本文是一篇计算机论文,本文验证了两个不同的研究问题“本文提出的嵌入方法是否可以准确学习到Node.js软件包源代码的向量化表示”和“本文提出的标签推荐方法NTR是否可以合理地为Node.js软件包推荐标签?”。
第1章 绪论
1.1 研究背景与意义
Node.js是一个基于Chrome V8引擎的JavaScript运行时的环境,使得JavaScript程序可以在服务器端运行。和其他的后端语言开发相比,Node.js开发具有自己的独特优势,它借助了JavaScript语言天生的事件驱动机制同时采用异步非阻塞IO技术来支持高性能网页应用的开发,适用于不包含CPU密集型操作,但需要处理大量并发IO的业务场景,这种特殊的优势使得Node.js在后端开发技术中占有一席之地。NPM(Node Package Manager)是Node.js默认的Node.js软件包的官方管理平台。NPM平台维护了一个基于CouchDB的数据库,该数据库记录了每个Node.js软件包的详细信息。同时,开发者也可以基于NPM平台完成Node.js软件包的安装、卸载、更新、查看、搜索、发布等操作。目前,在NPM平台上存在1,608,527个Node.js软件包,并且这个数字还在不断的增加。
面对如此庞大数量的Node.js软件包,开发人员很难快速定位到满足需求的那一个。因此为了简化搜索过程,NPM平台提供了一种关键字匹配机制,即开发人员通过输入关键词信息,平台就可以推荐以该关键词作为标签的Node.js软件包。但是关键词匹配机制无法覆盖到没有标签或者被标记得不够完善的软件项目,从而影响了推荐结果的准确性。为了提高这种以标签作为数据源的信息检索服务的质量,有很多致力于研究如何为实体推荐高质量标签的相关工作[1-7]。这些标签推荐方法大多是从实体的文本特征,譬如:标题,描述或者Readme文档等,中抽取出现频率较高的关键词作为候选的推荐标签,或者是利用实体的文本特征作为语料训练模型进行文本分类从而完成标签推荐。然而在Node.js软件包的标签推荐场景下,存在包的描述信息不充分且Readme文档中噪声信息冗余的问题。
....................................
1.2 研究现状
NTR是一种基于代码嵌入的标签推荐方法。本小节将主要围绕典型的标签推荐方法,代码嵌入和程序分析以及多标签分类模型这三个方面研究现状展开介绍。
1.2.1 标签推荐方法
标签是推荐系统中被广泛使用的一种机制,它提供了一种简单的注释方式帮助开发人员快速搜索并且定位到相关的软件项目。大多数开源信息网站都需要依靠标签来管理网站,以提高项目分类,项目推荐等相关操作的准确率和性能。因此,标签的质量对于开源网站而言至关重要。但是,开发人员给软件项目添加标签的过程却是一个主观的行为,不仅依赖于开发人员对项目的理解,也取决于开发人员的语言表达能力和个人偏好。如果缺少自动化的标签推荐工具辅助开发人员给软件项目添加标签,结果就会是随着软件项目的不断增加,标签的数量也会迅速增长,噪声标签增多,从而导致软件项目的管理变得困难。如何为开源网站上的软件项目推荐标签以及如何推荐高质量的标签成为一个值得被研究的问题。
2010年,Al-Koafahi等人基于IBM Jazz软件仓库的实证研究发现该网站上有73%的项目都没有被标记,基于这种标签缺失的现状,他们提出了一种基于模糊集的自动化标签推荐方法TagRec[1],这种方法的一大优势就是在于可以根据开发人员的反馈信息及时更新标签的推荐结果。Wang等人提出了一种组合的自动化标签推荐方法TagCombine[2],这种方法的结构有三个基本组件组成,第一个组件是多标签分类组件,第二个组件是根据语义相似的软件项目进行标签推荐,第三个组件则是根据单词之间共同出现的频率进行标签推荐,综合这三个组件的推荐结果得到最终的标签推荐列表。武汉大学的周平义等人则是设计实现了一种工具TagMulRec[3]用于大型软件信息网站的自动化标签推荐,这种方法是根据软件项目描述文本语义的相似性选择候选的推荐标签,然后利用多分类算法对候选标签进行排序完成推荐工作。
..........................
