第一章 绪论
1.1 研究背景及意义
随着社会的发展,人们的生活方式发生了极大的变化。生活节奏的加快使人们降低了对于一些发病较慢的“隐性”疾病的警惕性,如结直肠癌。据统计,世界上每年患该病的人数多达 120 万,死于该病的人数大约占据了患者人数的一半,高达 60 万人,不仅使人类的健康问受到严重的威胁,而且使国民经济也遭受了巨大的损失[1,2]。在生物学角度来讲,结直肠癌表现出极其多变的生物行为,它不只是受遗传因素、人群生活环境等因素的单独影响,而且在不同因素相互作用时也会受到很大的影响[3]。此外,该疾病容易复发转移,而且对一些化疗药物具有强烈的抵抗性,给疾病的治愈带来诸多困难。目前几种方法能够帮助医务人员对结直肠癌进行诊断,它们是:X 线检查、血清癌胚抗原、B 超扫描、内镜检查等[4,5],这些无疑对结直肠癌的诊断起到很大作用,但是这些方法都依赖于医生的经验,难以确保准确性,同时也增加了医务人员的工作强度。
1.1 研究背景及意义
随着社会的发展,人们的生活方式发生了极大的变化。生活节奏的加快使人们降低了对于一些发病较慢的“隐性”疾病的警惕性,如结直肠癌。据统计,世界上每年患该病的人数多达 120 万,死于该病的人数大约占据了患者人数的一半,高达 60 万人,不仅使人类的健康问受到严重的威胁,而且使国民经济也遭受了巨大的损失[1,2]。在生物学角度来讲,结直肠癌表现出极其多变的生物行为,它不只是受遗传因素、人群生活环境等因素的单独影响,而且在不同因素相互作用时也会受到很大的影响[3]。此外,该疾病容易复发转移,而且对一些化疗药物具有强烈的抵抗性,给疾病的治愈带来诸多困难。目前几种方法能够帮助医务人员对结直肠癌进行诊断,它们是:X 线检查、血清癌胚抗原、B 超扫描、内镜检查等[4,5],这些无疑对结直肠癌的诊断起到很大作用,但是这些方法都依赖于医生的经验,难以确保准确性,同时也增加了医务人员的工作强度。
针对以上结直肠癌诊断方法的局限性,融入机器学习算法的预测模型逐步成为研究的热点。机器学习算法在疾病预测领域的智能性表现为主动地对医疗数据进行学习,更重要的是根据构建的多个模型做出最终的决策,对提高疾病诊断的准确性、实时性,降低医务人员的工作强度具有重大意义[6,7]。尽管如此,单一的机器学习算法对不同的数据分类预测时未必都能得到可观的效果,必须综合考虑多种技术的融合和优化。目前,利用机器学习算法对结直肠癌进行预测主要存在以下几个问题[8, 9]:
(1)疾病特征因素冗余。就疾病预测模型而言,特征的选取是决定模型预测性能好坏的核心因素。疾病的影响因素往往有很多,但是选取疾病重要特征是一件很困难的事情,由于特征选取方法不恰当,导致选取的特征存在冗余,这直接影响到分类器的分类性能以及模型预测的精准程度。
(1)疾病特征因素冗余。就疾病预测模型而言,特征的选取是决定模型预测性能好坏的核心因素。疾病的影响因素往往有很多,但是选取疾病重要特征是一件很困难的事情,由于特征选取方法不恰当,导致选取的特征存在冗余,这直接影响到分类器的分类性能以及模型预测的精准程度。
(2)不能正确选取特征数量。选择用于创建分类模型的特征数量是至关重要的,最优特征的选择问题属于全局优化问题,它主要研究特征之间相互组合的结果对于分类器分类性能的影响。对于特定的分类器,特征数量选取的合适与否,直接影响它的分类效果。
(3)不能正确选择合适分类器。分类器的性能不仅受数据量的影响,而且与选取特征密切相关。有些分类器适用于大数据集,有些则适用于小数据集;有的分类器适合文本特征,有的分类器适合图像特征。在疾病预测模型中,分类器选取的不合适也会影响预测的准确率。
............................
(3)不能正确选择合适分类器。分类器的性能不仅受数据量的影响,而且与选取特征密切相关。有些分类器适用于大数据集,有些则适用于小数据集;有的分类器适合文本特征,有的分类器适合图像特征。在疾病预测模型中,分类器选取的不合适也会影响预测的准确率。
............................
