本文是一篇计算机论文,本文研究内容主要是针对收集到的个体医疗体检数据进行糖尿病预测,通过糖尿病预测系统,方便个人通过机器学习模型预测结果初步了解自己的患病情况,糖尿病预测系统还可辅助医生进行诊断,节省医疗资源,降低医生的误诊、漏诊情况的发生,其预测结果可供医生进行参考和分析,为下一步的治疗方案提供方向。
第 1 章 绪论
1.1 引言
我国人口众多,医疗资源紧缺,传统的糖尿病管理模式难以满足需求。糖尿病的治疗特点是越早对其进行干预,患者的并发症发病期越晚,因此,通过糖尿病预测系统辅助医生诊断并帮助个人进行健康管理,能够有效的缓解我国医疗资源紧缺状况,减轻社会负担,帮助患者尽早的对糖尿病进行干预,能有效的阻止糖尿病恶化。医疗数据的大量产生为机器学习在医疗领域的发展奠定了基础[1],通过处理这些真实应用场景下产生的医疗数据并对其进行深入分析,从中提取出超集的信息[2] ,构建机器学习模型,实现对糖尿病的预测。因此,糖尿病预测系统的研究具有重大的现实意义。医疗问题的解决是一项关系我国 14 亿人口的重大民生课题[24],其中精准医疗已上升为国家战略。人类基因组测序技术、生物医学分析技术、基因芯片、体外诊断以及大数据技术的日新月异为精准医疗的技术现代化奠定了基础[25],通过人工智能和传统医学相结合,以一种全新视角来探究疾病的发展和影响因素,这也成为了精准医疗的主要实现手段。
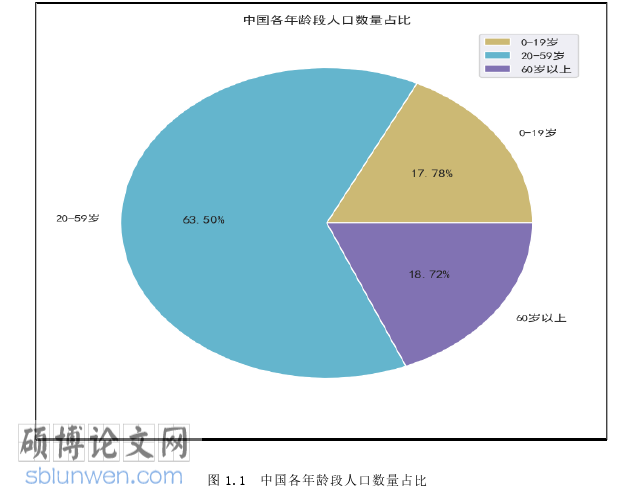
糖尿病(Diabetes Mellitus,DM)常常被称之为"不死的癌症"[26]。这是一种胰岛细胞分泌胰岛素功能异常而导致身体的生理代谢功能紊乱的疾病,以高血糖为特征。随着糖尿病病程的延长,如果不对其加以控制,会产生多种其他器官的并发症,后果不堪设想。截至 2020 年,我国糖尿病患者超过 1 亿[27],其中有6130 万人未确诊,占比高达 53.6%。2020 年中国各年龄段人口占比如图 1.1 所示:
计算机论文怎么写
...............................
1.2 国内外糖尿病预测系统研究现状
1.2.1 国外糖尿病预测方法研究现状
早在十八世纪中期,就有国外学者对糖尿病进行研究。Matthew Dobson[3]首次证实糖尿病为一种慢性疾病,但仍具有致命性。通过查阅文献,糖尿病的研究集中在构建筛查模型、影响糖尿病发病因子的评估模型以及糖尿病患者产生并发症的概率模型几个方面进行。
国外早期对糖尿病风险评估模型的构建主要以统计学为基础,例如逻辑回归、多元回归以及 Cox 回归等方法。如今,大数据及人工智能技术的发展使机器学习更多的被应用于糖尿病研究。例如,Layla Parast 等人[4]构建了一种动态预测模型来评估 2 型糖尿病的发病风险。 Joung-Won Lee 等人[5]探讨了空腹血糖和血脂对糖尿病风险预测模型的影响程度。Jeyalatha 等人[6]采用 J48 决策树算法以及朴素贝叶斯算法构建分类器,使用皮马印第安糖尿病数据集,其预测准确率分别达到 74.8%和 79.5%。 Rodriguez-Romero 等人[7]用逻辑回归预测糖尿病和肾病,虽然模型在训练数据上表现优异,但是其泛化能力较弱。Rahman Ali[8]提出了 H2RM 混合粗糙集推理模型,提高了模型的可解释能力,改善了预测不准确的问题。单一学习器的泛化性和稳定性表现往往不尽如人意,因此,研究人员考虑到将多个学习器以某一种设定好的策略进行组合,构建集成模型,进而提升模型解决问题的能力。据相关文献显示,集成学习的方式最先在分类问题上进行使用,之后也被应用在回归和聚类等问题上[9]。例如,Anjali等[10]采用AdaBoost 算法集成决策树、支持向量机等弱分类器,使用决策残差得到的准确率达到 80.72%。 Kumar 等人[11]针对医疗数据特点,利用高斯过程的分类,使用线性、多项式和径向核的分类方法,最终准确率达到 81.97%。Rahman 等人[12]对处理过缺失值和异常值的 Piuma 糖尿病数据集进行特征提取,得出随机森林的准确率达到了 92.26%,灵敏度达到了 95.96%,特异度达到了 79.72%。近些年,融合模型在 Kaggle 比赛上大放异彩,越来越多的融合模型用来处理糖尿病的预测问题[13]
.............................
