本. 两个过程分别描述如下.
2.2.1.1 分层方案
为了在聚类分析中使用分层抽样技术,大规模数据首先需要划分为一些独立的层,同一层内数据对象需要尽可能相似. 众所周知,聚类分析是一类典型的无监督机器学习方法. 也就是说,聚类分析的数据对象事先是没有任何标签信息. 对大规模数据聚类分析来说,利用分层抽样的困难在于如何找到一个近似分层变量可以对数据集进行分层. 因此,需要使用一种简单而高效的技术达到此目的.
局部敏感哈希 (LSH,Locality-sensitive hashing)[57]是一个随机化算法,由于其在计算效率和准确性方面的优越性能,目前已经在不同领域得到了广泛应用[58].与计算机科学中传统的哈希算法不同,局部敏感哈希方法主要目的是在原始空间最大化相似对象冲突的概率. 其基本思想是使用一组哈希函数使得相似对象以高概率放到同一桶中,而不相似对象以低概率放到同一桶中. 因此,由于其有效的邻近保持特性和高效性,本章采用 LSH 方法对大规模数据进行数据分层.
..............................
第三章 基于信息熵的混合数据软子空间聚类算法 . . . . . . . . . . . . . . . . . 29
为了在聚类分析中使用分层抽样技术,大规模数据首先需要划分为一些独立的层,同一层内数据对象需要尽可能相似. 众所周知,聚类分析是一类典型的无监督机器学习方法. 也就是说,聚类分析的数据对象事先是没有任何标签信息. 对大规模数据聚类分析来说,利用分层抽样的困难在于如何找到一个近似分层变量可以对数据集进行分层. 因此,需要使用一种简单而高效的技术达到此目的.
局部敏感哈希 (LSH,Locality-sensitive hashing)[57]是一个随机化算法,由于其在计算效率和准确性方面的优越性能,目前已经在不同领域得到了广泛应用[58].与计算机科学中传统的哈希算法不同,局部敏感哈希方法主要目的是在原始空间最大化相似对象冲突的概率. 其基本思想是使用一组哈希函数使得相似对象以高概率放到同一桶中,而不相似对象以低概率放到同一桶中. 因此,由于其有效的邻近保持特性和高效性,本章采用 LSH 方法对大规模数据进行数据分层.
..............................
第三章 基于信息熵的混合数据软子空间聚类算法 . . . . . . . . . . . . . . . . . 29
3.2 基于信息熵的混合数据软子空间聚类算法 . . . . . . . . . . . . . . . . . 31
第四章 基于序列化的混合数据基聚类生成算法 . . . . . . . . . . . . . . . . . . 43
4.1 引言 . . . . . . . . . . . . . 43
4.2 基于序列化的混合数据基聚类生成算法 . . . . . . . . . . . . . . . . . . 45
第五章 基于有效性指标的分类型数据聚类集成选择算法 . . . . . . . . . . . . . 59
5.1 引言 . . . . . . . . . . . . . 59
5.2 基于有效性指标的分类型数据聚类集成选择算法 . . . . . . . . . . . . . 60
第七章 基于社交网络聚类的社会化推荐算法
7.1 引言
随着移动互联网、社会化媒体等技术的快速发展与应用,推荐系统已经渗透到人们的日常生活中. 目前,推荐系统已经在电子商务、娱乐网站、在线广告、社交网站、新闻网站、服务推荐等领域得到了广泛应用,在给运营商带来商业利益的同时,也给用户带来了诸多便利和个性化体验[132,133].
近年来,研究者根据不同的需求提出了一系列推荐算法,主要包括协同过滤推荐算法、基于内容的推荐算法以及混合推荐算法等. 其中,协同过滤推荐算法具有易实现、跨领域等诸多优势,现已成为发展最快、应用最广的一类推荐算法[134]. 随着互联网规模的快速发展,协同过滤推荐算法在实际应用中面临着数据稀疏、可扩展性等问题[135]
为了解决以上问题,研究者已开展了一些探索性工作. 其中,为了缓解协同过滤推荐中的稀疏性,冷亚军等人[136] 提出了两阶段最近邻选择算法,首先找到用户近邻倾向性高的集合,然后计算他们之间的等价关系,得到最终的最近邻集合,有效提高了近邻搜寻的准确性. Wang 等人[137]通过相似用户对相似物品的评分进行预测,避免了单一协同过滤方法中邻居数量不足的问题,在一定程度上缓解了稀疏性. Liang 等人[138]利用联合聚类方法,将原始评分矩阵进行聚类,并将类别相似性和传统评分相似性进行融合,有效缓解了传统相似性计算不准确的问题. Koren 等人[139] 则将原始稀疏评分矩阵分解为低维稠密的潜因子矩阵,解决了协同过滤算法对数据稀疏性敏感的问题. 针对计算可扩展性问题,Zeng 等人[140]认为推荐系统中用户的贡献度是有区别的,将贡献度最大的 20% 的用户组成核心用户群,就可以达到利用全部用户 90% 的推荐精度. Cai 等人[141]则采用降维的思想,利用物品的类别属性信息以及评分信息,将用户映射为对应类别的用户群,从而将用户特征向量从高维空间转化为低维空间,从而大大降低了算法执行时间. Xu 等人[142]利用聚类分析技术将用户和物品分别划分为一些相似的类,将传统协同过滤算法中的相关计算转变为类内部进行,降低了计算的规模,从而缩短算法的运行时间,有效提升了推荐结果的精度.
.............................
第八章 总结与展望
大数据时代,大规模复杂数据的聚类分析是一个富有挑战的研究课题. 本文针对数据的大规模性、高维性、混合性和复杂性等特点,采用抽样、子空间加权、集成聚类、图压缩等方法与技术系统地开展了聚类分析模型与算法的研究. 具体地,本文取得的研究成果总结如下:
大数据时代,大规模复杂数据的聚类分析是一个富有挑战的研究课题. 本文针对数据的大规模性、高维性、混合性和复杂性等特点,采用抽样、子空间加权、集成聚类、图压缩等方法与技术系统地开展了聚类分析模型与算法的研究. 具体地,本文取得的研究成果总结如下:
(1)针对大规模数据聚类算法面临的计算效率低下的问题,提出了一个基于分层抽样的聚类算法框架. 与其他大多数基于抽样的聚类算法相比,提出的算法在抽样过程中考虑了数据集的分布信息. 一个包含大量数据对象或方差很大的数据层应该被采样更多的对象来表示原始数据,这种差异有利于产生更具代表性的样本子集和更好的部分聚类结果. 实验表明,与已有基于抽样的大规模数据聚类算法相比,提出的算法在聚类结果的有效性和计算效率方面均具有明显提升.
(2)针对混合型高维数据聚类的有效性问题,提出了一种高维混合数据软子空间聚类算法. 该算法通过融合 Renyi 熵和互补熵,构建了混合数据类分布度量机制,实现了对类结构的类内、类间的不确定性度量. 该算法克服了已有加权算法仅依据数据集总体分布或类内散度进行加权的缺陷,而且技巧性地避免了在可测特征空间和非可测特征空间上对类结构进行有效度量这一难题. 实验表明,提出算法的有效性优于已有加权聚类算法.
(3)针对聚类集成中基聚类质量以及他们之间的差异性问题,提出了一种基于信息熵的混合数据基聚类生成算法. 该算法针对数值型数据和分类型数据分别利用微分熵和互补熵构建了统一的聚类结果有效性准则. 基于该准则和归一化互信息,建立了生成聚类质量高、差异性强的基聚类成员的有效机制. 实验表明,提出算法在有效性方面优于其他基聚类生成方法.
参考文献(略)