1.2 国内外研究现状
1.2.1 结直肠癌相关因素
作为一种复杂多变、易转移的常见癌症,结直肠癌的发生与多种因素密切相关。为了进一步的了解和发现该病的发病原因,许多研究者对其相关风险性因素进行了探究。陈辰等人指出饮食差异是影响结直肠癌的重要因素[10]。宋美璇等人通过研究发现动物脂肪为主的高脂饮食与CRC的发病率呈正相关,清淡饮食与 CRC的发生率均呈负相关[11]。Baena 等发现 CRC 的发生与肥胖超重以及肉类摄入过多等因素有关,可以通过减少肉食的摄入量以及加强锻炼来预防该疾病[12]。Angelo 等人经过实验也提出了饮食习惯是影响结直肠癌发病率的重要因素,他们指出,饮食中含有瘦精肉的人群中结直肠癌患者的比例远远小于饮食中含有肥肉的人群比例[13]。除了在饮食方面对结直肠癌的发生进行探究外,许多专家在年龄、性别以及体质指数等方面进行了研究。阮丽琴等人通过青年组(小于 40 岁)和老年组(40 岁至 60 岁之间)结直肠癌发病率的对比指出,在 40-60 岁年龄区间,随着年龄的增加,结直肠癌的患病率增加[14]。Cooper 等人通过划分年龄段方法阐明了结直肠癌患者主要集中在老年阶段,肿瘤比例随着年龄的增长而增加[15]。Emmerzaal 等通过研究发现,肥胖是增加结直肠癌患病率的重要因素,结直肠癌患者的平均身体肥胖指数(BMI)要明显高于健康人群[16]。Thrift 等利用 10226 个结直肠癌样本与 10286 个正常样本做对比分析,得出了随着 BMI 的增加,结直肠癌患病风险增加的结论[17]。
1.2.1 结直肠癌相关因素
作为一种复杂多变、易转移的常见癌症,结直肠癌的发生与多种因素密切相关。为了进一步的了解和发现该病的发病原因,许多研究者对其相关风险性因素进行了探究。陈辰等人指出饮食差异是影响结直肠癌的重要因素[10]。宋美璇等人通过研究发现动物脂肪为主的高脂饮食与CRC的发病率呈正相关,清淡饮食与 CRC的发生率均呈负相关[11]。Baena 等发现 CRC 的发生与肥胖超重以及肉类摄入过多等因素有关,可以通过减少肉食的摄入量以及加强锻炼来预防该疾病[12]。Angelo 等人经过实验也提出了饮食习惯是影响结直肠癌发病率的重要因素,他们指出,饮食中含有瘦精肉的人群中结直肠癌患者的比例远远小于饮食中含有肥肉的人群比例[13]。除了在饮食方面对结直肠癌的发生进行探究外,许多专家在年龄、性别以及体质指数等方面进行了研究。阮丽琴等人通过青年组(小于 40 岁)和老年组(40 岁至 60 岁之间)结直肠癌发病率的对比指出,在 40-60 岁年龄区间,随着年龄的增加,结直肠癌的患病率增加[14]。Cooper 等人通过划分年龄段方法阐明了结直肠癌患者主要集中在老年阶段,肿瘤比例随着年龄的增长而增加[15]。Emmerzaal 等通过研究发现,肥胖是增加结直肠癌患病率的重要因素,结直肠癌患者的平均身体肥胖指数(BMI)要明显高于健康人群[16]。Thrift 等利用 10226 个结直肠癌样本与 10286 个正常样本做对比分析,得出了随着 BMI 的增加,结直肠癌患病风险增加的结论[17]。
在研究传统因素与结直肠癌关系的同时,人们对于结直肠癌致病因素的研究向以 DNA为代表的微观领域过度。Ting 等人从菌群的丰度出发,通过对比结直肠癌患者和健康人群的肠道菌群的含量,发现后壁菌(Firmicutes)和拟杆菌(Bacteroidetes)在两组人群中存在明显差异[18]。Ray 等人发现结直肠癌是在肠道菌群的驱动下发生的,与菌群的含量有密切联系[19]。Jun 等通过对人类微生物群和结肠癌的流行病学研究发现肠道微生物群的组成直接影响结直肠癌的发生[20]。在全基因组方面,Chu 等人研究了结直肠癌患者与健康人群的基因表达情况,发现患者的 MMP7、K1AA1199、CA1、CLCA4 等基因表达异常[21]。王琛等从 MMP7 基因启动子分析,发现 MMP7 基因多态性与结直肠癌易感染性有关,是结直肠癌发病的高危因素[22],为结直肠癌的研究提供新思路。
................................
