本文是一篇计算机论文,本文的工作重点关注多分类数据集,即数据集里的各个类别互不重叠。事实上,实际应用中存在着大量的多标签不均衡数据,特别是极端多标签数据集,各个类别的样本数量呈长尾分布。
1引言
1.1研究背景及意义
大数据时代,基于大数据的人工智能技术深刻影响着人们生产生活的方方面面。物联网、5G技术、云计算等高新技术正在以前所未有的速度引领工业界进行技术革新。然而,在这样的潮流之中,不均衡数据分析问题是工业界应用大数据技术的一个瓶颈问题[1,2]。
不均衡数据指:在数据集当中,有些类别的样本数量很大(通常被称为多数类),而有些类别的样本数量很小(通常被称为少数类),两者之间的数量比值甚至能达到100或1000。传统分类方法为了保证整体精度的最大化,通常更加注重多数类样本的学习,同时忽略了少数类样本的分类精度。虽然这样的分类结果整体上较佳,但是每个类别的分类性能都应受到同等重视,在某些应用场景中少数类的分类性能甚至更为重要。比如,在电信诈骗检测问题中,诚信用户属于多数类,诈骗团伙是少数类,而准确识别出诈骗团伙比识别出诚信用户更为重要。
解决不均衡分类问题有助于减轻企业的数据获取和标注压力,提升数据分析效率。目前人工智能在工业界的主要应用分为计算机视觉、自然语言处理、语音数据分析和推荐机制四个方面,这意味着有大量的图像实例、文本实例和语音实例需要被收集,在数据采集、数据清洗、数据标注、数据特征提取、数据存储等各个环节都需要大量的人力和时间成本,这样庞大的成本会使很多人工智能企业依赖大量计算服务器和存储设备,甚至劝退实力较低的企业。当巨大成本难以负担时,在数据获取过程中便会出现部分类别样本稀缺、样本质量差或样本未标注的情况,进而导致数据不均衡问题。若是能解决不均衡分类问题,那么企业进行数据采集时不必担心由部分类别的样本稀缺所导致的分类器分类性能下降问题,这将大大降低物联网、云计算等数据密集型工程的成本,提升数据收集效率,增强数据分类性能。
..........................
1.2研究本质及难点
1.2.1研究本质
基于数据增强的不均衡分类问题的形式化定义为:给定一个不均衡多分类数据集D={X,Y}={(xi,yi)|xi∈Rd,yi∈{1,...,K},i=1,...,n},其中X是输入空间X中的一个观测数据集。基于数据增强的不均衡问题的研究目标是生成符合数据分布与本质特性的新样本,将数据集恢复为均衡数据集,并训练一个分类器,学习K个类别之间的分类边界,并对输入空间X中的测试样本集{X˜}={x˜j|x˜j∈Rd,j=1,...,m}给出每个样本的预测结果{Y˜}={y˜j|y˜j∈{1,...,K},j=1,...,m}。
不均衡数据主要分为相对不均衡数据和绝对不均衡数据。这两种数据集的主要特征都是多数类和少数类样本规模相差悬殊,不同之处在于绝对不均衡数据中少数类样本稀缺,而相对不均衡数据中少数类样本对于分类器训练是相对充足的。基于绝对不均衡数据中的稀少的少数类样本进行学习是十分困难的,而相对不均衡数据中的少数类则更有可能具有复杂的子类分布结构。
大千世界,数据繁芜冗杂,每个类别都具有复杂的分布特性与内在结构。因此,同一个类别内部还会存在多个子类,比如“猫狗二分类”问题中,“猫”和“狗”分别为两个大类,而“狗”类内部还分为“哈士奇”、“金毛”、“柯基”等多个子类。和类间存在不均衡性的情况相似,同一类内的子类之间也可能存在数据的不均衡性。因此,在研究不均衡数据分类问题时,为了在保持整体精度的同时提升少数类分类精度,应当注重分析少数类内部结构的复杂性,充分挖掘少数类内部的本质特征,这样才能生成符合少数类分布特性的新样本,并进一步帮助分类器识别数据集的判别结构。
因此,研究基于数据增强的不均衡分类问题,应当重点学习少数类的内部结构信息和本质特征信息,结合多数类样本的训练,学习到不均衡数据整体的判别结构,生成既具有类判别性又具有多样性的新样本,并训练分类器来明晰数据集的各类之间的分界面,从而准确预测新样本的标签。
...........................
2相关理论与技术基础
2.1相关领域研究进展
不均衡分类问题的解决方案主要分为算法层面和样本层面两个层面[1]。算法层面的方法基于代价敏感机制、集成学习机制等机制创新传统方法,使得创新后的方法能够避免陷入不均衡问题。样本层面的方法通过升采样、降采样等方式,改变样本的数据分布结构,将不均衡数据恢复为均衡数据,使得传统分类器可以基于恢复后的均衡数据进行训练。
基于代价敏感机制的创新方法中,最经典的方法是基于代价敏感机制的支持向量机(Cost-SVM)[30],该方法基于传统机器学习方法支持向量机(SVM),引入代价敏感机制。具体地,该方法为少数类赋予更高的误分代价,为多数类赋予更低的误分代价,从而使分类器更重视少数类的分类结果。实验结果显示,当少数类与多数类的误分代价比值与不均衡数据的不均衡度(多数类与少数类样本的比值)互为倒数时,分类器的分类性能最好。
此外,基于集成学习机制的方法中,最常见的是Boosting[31]和Bagging[32]。这类方法首先同时训练多个弱分类器,再集成各个弱分类器的预测结果,从而得到一个强分类器的预测结果,常见的集成方法有投票机制、加权平均、取最大值或最小值等。Boosting类方法使用相同数据集训练不同弱分类器,而减少预测结果的偏差;Bagging类方法使用数据集的不同子集训练相同弱分类器,而减少预测结果的方差。
算法层面的方法面临误分代价赋值大小难以决定、集成方式难以选择等难题,毕竟少数类样本稀少,可供分类器学习的信息不充足。而样本层面的方法将不均衡数据恢复为均衡数据后,可以依据数据特性选择不同的分类器进行学习,方法选择的灵活性较高、可供分类器学习的信息也更多。因此,本文研究基于样本层面的不均衡分类方法。
...............................
