本文是一篇计算机论文,笔者认为目前大多数的推荐算法没有考虑到评分数据质量不高的问题,在推荐系统数据集中,评分数据是可以利用的最能直接反映用户兴趣偏好的数据,评分质量的高低直接影响着推荐算法的效果。
第1章 绪论
1.1研究背景及意义
伴随着互联网技术的不断成熟,人们从信息匮乏时代步入了信息爆炸时代,海量的数据出现在互联网的汪洋中,人们越来越难从大量的信息中找到自身感兴趣的内容,信息也越来越难以被展示给可能对它感兴趣的用户。搜索引擎是应对信息超载[1]的技术手段之一,其主要是提供搜索关键词的功能,帮助有目标的用户较快速地获取到所需要的信息。然而多数情况下,用户没有特别清楚自己需要什么,也因此推荐系统[2]作为解决信息过滤的有效技术出现并不断发展。推荐系统的任务就是连接用户和信息并创造价值,其可以在用户没有明确需求的情况下,通过用户的历史行为等信息,挖掘出用户有可能感兴趣的信息并对用户进行推荐。
设想如下场景:目标用户想看一部热播电影《我和我的祖国》,用户只需要走进一家电影院,选择其中一个场次观看就可以了。或者通过互联网,比如说用户可以打开豆瓣,在搜索框中输入电影名称,然后就可以找到用户想要观看的电影,但是这两种方式都需要用户有明确的目的,如观看电影《我和我的祖国》或者其他电影。但是,如果用户没有明确想看的电影时,比如现在用户想寻找并观看感兴趣的电影,这时在海量的电影数据库面前,用户真正感兴趣的电影不容易在短时间内被找到。个性化推荐系统[3]可以解决这个困扰,它可以通过分析用户曾经喜欢观看的电影,进而寻找出用户有可能感兴趣而未产生过交互的电影推荐给用户。此外,对于长尾[4]物品,即一些冷门不容易被发现的物品,推荐系统也可以帮其找到归宿,推荐给需要它的目标用户。
基于海量数据的背景下,可以解决信息超载问题的推荐算法,在学术领域和应用领域都越来越受欢迎。推荐系统在解决用户难以找到所需信息问题的同时,也解决了把信息展示给有可能对它感兴趣的用户的问题。生活中,个性化推荐系统随处可见,比如京东、淘宝等各大电商平台的商品推荐,网易云、QQ 音乐等音乐平台的音乐推荐,知乎等资讯平台的文章推荐,还有高德地图的出行推荐,抖音的短视频推荐以及豆瓣的电影推荐等都十分受到大家的喜爱,极大方便了人们的生活。当前推荐系统已经融入到人们的日常生活中,无处不在,不仅方便人们生活,也可以促进消费,有利于经济发展。
..............................
1.2国内外研究现状
个性化推荐系统最早出现在二十世纪九十年代中期,自出现以来极大缓解了因互联网的日益成熟而随之产生的信息超载问题,因此被广泛应用于各种信息推荐网站,比如新闻推荐、音乐推荐、短视频推荐、电影推荐、出行推荐以及电子商务中的商品推荐[5]等。一个好的个性化推荐算法可以有效协助互联网用户在短时间内找到其所需要的信息,为其日常的各种生活所需带来极大的方便。
在推荐算法得到广泛应用的同时,问题和挑战也随之出现,为此国内外学者对其进行了深入研究,推荐算法也因其良好的应用价值一直是学术界的研究热点[6]。推荐算法[7,8]主要做的工作是通过对系统中现有的用户和项目相关数据的挖掘为目标用户生成推荐列表,把目标用户可能感兴趣的项目推荐给他。目前现有的推荐算法根据其挖掘的数据特征对象不同主要可分为基于内容的推荐[9]、协同过滤推荐[10]以及混合推荐[11]三大类。
基于内容的推荐主要挖掘的是项目特征,通过对用户的历史偏好项目进行特征分析,去挖掘类似特征的项目然后推荐给目标用户。早些时候,Basu等人[12]提出了一种归纳学习的算法完成推荐工作,作者认为当时现有的推荐算法大都只使用了用户对项目的评级数据,忽略了项目本身的属性数据,而项目的属性数据中蕴涵着丰富的特征,故通过归纳学习的算法同时考虑用户对项目的评级数据以及项目的属性数据去完成推荐,最终在电影领域的实验证明该算法取得了不错的效果。随着 Web 2.0 时代的到来,Lops 等人[13]基于用户会自主使用一些关键字或者标记去描述其对某个项目的感受这个前提,认为带标签的推荐系统可以为用户提供合适的标签去描述其对项目的看法,从而可以根据标签聚合的方法为用户生成推荐列表,实现一个基于协作和内容的推荐过程。
..........................