第二章 结直肠癌预测模型中的相关方法介绍
2.1 引言
随着科学技术的不断发展,为了克服传统疾病诊断方法的弊端,融入机器学习算法的预测模型逐步成为研究的热点。机器学习算法在疾病预测领域的智能性表现为主动地对医疗数据进行学习,更重要的是根据构建的多个模型做出最终的决策,对提高疾病诊断的准确性、实时性,降低医务人员的工作强度具有重大意义。尽管如此,单一的机器学习算法对不同的数据分类预测时未必都能得到可观的效果,必须综合考虑多种技术的融合和优化。目前,利用机器学习算法对结直肠癌进行预测主要存在疾病特征因素冗余、疾病特征选择不当,分类器选择不当等问题。所以,为了提高模型的预测精度,需从疾病特征以及分类器的选择入手进行研究。
疾病特征的选择依赖于机器学习中的特征选择技术。该技术的原理是从全部子集中选取一组较小数目的特征集作为一个特征子集,使构造出来的模型更好,它的主要功能是减少特征数量,使模型的泛化能力更强,减少过拟合,从而使得预测效果更好。为了更准确的预测疾病的发生,除了正确的选择特征因素外,还要根据特征选择合适的分类算法。分类算法与医疗的结合不仅有利于疾病新的特征因素的发掘,更能提高疾病诊断的效率,同时也降低了医务人员的压力。究竟如何选择最佳的特征与分类器是疾病预测领域研究的重点。本节的主要内容是对文章涉及到的特征选择方法,分类算法以及参数优化算法等作相应的介绍,为下文中的预测模型的构建奠定基础。
..............................
..................................
第二章 结直肠癌预测模型中的相关方法介绍
2.1 引言
随着科学技术的不断发展,为了克服传统疾病诊断方法的弊端,融入机器学习算法的预测模型逐步成为研究的热点。机器学习算法在疾病预测领域的智能性表现为主动地对医疗数据进行学习,更重要的是根据构建的多个模型做出最终的决策,对提高疾病诊断的准确性、实时性,降低医务人员的工作强度具有重大意义。尽管如此,单一的机器学习算法对不同的数据分类预测时未必都能得到可观的效果,必须综合考虑多种技术的融合和优化。目前,利用机器学习算法对结直肠癌进行预测主要存在疾病特征因素冗余、疾病特征选择不当,分类器选择不当等问题。所以,为了提高模型的预测精度,需从疾病特征以及分类器的选择入手进行研究。
疾病特征的选择依赖于机器学习中的特征选择技术。该技术的原理是从全部子集中选取一组较小数目的特征集作为一个特征子集,使构造出来的模型更好,它的主要功能是减少特征数量,使模型的泛化能力更强,减少过拟合,从而使得预测效果更好。为了更准确的预测疾病的发生,除了正确的选择特征因素外,还要根据特征选择合适的分类算法。分类算法与医疗的结合不仅有利于疾病新的特征因素的发掘,更能提高疾病诊断的效率,同时也降低了医务人员的压力。究竟如何选择最佳的特征与分类器是疾病预测领域研究的重点。本节的主要内容是对文章涉及到的特征选择方法,分类算法以及参数优化算法等作相应的介绍,为下文中的预测模型的构建奠定基础。
..............................