第 2 章 基于 Django 框架及机器学习的系统开发理论与技术
2.1 机器学习相关技术
2.1.1 Scikit-learn 库
Scikit-learn 是一个机器学习工具包,基于 Python 语言,可调用 NumPy 基础科学计算库、SciPy 科学计算工具包、Pandas 数据分析工具和 Matplotlib 图表绘制工具等 Python 数值计算的库对数据进行高效的算法处理,而且涵盖大量的数据集以及封装了主流机器学习算法。在导入算法时,只需要调用对应的接口,设置并调节对应的参数,即可完成回归、分类、聚类、降维等常用的机器学习模型的构建,大大提升了机器学习的开发效率。
2.1.2 Jupyter Notebook
Jupyter Notebook 是基于 Web 网页的程序,可将用户编写的可视化内容以文档的形式整理到一起进行展示。其最突出的特点是可在网页的页面中直接使用编程语言编写代码并运行代码,能够在代码块下方直接看到运行结果,大大提高开发效率。
................................
2.2 决策树理论
决策树是一种非参数的有监督学习方法[38]。常用来解决分类和回归任务,它能够以树形结构表现从数据集中归纳的决策规则。决策树算法可对决策规则进行可视化分析,便于解释以及在处理不同类别数据时速度快。因此,在以树模型为核心的领域的应用更普遍[39]。
决策树可以看成由若干个节点组成,其中,根节点存放决策树中所有的样本数据,每个子节点存放一定数量的样本,通过不纯度指标来衡量其是否为最优树。决策树划分的目的就是使不纯度达到最低,以追求更好的拟合效果[40]。常见的 ID3、CART 等算法对于追求最优分支的核心是一致的,大多数都是围绕在对某个不纯度相关指标的最优化上[41]。
Hansen 和 Salamon[43]在研究神经网络算法的过程中,偶然发现一种现象,即多组神经网络共同决策的效果要比任意单个的神经网络的效果具有优越性,一般认为这是集成学习思想的起源。这个意外得到的结果也成为了集成学习发展的推动力。针对某些单一学习器要么过拟合,要么欠拟合,有的甚至预测性能弱、精度差等等缺点,集成学习是一个取长补短,通力合作的过程,具体的方法就是将有差异的基学习器使用某种策略整合在一起,旨在训练出一个相对稳定且可靠的强学习器。其成功在于保证了基学习器多样性的同时,通过综合若干个基学习器的预测效果,能够明显的提升模型的预测效果[44]。集成学习在许多著名的机器学习比赛,如 Netflix、KDD2009、Kaggle 等数据竞赛中可谓是大放异彩,因其较好的稳定性、准确性和泛化能力取得了不错的名次,近些年,集成学习在医疗领域的应用中也不断被推广,常用来预测疾病的患病风险以及患病者的易感性。
............................
