本文是一篇计算机论文,本文提出了基于H-TD3的模块化机器人运动优化方法,对机器人探索过程中的失败经验重新标注,并将其作为成功经验加入到经验池中,加速任务学习过程,从失败中学习,提高了运动策略优化过程的样本利用率;
第1章 绪论
1.1 研究背景
随着民用、军用和太空探索等领域对智能化机器人的需求日益提升,人工智能和机器人技术的飞速发展和深度融合,机器人在非结构化场景(如太空探索、地质勘查等领域)下的应用需求逐渐增多,如图1.1所示。非结构化环境地貌复杂、表面障碍物无明显规则,要求机器人具有对不同环境与任务的高适应性、具备更多样的功能以及失效情况下的自检与自修能力。功能单一、结构固定的传统机器人在复杂的非结构化环境下任务处理能力有限,大部分情况下无法完成多样化任务。因此,探索并开发面向非结构化环境的新型机器人具有重大的科研意义与工程价值。

计算机论文怎么写
模块化机器人系统由一系列基本模块单元构成,可通过构型重组的方式实现不同的运动模式。相比于传统机器人,有着可重构性、自适应性和可扩展性等诸多优点。在非结构环境下,相同数量的模块可通过不同的连接方式适应多种场景,比如蛇形构型机器人可通过狭窄的通道、四足机器人可在平整地面快速移动等。
.................................
1.2 研究现状
当前国内外对模块化机器人的研究主要集中在模块化机器人重构规划方法上,而对环境因素很少考虑,对应的仿真实验平台的研究与开发尚处于起步阶段。接下来本文将对模块化机器人重构规划方法、移动机器人环境感知方法以及仿真实验平台研究现状进行调研与阐述。
1.2.1 模块化机器人重构规划方法现状
当前的重构规划方法研究主要集中在模块化机器人构型设计、运动控制优化算法上。模块化机器人具有多种分类标准[1],比如根据模块化机器人模块连接方式的不同,可将其归类为链式机器人、移动机器人、晶格式机器人以及混合式机器人等类型;根据单元模块重构方式的不同,模块化机器人可以分为随机性重构系统和确定性重构系统;
(1) 构型优化现状
首先是构型上的优化,即设计一个能够完成当前任务的完整机器人构型。构型表达上有多种表达方式,燕山大学陈江业[6]采用二进制编码方式对机器人构型进行表示,结合多目标遗传算法NSGA-II[7]对模块化机器人进行构型上的优化,优化变量包括机器人的模块数量及装配方式,基于模块化机械臂机器人在搬运任务中验证了其算法正确性。华南理工大学吴文强[8]采用有向图进行模块化机器人的构型表示,同样采用NSGA-II结合二进制编码对串联机器人的构型进行了优化,并进一步在固定构型上进行了尺度优化,即使用全局优化算法搜索合适的连杆长度与连杆偏距。
(2)运动策略优化现状
模块化机器人的运动策略优化问题,早期在运动优化问题上主要以节律运动控制器结合参数搜索方式为主,即优化变量主要包括运动控制器中的一些参数,比如哈尔滨工业大学王晓露[9]基于粒子群搜索算法对正弦发生器中的震荡幅值以及震荡相位等超参数进行搜索优化。然而随着深度强化学习方法的兴起,由于其无模型、环境特征提取能力强等特点,可以优化学习整个运动控制器。哈尔滨工业大学赵传武[10]基于强化学习中的Q-learning[11]方法以及Sarsa[12]方法,对于自行设计的模块化机器人在迷宫环境以及深井环境中进行了运动优化学习。2018年Kim[13]等人针对Snapbot[14]腿式机器人的固定构型,结合深度强化学习算法中的信任区域策略优化方法,训练划船和爬网动作的策略网络,以上研究均验证了强化学习方法对提升模块化机器人自主决策能力的有效性。
.........................
第2章 基于深度强化学习的运动优化方法
2.1 引言
模块化机器人的运动优化研究通常基于已知的节律运动模型,如正弦发生器等运动控制模型,再结合基于参数搜索的方法进行优化。随着深度强化学习方法的发展,可以实现对模块化机器人无模型的运动优化问题求解,并且深度神经网络对于特征的强大提取能力有助于提高模块化机器人在不同环境下的自主规划能力。采用深度强化学习方法能够提高模块化机器人的自主决策能力,然而由于运动优化问题的复杂性,现有主流深度强化学习方法在机器人运动优化问题上仍无法有效利用失败的经验,存在学习效率低下等问题,为此本文提出一种结合事后经验重放机制的TD3深度强化学习方法H-TD3,使模块化机器人能够从失败经验中学习,从而提高经验的利用率。
本节以此为出发点,首先介绍了深度强化学习相关理论;然后对本文所采用的模块化机器人系统进行了详细说明;并对模块化机器人运动优化任务进行了形式化的描述;介绍了基于H-TD3的模块化机器人运动优化任务设计,包括结合事后经验重放机制对原有TD3算法的改进、强化学习环境搭建以及相关要素设计等内容,从而实现对模块化机器人运动优化问题的高效求解。
............................
