1 绪论
1.1 研究背景及意义
基因是决定生命健康的内在因素并具有重要的生物意义。如必需基因[1],是细胞生命活动不可缺少的基因,一旦缺少会影响生命健康,甚至会导致死亡;又如致病基因[2],是与疾病发生、发展、诊疗相关的基因,当这类基因发生突变时,生物更容易患上某种疾病。不论是必需基因还是致病基因都对生物的生命活动产生重要的影响,因此对这些基因的研究对于疾病的预防和药物靶标的设计具有重要的意义。
对这些有生物意义的基因的鉴定有两种方法。第一种方法是实验技术,如基因敲除技术[3],通过使特定基因的功能丧失作用,观察生物体的生命活动是否出现异常,进而推测出该基因的生物功能。实验技术昂贵且耗时,而且并不适用于所有生物体。第二种方法是生物信息学计算方法,通过基于生物网络的计算方法来分析基因的重要性。与实验技术相比,计算方法更高效,也更便宜。随着高通量技术的发展,可以很容易获得大量的基因交互数据和表达数据,从而构建各类生物网络。因此,如何从生物网络中识别这些基因成为了研究的热点
复杂网络的发展为生物基因的研究提供了新的思路。一个生物系统可以建模为一个复杂网络。以基因调控网络为例,最常用的网络建模为有向图。网络中的节点代表基因,节点之间的有向边代表基因间的调控关系。在计算方法上,大量基于复杂网络拓扑结构的方法已经被广泛研究[4-8]。这些方法大多通过度量网络节点的中心性来识别重要基因。最典型的是度中心性方法[4],一个节点的度中心性被定义为与之直接相连的节点的个数,根据中心性致命性规则[9-11],基因的度越大认为该基因越重要。据此对网络中的基因进行排序,排名靠前的基因作为候选基因。
.............................
1.2 国内外研究现状
从真实系统中抽象得到的复杂网络具有很多复杂的特性,小世界特性[18]和无标度特性[19]的发现受到了国内外不同领域的研究人员的广泛关注。但是由于复杂网络的大规模性,复杂网络的控制问题仍然是一个难题。下面从复杂网络的可控性和复杂网络的可控性应用两方面介绍相关的研究进展和研究成果。
1.2.1 复杂网络的可控性研究
复杂网络是从真实系统中抽象得到的一类具有复杂拓扑结构的网络模型。根据控制理论,如果在合适的输入信号下,系统可以在有限的时间内从任何初始状态驱动到任何期望的最终状态,那么动态系统是可控的[20,21]。现实世界的真实系统大多是非线性系统,但非线性关系很难被刻画,因此一般研究的是线性系统的控制问题。对于线性时不变系统,其典型的动力学方程为