第 3 章 糖尿病原始数据的预处理与特征选择 ................ 19
3.1 糖尿病数据集的来源及介绍 ................................. 19
3.2 糖尿病原始数据集预处理 ................................... 20
第 4 章 XAR-Stacking 融合模型............................ 31
4.1 现有模型的分析 ............................... 31
4.1.1 基于决策树和随机森林糖尿病预测模型的构建与分析 ................. 31
4.1.2 基于 AdaBoost 糖尿病预测模型的构建与分析 ........................ 36
第 5 章 基于 Django 框架的糖尿病预测系统的设计与实现 ..... 46
5.1 糖尿病管理模式分析及改进构想 ............................. 46
5.1.1 传统糖尿病管理模式及优劣性分析 ................................. 46
5.1.2 糖尿病管理模式的改进构想及优势 ................................. 48
第 5 章 基于 Django 框架的糖尿病预测系统的设计与实现
5.1 糖尿病管理模式分析及改进构想
5.1.1 传统糖尿病管理模式及优劣性分析
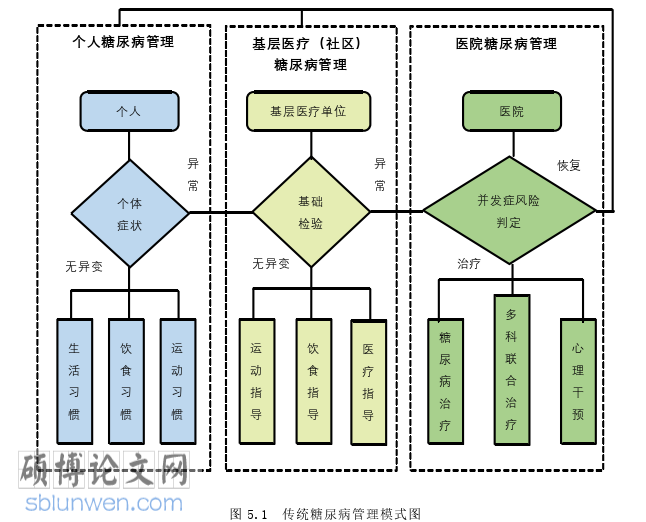
传统观念认为当身体出现不适症状就需要去医院治疗,居民个体对于专业医疗知识相对匮乏,在很大程度上对疾病的认知来源于医生,造成一种现象,即很轻微的病症也要去三级甲等医院咨询,这既造成个人健康管理被忽视,也造成医疗资源的紧张。
传统的健康管理模式主要依靠个体、社区和医院,受困于传统医疗观念的桎梏,过度依赖于专业医生通过专业知识以及个人经验而作出判断。很多糖尿病病人的病症较轻,这就更加需要个人健康管理上发挥作用,包括个人在生活习惯、饮食习惯、运动习惯等方面要做出针对糖尿病的调整。社区基层医疗机构是距离居民个人最近的专业医疗知识提供者,应该加大宣传相关知识的力度,引导病人健康的生活方式,并提供基础的医疗服务,比如与糖尿病相关的生化指标的检验等,并根据结果做出专业的指导性意见,比如饮食、运动等方面的改进以及是否需要升级治疗等级等等。医院作为传统糖尿病诊疗程序中最高等级的医疗机构,主要负责管理病程发展到一定程度的糖尿病人,这些糖尿病患者已出现或者具有高风险出现糖尿病并发症,单纯从饮食、运动等方面的调整已经满足不了治疗糖尿病的需要,这就需要医院针对其病情给出专业的治疗意见。我国近年来对于医疗事业的改革进行了很多探索,综合性医院对于糖尿病的治疗一般不再局限于单一部门。
计算机论文参考
...............................
第 6 章 总结与展望
6.1 工作总结
本文研究内容主要是针对收集到的个体医疗体检数据进行糖尿病预测,通过糖尿病预测系统,方便个人通过机器学习模型预测结果初步了解自己的患病情况,糖尿病预测系统还可辅助医生进行诊断,节省医疗资源,降低医生的误诊、漏诊情况的发生,其预测结果可供医生进行参考和分析,为下一步的治疗方案提供方向。本文的研究工作包含以下几点:
(1)本文首先对糖尿病的研究背景以及意义进行了介绍,在参考了大量文献以后对糖尿病预测分析的现状进行了归纳总结,详细介绍了机器学习在医疗领域的应用,为后续的工作奠定了基础。
(2)数据预处理和特征选择。收集了山东省烟台市龙口市齐鲁医院内分泌科的个人体检数据报告,将其集成为具有特征列和目标列的糖尿病原始数据集,通过数据统计性描述和可视化分析,查看特征的分布情况及异常情况,剔除了数据中的异常值和不相关列,剔除了存在大量缺失值的特征,在对比了几种填充缺失值方法在随机森林模型上的表现后确定以众数填充缺失值的方法使数据完整,将数据的离散特征进行了独热编,最后对数据归一化处理后的数据集基于 RFE-XGBoost 算法模型进行特征选择,得到最终有效的糖尿病数据集。
(3)糖尿病预测模型的构建。本文研究的单模型为随机森林、AdaBoost、XGBoost,分别对三个单模型进行参数调优,经过多次实验,使各个单模型在最终的糖尿病数据集上表现达到最佳,然后将调优后的三个单模型作为Stacking 融合模型的第一层,由于第一层集成的为强分类器,为了防止过拟合现象的发生,采用第一层输出的分类概率作为 Stacking 第二层逻辑回归模型的输入,经实验表明,融合后的模型在分类指标上的表现均优于其他三个单模型。
参考文献(略)