第2章 相关技术介绍
2.1 Node.js开发
Node.js最早是由瑞安.达尔提出来的基于JavaScript语言和Chrome V8引擎的开源项目,旨在利用JavaScript语言的事件驱动机制和非阻塞IO的特性来开发高性能的web应用,使得JavaScript语言也可以在服务器端运行。在Node.js的开发环境下,开发者采用模块化编程来构建Node.js应用。这样,一个Node.js包可以由多个文件模块组成,每个模块实现一个指定的功能,模块组合起来共同实现一个Node.js包完整的功能。尽管一个Node.js包可能是由多个文件模块组成,但并非包下的所有文件模块都与包的功能直接相关,其中可能会存在一些测试文件或者配置文件等这些与包的功能没有直接关系的文件模块,而那些和包的功能直接相关的模块是被主模块(或者称为入口文件模块)依赖的模块,这是因为Node.js包的API会在主模块中声明导出,被主模块依赖意味着主模块调用了依赖模块中的代码。主模块的路径会声明在配置文件的main属性当中,默认值为根目录下的index文件。
本文试图通过解析Node.js包的源代码,大致构建出包的函数调用图。为了减小静态分析的难度和规模,NTR从主模块开始分析且只专注于分析被主模块依赖的模块,因为只有这些模块才是和Node.js包的功能相关。为了完成构建Node.js软件包函数调用图的目标,使用了三个开发工具:Madge1, Esprima2以及Estraverse3。Madge是一个用于生成Node.js项目模块依赖关系可视化图的开发工具,可以利用该工具分析出被主模块依赖的模块。对于Node.js包下单个模块的分析而言,Esprima可以对JavaScript程序进行词法分析和语法分析,生成对应的抽象语法树,Estraverse则是用于JavaScript程序抽象语法树的遍历。
...............................
2.2 实体嵌入技术
Embedding是一种学习实体向量表示的技术,也被称作嵌入技术,这种技术能够使相似实体对应的向量表示在向量空间中彼此相邻。
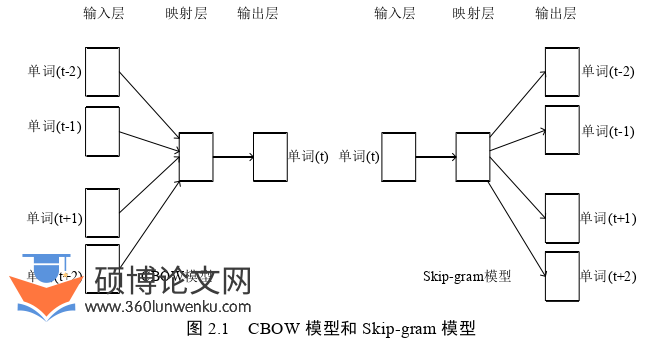
Word2vec[23]是一项为大型数据集中的单词学习连续向量表示的技术。这种技术有两种不同的实现模型:CBOW模型和Skip-Gram模型。其中CBOW模型是根据窗口内单词的上下文来预测当前单词进行模型的训练,Skip-Gram模型则相反,它是根据当前单词来预测窗口内的上下文进行训练,其实本质都是通过捕捉单词与其上下文之间的关系来训练神经网络模型,根据权重矩阵得到每一个单词对应的词向量。
计算机论文怎么写
........................