..............................
2 可控性节点分类框架的构建
2.1 结构可控性基本原理
2.1.1 结构可控性定理

...............................
2.2 基于可控性的节点和边分类
根据 Liu 等[12]人建立的复杂网络结构可控性模型,我们已经知道可以通过最小驱动节点集来控制整个网络,并且知道如何求解控制一个网络所需的最小驱动节点集。本节基于该模型,介绍了三种不同的网络节点分类方法和一种网络边分类方法。
2.2.1 基于可控性的节点分类方法
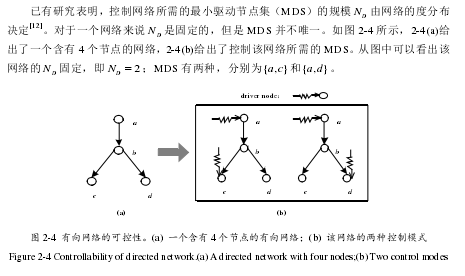
.............................
3 组织特异调控网络中致病基因的识别 ........................................ 19
3.1 相关生物数据 ................................... 201.2 国内外研究现状
从真实系统中抽象得到的复杂网络具有很多复杂的特性,小世界特性[18]和无标度特性[19]的发现受到了国内外不同领域的研究人员的广泛关注。但是由于复杂网络的大规模性,复杂网络的控制问题仍然是一个难题。下面从复杂网络的可控性和复杂网络的可控性应用两方面介绍相关的研究进展和研究成果。
1.2.1 复杂网络的可控性研究
复杂网络是从真实系统中抽象得到的一类具有复杂拓扑结构的网络模型。根据控制理论,如果在合适的输入信号下,系统可以在有限的时间内从任何初始状态驱动到任何期望的最终状态,那么动态系统是可控的[20,21]。现实世界的真实系统大多是非线性系统,但非线性关系很难被刻画,因此一般研究的是线性系统的控制问题。对于线性时不变系统,其典型的动力学方程为
..............................
2 可控性节点分类框架的构建
2.1 结构可控性基本原理
2.1.1 结构可控性定理
...............................
2.2 基于可控性的节点和边分类
根据 Liu 等[12]人建立的复杂网络结构可控性模型,我们已经知道可以通过最小驱动节点集来控制整个网络,并且知道如何求解控制一个网络所需的最小驱动节点集。本节基于该模型,介绍了三种不同的网络节点分类方法和一种网络边分类方法。
2.2.1 基于可控性的节点分类方法
.............................
3 组织特异调控网络中致病基因的识别 ........................................ 19
3.1.1 组织特异调控网络 .............................. 20
3.1.2 蛋白质相互作用网络 ...................................... 23
4 致病基因识别在疾病关系分析中的应用 ........................... 35
4.1 实验数据的人工标注 ....................................... 35
4.2 疾病特异基因的识别 ............................ 37
5 总结和展望 ..................... 43
5.1 总结 ................................... 43
5.2 展望 .................................... 43
4 致病基因识别在疾病关系分析中的应用
4.1 实验数据的人工标记
现有的人体组织网络有 32 个,疾病模块有 299 个,每个疾病模块包含一组基因。通过考虑疾病与某一组织相关,将疾病划分到组织上。本文根据 NCBI 网站的 MESH 数据库中的树形结构(tree structure)来确定疾病所属组织。MESH 数据库提供相关参照帮助检索者从一个主题词去参考其他有关的主题词,并且将这些主题词按照词义范围不同划分层次关系。以阿尔兹海默症(Alzheimer Disease)为例,在 MESH 数据库中输入该疾病的英文名,得到其树形结构,如图 4-1 所示。

从图 4-1 中可以看出,阿尔兹海默症的直接上位词是痴呆(Dementia),但痴呆不是人体组织。痴呆的上位词为脑部疾病(Brain Diseases),因此将阿尔兹海默症划分为脑部疾病。对每种疾病在 MESH 数据库中进行搜索,最终将 109 种疾病与 22 个组织关联起来。在 32 个组织中,有 22 个组织上有相关的疾病数据,剩下 10 个组织没有对应的疾病。造成这种结果的原因之一是本身组织网络数据并不囊括所有的人体组织,所以有些疾病不属于这 32 个组织中的任何一个;二是疾病数据数量有限,而且原始数据中有些是重复的数据。
......................
5 总结和展望
5.1 总结
本文基于三种节点分类方法和一种基于边分类方法,将网络中每个节点的类型表示成一个四维向量,每个分量代表一种分类方法。从而形成新的可控性节点分类框架。并将该框架应用到 32 个组织特异调控网络上,通过统计显著性实验找出了具有广泛生物意义的一类基因。并通过进一步的实验验证了这类基因与疾病具有相关性,很可能是潜在的致病基因。主要的工作如下:
(1)为了便于实验的分析和验证,对各类数据集进行了预处理,其中包括网络数据的集成、基因名的 ID 映射和邻接矩阵的生成等。
(2)研究了复杂网络的结构可控性理论和相关的控制方法。根据结构可控性理论,提出了本文研究方法,即可控性节点分类框架。将可控性节点分类框架应用于人体组织特异的调控网络,在金标准数据集上做了统计显著性分析,实验结果表明其中一类基因具有广泛且一致的生物意义,并将其定义为候选疾病基因;
(1)为了便于实验的分析和验证,对各类数据集进行了预处理,其中包括网络数据的集成、基因名的 ID 映射和邻接矩阵的生成等。
(2)研究了复杂网络的结构可控性理论和相关的控制方法。根据结构可控性理论,提出了本文研究方法,即可控性节点分类框架。将可控性节点分类框架应用于人体组织特异的调控网络,在金标准数据集上做了统计显著性分析,实验结果表明其中一类基因具有广泛且一致的生物意义,并将其定义为候选疾病基因;
(3)进一步研究了候选疾病基因与疾病的关系,设计相关性度量,以从候选疾病基因中筛选出疾病特异基因;在 22 个组织和 109 种疾病上验证了疾病特异基因的组织特异性;在前脑组织和心脏组织上做了文献挖掘和 GO 条目验证,实验结果表明这类基因很可能是潜在致病基因。
参考文献(略)
参考文献(略)