2.2研究方法基础技术
本文所提出的两种新的方法主要基于生成对抗网络(GAN)和自动编码器(AE)两种深度学习模型。为了更清晰的介绍本文所提出的SCDL-GAN与Trans-AE,本节将介绍GAN和AE的模型方法及优缺点。
2.2.1生成对抗网络
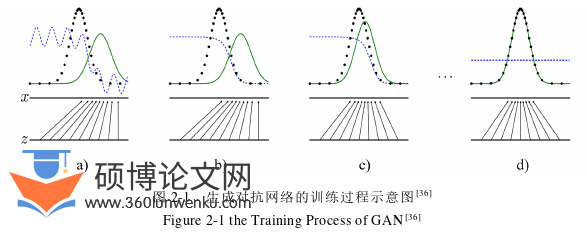
生成对抗网络是一种深度生成模型,在训练过程中,同时训练挖掘数据分布的生成模型G和估计样本来自训练数据而不是G的概率的判别模型C[36]。在训练过程中,G的目标是最大化C判断错误的概率,也就是说,G和C的训练是一个两者之间的最大最小博弈过程。两者之间的对抗竞争将促使他们达到纳什平衡,G将生成符合真实样本分布的假样本,使C无法判断样本为训练数据还是来自G,同时C的判别性能也达到最优。
定义Pz(z)表示G的输入噪声向量的先验分布,则从噪声向量向数据空间的映射可以表示为G(Z;θg),其中,G是一个有多层感知机表示的可微函数,该函数中的参数用θg表示,而G对于训练数据X的分布的估计用Pg表示。类似地,定义第二个多层感知机C(X;θc),其输出为一个常量。C(X)表示X属于训练样本空间而非Pg的概率。通过训练C,最大化预测样本属于训练数据或G的正确标签的概率。与此同时,通过训练G来最小化log(1–C(G(Z)))。
计算机论文怎么写
..........................
3基于有监督类分布学习与生成对抗网络的不均衡分类....................19
3.1研究问题与方法概述...............................19
3.2研究方法.......................................20
4基于类间信息迁移与自编码的不均衡分类..................................33
4.1研究问题与方法概述...........................33
4.2研究方法.............................35
5结论...............................44
4基于类间信息迁移与自编码的不均衡分类
4.1研究问题与方法概述
由于不均衡数据中,少数类样本数量极少,从少数类中获取少数类的本质特征便更为困难。因此,传统的基于少数类内信息进行数据增强的方法,只能生成少数类内部的样本,这些类内的样本对于类间清晰边界的学习帮助甚少;此外,借助线性插值、噪声信息等辅助进行样本生成的方法,难以生成符合应用实际的新样本,毕竟这些辅助信息不具有实际意义;同时,少数类样本较少会导致少数类可用信息较少,这给生成多样性的新样本、避免分类器过拟合带来挑战。
计算机论文参考
如图4-1所示,圆圈表示多数类样本,五角星表示少数类样本。其中,黑色图形表示真实样本,红色或蓝色图形表示生成的样本。受到不均衡数据问题的影响,传统分类器学习到两类分界面H1(黑色线段),这样的分界面忽视了少数类的分类精度,即不均衡分类性能较差。若仅依据少数类内部信息生成新样本,则往往生成类似于蓝色五角星的类内样本,这些样本对于两类分界面的学习没有帮助;而只有生成类似红色五角星的位于两类分界面附近的新样本,才有助于将分界面从H1处改变为H2(红色线段)。
...............................
5结论
不均衡分类问题在实际生活中频繁出现,比如金融诈骗检测、重症疾病诊断等。传统分类器倾向于提升多数类样本的分类性能,而忽视少数类样本的分类性能。然而,在实际应用中,少数类的分类结果往往更为重要。为了在保持多数类分类精度的同时,提升少数类的分类性能,研究者们开展了大量研究工作。其中,基于数据增强的解决方案是重要的研究分支。本文通过分析现有工作的优缺点,针对研究问题,提出两个新的基于自编码的数据增强与分类方法。分别总结如下:
(1)基于有监督类分布学习与生成对抗网络不均衡分类方法(SCDL-GAN)基于两个阶段进行训练。具体地说,在第一阶段,在Wasserstein自动编码器体系结构下设计了一个有监督的类分布学习模型(SCDL)。在第二阶段,依据第一阶段学习到的类分布,基于GANs生成新样本,从一个更稳定的开端进行对抗性训练。同时,将GANs中的判别器修改为K+1类的分类器,以检查样本是假样本还是属于给定的K类之一。
(2)基于类间信息迁移与自编码的不均衡分类方法(Trans-AE)分两个阶段进行数据增强。第一个阶段基于类原型学习与熵值最大化在隐空间学习类内本质信息和类间可迁移信息;第二个阶段将少数类的类本质信息与多数类的类间可迁移信息结合生成新样本。最后,使用分类器结合类原型信息进行各类之间清晰边界的估计。
一系列的实验验证出本文所提出的SCDL-GAN和Trans-AE处理不均衡分类问题的较强性能,既能生成高质量样本,又能在保持多数类分类精度的同时,提升少数类分类精度。希望本文的工作对基于数据增强的不均衡分类问题研究有所贡献。
参考文献(略)