第3章 Node.js软件包标签推荐 ................. 14
3.1 函数调用关系抽取 ........................... 15
3.1.1 抽象语法树构建 ................... 15
3.1.2 函数节点定位 ........................... 16
第4章 实验设计与评估 ................................ 27
4.1 数据收集及参数设置 ............................. 27
4.2 Node.js包嵌入可视化(研究问题Ⅰ) ................. 29
4.3 NTR标签推荐结果(研究问题Ⅱ) ..................... 30
第5章 总结与展望 ......................... 37
5.1 总结 ....................... 37
5.2 展望 ............................... 37
第4章 实验设计与评估
4.1 数据收集及参数设置
为了能够收集到足够数量的Node.js软件包,本文首先使用NPM官网上推荐的关键字作为索引值编写爬虫程序抓取每一个关键字下所有Node.js软件包的名称等信息。需要声明的是,同一个关键字下的Node.js包可以被视为同一个类别。获取到Node.js包的名称信息之后,紧接着使用NPM的命令行指令 “npm install 包的名称”,将Node.js包下载到本地计算机用于后续的程序分析,最终形成了包含34,977个Node.js软件包的数据集。对于第一个研究问题,本文参考了Import2vec[15]关于Node.js软件包向量可视化实验部分的数据,从本文的数据集中选择了4类关键字,每一个关键字下分别随机挑选了1000个包,总计4000个包用于向量的可视化分析。这四个类别的关键词分别是“grunt”,“gulp”,“homebridge”以及“react”。对于第二个研究问题,需要收集标记完好的Node.js包用于多标签分类模型的监督训练,为此手工挑选了标记完好且下载量较高的Node.js软件包,去除了词频低于5的标签之后,最终形成了包含3,831个软件包,695个有效标签的数据集。除去上述俩实验中7,318个包数据,包数据集中剩下的27,596个Node.js包用于嵌入模型的训练。

计算机论文参考
NTR中卷积神经网络的输入是一个固定大小的L*D的二维数值向量矩阵,其中L是Node.js软件包的函数调用序列长度,D是调用序列中词向量的维度。由于包的函数调用序列长度不一致,为了确定一个统一且合理的最大长度阈值L,本文从34,977个Node.js包中提取出函数调用序列,并且统计了所有函数调用序列的长度,统计结果表明大部分Node.js包的函数调用序列长度介于20到100之间,但是L设置为100只能覆盖到75.1%的Node.js软件包。
............................
第5章 总结与展望
5.1 总结
现有的标签推荐方法大多利用实体的文本特征作为数据源训练分类模型来实现。但在Node.js软件包的标签推荐场景下,Readme文本噪声信息过多且预处理过程繁琐。包的描述文本过于简短甚至缺失,包含的有效信息太少。因此这两种文本特征都不适合作为Node.js包标签推荐模型的数据源。
考虑到描述文本和Readme文档的局限性,本文从Node.js软件包的代码文本出发,提出了一种基于代码嵌入的Node.js包标签推荐方法NTR。NTR主要由Node.js软件包的嵌入模块和多标签分类模块组成。Node.js软件包的嵌入模块旨在训练嵌入模型学习软件包的代码向量用作分类模型的输入。在该模块下,NTR首先利用了静态程序分析的技术解析包的JavaScript源代码,通过制定语法规则定位抽象语法树中函数节点构造出包的函数调用图。然后利用文本卷积神经网络作为包的嵌入模型,同时结合词嵌入技术将Node.js包的函数调用序列转换为数值向量,完成Node.js包的嵌入。多标签分类模块用于软件包的标签推荐。在该模块下,NTR首先利用聚类算法将软件标签划分到了不同的标签集群下,然后搭建了一个多层感知器的神经网络模型,该模型以Node.js包向量为输入并在输出层计算不同标签集群的概率,选择概率值靠前的k个标签集群作为NTR方法的推荐结果。
在实验设计部分,本文验证了两个不同的研究问题“本文提出的嵌入方法是否可以准确学习到Node.js软件包源代码的向量化表示”和“本文提出的标签推荐方法NTR是否可以合理地为Node.js软件包推荐标签?”。实验结果证明:NTR不仅可以学习到能够保留代码语义信息的Node.js包向量,并且在描述文本不充分甚至缺失的场景下标签推荐结果优于基于描述文本的标签推荐方法EnTagRec和tagCNN。
参考文献(略)