2.2 相关理论
本节关于相关理论知识的阐述将从两部分内容依次展开:一是结合深度学习的深度强化学习方法,二是深度强化学习中具有代表性、能够较好解决运动控制优化问题的TD3算法。
2.2.1 深度强化学习
强化学习是机器学习领域中比较重要的一类方法,强化学习方法中主要包括两个基本元素:智能体以及环境。智能体通过不断与环境进行交互,致力于学习一种能够最大化预期奖励总和的策略,整个强化学习的学习流程可以表示为一个马尔可夫决策过程。
传统强化学习方法比如Q-learning中,状态转移对1 1(,,,,)t t t t tS A R S A以及状态动作价值函数一般采用表格方式记录存储,在大型强化学习任务中存在索引效率低下,存储空间巨大等问题,人们在后来的研究中引入深度神经网络拟合状态动作价值函数或者策略函数,从而支持对复杂度更高、状态更加丰富的强化学习问题进行优化,该类强化学习方法又称深度强化学习方法,比如深度Q网络及其变体Double DQN和Dueling DQN,以及下文即将介绍的TD3(Twin Delayed Deep Deterministic Policy Gradient)算法等,其中TD3算法又称孪生延迟DDPG算法。
2.2.2 TD3算法
TD3算法基于前面提到的Actor-Critic架构,算法流程图如图2.2所示。其在DDPG方法的基础上通过引入两个Q值网络进行值估计从而计算TD误差引导网络更新,改善了原DDPG方法中针对超参数敏感、学习不稳定的问题,可以更加有效解决高维连续动作空间下的优化问题,因此本文接下来将基于TD3方法进行进一步研究与改进。
.............................
第3章 基于演化计算的构型-运动协同优化方法 ...................... 29
3.1 引言.................................... 29
3.2 问题描述 ........................... 29
第4章 WeVolve仿真实验平台设计与开发 ..................... 42
4.1 引言................................... 42
4.2 机器人模型构建 .............................. 43
第5章 仿真实验结果及分析 ............................. 57
5.1 基于深度强化学习的运动优化仿真实验 ................57
5.1.1 实验设计 ........................... 57
5.1.2 实验结果及分析 ................... 59
第5章 仿真实验结果及分析
5.1 基于深度强化学习的运动优化仿真实验
在第2章中本文提出了基于深度强化学习的运动优化方法,在学习过程中通过对前期探索过程中的失败经验重新标注,增加经验池中成功经验的比例,从而解决机器人运动优化过程中经验样本利用率低的问题,为此本节接下来在仿真环境中进行了相应实验,验证H-TD3算法在模块化机器人运动优化任务中的有效性以及事后经验重放机制的优越性。
5.1.1 实验设计
本文在2.4.3节中介绍的竞速与避障两个场景下分别进行TD3算法、H-TD3算法的对比实验,同时为了验证HER机制的通用性,仍在相应场景上进行了DDPG算法与H-DDPG算法的实验,下面介绍其它具体设置。
仿真参数设置:Webots仿真器中每个离散仿真时间步长在现实世界中是0.1秒,为了防止决策频率太快并同时保证仿真的准确性,在环境中设置FrameSkip参数为10,即每次决策之后重复执行相同的动作10次,故每回合的仿真时长为50秒,训练时采取加速仿真模式,能够以现实生活中平均60倍的速度进行仿真。
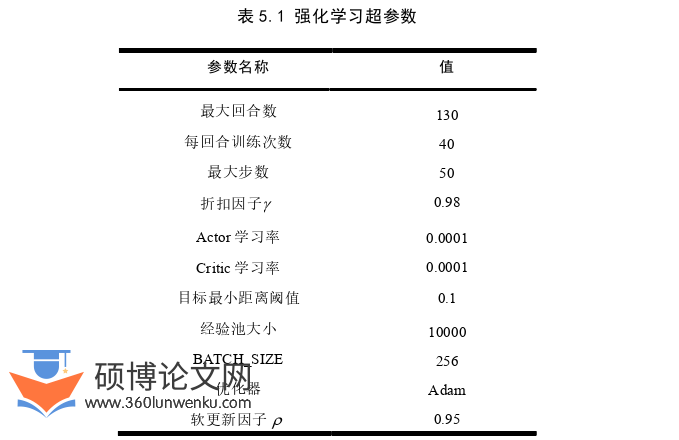
计算机论文参考
...............................
第6章 工作总结与展望
6.1 论文工作总结
本文针对模块化机器人在复杂的非结构化环境下的应用需求,结合现有研究现状中存在的不足,总结提炼出三个方面的待解决问题。一是目前基于深度强化学习方法的运动优化的研究中,未对失败经验充分利用,二是基于演化计算方法的协同优化的研究中,未考虑环境先验信息,对环境、构型和运动三方面耦合优化的方法仍然不足,三是已有的模块化机器人仿真实验平台存在可扩展性差、仿真效率低等问题。针对上述问题,本文首先提出了基于H-TD3的运动优化算法以及基于结合地形先验的协同演化算法,设计并开发了WeVolve仿真实验平台,支持模块化机器人仿真任务的快速搭建、运动优化任务以及协同优化任务的求解,最终通过仿真实验证明了上述算法及实验平台的有效性,为复杂的非结构化环境下的任务提供了新的解决思路。本文主要完成的工作如下:
(1)提出了基于H-TD3的模块化机器人运动优化方法,对机器人探索过程中的失败经验重新标注,并将其作为成功经验加入到经验池中,加速任务学习过程,从失败中学习,提高了运动策略优化过程的样本利用率;
(2)提出了基于结合地形先验的演化计算方法的协同优化方法,利用语义分割进行了对复杂地形表面图像的处理与分析,将提取到的地形语义信息结合标准演化计算方法,提高了模块化机器人在非结构化环境下的协同优化效率;
(3)设计并开发了WeVolve仿真实验平台,支持复杂仿真环境的搭建以及模块化机器人运动优化、协同优化任务的求解,并对部署过程进行了详细描述,能够快速搭建复杂仿真环境,为有序、高效开展仿真实验提供了有力支撑;
参考文献(略)