第2章 相关理论和技术
2.1推荐系统
推荐系统[32-34]是为了解决信息超载这一问题而诞生的,它可以通过分析用户的历史行为、社交关系[35]、兴趣点[36]、所处上下文环境[37]等数据,挖掘出用户的兴趣偏好,从而将目标用户有可能感兴趣的信息推荐给他。
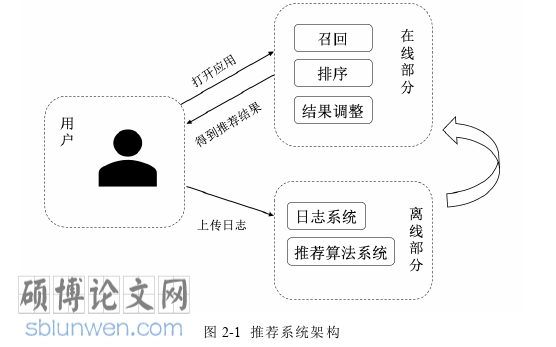
推荐系统的结构都是类似的,一般由在线和离线两部分组成,如图 2-1所示。其中离线部分包括后台的日志系统和推荐算法系统,主要是根据推荐算法对用户的日志数据进行分析,然后应用于在线部分。而在线部分主要是实现与用户的交互功能,负责把推荐结果返回给用户,包括召回、排序和对结果的调整等[38]。
计算机论文怎么写
对于一个推荐系统来说,拥有一个性能优越的推荐算法,是其留住用户的关键[39]。推荐系统应用广泛,比较著名的有 Amazon、Netflix、淘宝等,学术界研究推荐算法的热情也一直很高,推荐算法可以划分为协同过滤推荐算法[40]、基于内容的推荐算法[41]和混合推荐算法[42],目前最常用的推荐算法是协同过滤推荐算法。
............................
2.2协同过滤
协同过滤(Collaborative Filtering,CF)的核心思想是“物以类聚、人以群分”[43]。一般来说,协同过滤推荐分为三种类型:基于用户的协同过滤,基于项目的协同过滤和基于模型的协同过滤。
基于用户的协同过滤(User-based Collaborative Filtering,UCF)主要考虑的是基于用户之间的相似度找到最近邻居集合[44]。UCF 首先根据用户对项目的评价,找到与目标用户兴趣相近的相似用户集合,即最近邻居集合,然后将最近邻居感兴趣同时目标用户没有交互过的项目进行推荐。比如用户 A喜欢电影《我和我的祖国》、《我和我的家乡》以及《肖申克的救赎》,通过计算发现用户 A 是目标用户 B 的相似用户,这时 UCF 算法会把用户 A 喜欢而用户 B 还未看过的电影《我和我的家乡》、《肖申克的救赎》推荐给目标用户B。算法流程如下:
算法输入:用户行为日志,用户相似度矩阵。
算法输出:可推荐的项目序列. 访问用户行为日志,获取近期变化的用户集合 。
针对集合 中每个用户 :访问用户相似度矩阵 !",获取与用户 相似的用户合集 ( );对于 ( )中的每一个用户 #,找到其评价过的项目集合 。
对于集合 中的每个项目 !:计算用户对每个项目的偏好值 !,根据用户相似度进行加权、去重、排序,按照偏好值 !的高低取前 个项目。
保存前 个项目到推荐列表中。
假设推荐系统中的用户为 !( = 1,2, … , ),项目为 "( = 1,2, … , ),用户 !对项目 "的评分为 !",与目标用户相似的最近邻集合为 !( = 1,2, … , ),目标用户和最近邻用户的相似度为 ( , !),则基于用户的协同过滤算法 UCF可以通过下面的公式计算目标用户 对项目的偏好程度:
................................
第 3 章 用户评分修正模型 ........................... 15
3.1 模型框架 .................................... 16
3.2 数据预处理 ....................................... 16
第 4 章 基于主题社区检测的协同推荐模型 .................................. 33
4.1 模型框架 ..................................... 35
4.2 基于改进谱聚类的项目预聚类 ......................................... 36
第 5 章 实验与分析 ........................... 48
5.1 实验设置 ......................................... 48
5.1.1 实验数据集 .............................. 48
5.1.2 实验环境 ........................ 49
第5章 实验与分析
5.1实验设置
5.1.1 实验数据集4为了验证本文所提出模型的有效性,在两个真实数据集上进行实验。美国 Minnesota 大学计算机科学与工程学院的 GroupLens 项目组创办的MovieLens 数据集是推荐领域中最为经典的数据集之一[80],故本文实验采用了 MovieLens 数据集。MovieLens 数据集采用 5 星级评分机制,有不同规模,如表 5-1 所示。本文实验采用 MovieLens-1M 规模的数据集,评分范围为 1-5。
计算机论文参考
还有就是豆瓣电影数据集,本文另一个实验数据集来自网友从豆瓣电影网站上爬取的数据集,记为 DouBan。数据内容中用户数和电影数分别为 1000和 1659,18118 条评分记录和 13112 条评论,评分范围为 1-5。
故本文实验选取的两个真实数据集如下表所示。此外,在 DouBan 和MovieLens 两个数据集上,本文实验均以 4:1 的比例划分训练集和测试集。
...........................
第6章 总结与展望
6.1总结
本文提出基于 SC 和 TCD-CF 的推荐算法,包括一种基于用户评分真实性调整和用户评分标准统一的评分修正模型和一种基于主题社区检测的协同推荐模型。SC 模型主要解决用户评分不真实、不准确、区分度不高以及用户评分习惯、标准不同的问题。而 TCD-CF 模型则在经过 SC 模型修正后的评分矩阵基础上进行主题社区检测,分主题为目标用户进行推荐,解决用户相似度不准确的问题。此外,在社区检测过程中,会根据修改后的评分矩阵构建用户-用户关系图,把原本稀疏的评分矩阵变成一个相对稠密的图结构,在一定程度上缓解了数据稀疏性的问题。
目前大多数的推荐算法没有考虑到评分数据质量不高的问题,在推荐系统数据集中,评分数据是可以利用的最能直接反映用户兴趣偏好的数据,评分质量的高低直接影响着推荐算法的效果。而那些注意到评分质量的推荐算法大多只是比较简单的对评分数据进行了归一化,并不能有效解决问题。另外,在协同过滤推荐算法中,寻找目标用户的相似用户是至关重要的一步,但是现有的方法都是基于用户整体偏好进行相似度计算的,往往不能准确找到与目标用户真实相似的用户集合,且受到数据稀疏以及相似的计算方法本身有误差的制约,导致推荐效果十分不理想。针对现有研究工作的不足,本本主要进行了以下几个部分的研究:
1)针对用户评分不真实、不准确、区分度不高以及用户评分标准主观不统一的情况,本文提出了一种基于用户评分真实性调整和用户评分标准统一的评分修正模型 SC。SC 模型有两大部分,第一部分是通过基于 BERT 词嵌入的 BiGRU-Attention 模型对评论文本进行情感分析,然后根据情感分析结果得到修正因子,从而对原始评分进行一次修正。第二部分是通过梯度下降模型去优化目标函数,统一用户的评分标准,对评分矩阵进行二次修正。基于上述两步,最终得到一个高质量的评分矩阵。
2)针对现有的协同推荐算法在寻找相似用户时都是整体考虑用户偏好而导致找到的相似用户不够精确的问题,本文提出了一种基于主题社区检测的协同推荐算法。事实上,用户的兴趣偏好跨度很广并且有自己的个性,用户和用户之间也往往只是局部有交集,而在不同的项目类下有不同的相似度,所以本文考虑分类去寻找目标用户的相似用户,找到和目标用户在某方面志趣相投的朋友,分别完成相应主题的推荐。
参考文献(略)