2.2 特征选择方法
2.2.1 Logistic 回归
Logistic 回归是一种广义的线性回归分析模型,目前主要的用途为:寻找疾病的致病因素、确定某种因素对疾病发病原理的相对重要性。此外,该模型还被广泛应用在数据挖掘及经济预测等领域[32]。Logistic 回归分类主要有三种:一、因变量为二分类的回归(二项 logistic 回归);二、因变量为无序多分类的回归(多项 logistic 回归);三、因变量表现为有序,并且对应多个分类的 logistic 回归(累积 logistic 回归)。在疾病预测领域,人们主要利用二项 Logistic 回归对疾病的相关致病因素进行分析。例如,在利用该方法探讨引发疾病的危险因素的过程中,根据疾病是否发生,对实验数据进行二分类。通常情况下,样本分类赋值情况为:患病用 1 表示,健康用 0 表示,1 和 0 即代表了二分类因变量。 Logistic回归模型的使用条件是各个变量之间相互独立,适合变量少的样本分析。随着研究的不断深入,该分析方法已经嵌入到 SPSS 软件中。我们通过将实验数据输入到 SPSS 软件中即可利用该模型进行数据分析。
2.2.1 Logistic 回归
Logistic 回归是一种广义的线性回归分析模型,目前主要的用途为:寻找疾病的致病因素、确定某种因素对疾病发病原理的相对重要性。此外,该模型还被广泛应用在数据挖掘及经济预测等领域[32]。Logistic 回归分类主要有三种:一、因变量为二分类的回归(二项 logistic 回归);二、因变量为无序多分类的回归(多项 logistic 回归);三、因变量表现为有序,并且对应多个分类的 logistic 回归(累积 logistic 回归)。在疾病预测领域,人们主要利用二项 Logistic 回归对疾病的相关致病因素进行分析。例如,在利用该方法探讨引发疾病的危险因素的过程中,根据疾病是否发生,对实验数据进行二分类。通常情况下,样本分类赋值情况为:患病用 1 表示,健康用 0 表示,1 和 0 即代表了二分类因变量。 Logistic回归模型的使用条件是各个变量之间相互独立,适合变量少的样本分析。随着研究的不断深入,该分析方法已经嵌入到 SPSS 软件中。我们通过将实验数据输入到 SPSS 软件中即可利用该模型进行数据分析。
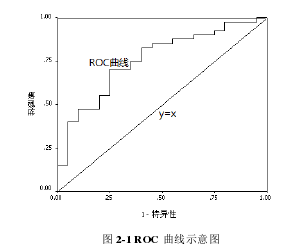
2.2.2 ROC 曲线
ROC 曲线也被称为感受性曲线(Sensitivity Curve)[47]。ROC 曲线以(1-特异性)为横轴,敏感度为纵轴作图,通常高于线性方程 y = x (图 2-1 所示)。 随着 ROC 曲线接近左上方,即接近 1 的区域,说明试验的诊断价值越好。ROC 曲线的主要作用有以下两点:
① 可以通过二分类数据分析指标对疾病的判别能力,并且得出相应的临界值,即cutoff 值[47];ROC 曲线越靠近左上角,它所对应的指标的灵敏度与特异性越高,说明试验的准确性就越高[47,48]。
② 方便同一疾病不同诊断指标之间的比较。通过将不同指标对应的 ROC 曲线绘制在同一坐标系中,比较曲线下面积(AUC)获得最优诊断价值的指标。AUC 越大,对应的指标的诊断价值越高。
ROC 曲线也被称为感受性曲线(Sensitivity Curve)[47]。ROC 曲线以(1-特异性)为横轴,敏感度为纵轴作图,通常高于线性方程 y = x (图 2-1 所示)。 随着 ROC 曲线接近左上方,即接近 1 的区域,说明试验的诊断价值越好。ROC 曲线的主要作用有以下两点:
① 可以通过二分类数据分析指标对疾病的判别能力,并且得出相应的临界值,即cutoff 值[47];ROC 曲线越靠近左上角,它所对应的指标的灵敏度与特异性越高,说明试验的准确性就越高[47,48]。
② 方便同一疾病不同诊断指标之间的比较。通过将不同指标对应的 ROC 曲线绘制在同一坐标系中,比较曲线下面积(AUC)获得最优诊断价值的指标。AUC 越大,对应的指标的诊断价值越高。
..................................
3.1 引言 ............................... 17
3.2 数据集 ............................ 18
第四章 基于标记基因的结直肠癌预测模型 ..................................... 24
4.1 引言 ..................................... 24
4.2 数据集 ............................... 25
第五章 总结与展望 ................................ 34
5.1 总结 .................................. 34
5.2 展望 ......................... 35
第四章 基于标记基因的结直肠癌预测模型
4.1 引言
微阵列技术被逐渐应用于结肠直肠癌(CRC)的分类和预测中。然而,当基于不平衡数据选择疾病的特征基因时,微阵列数据会由于数据特征维度高,导致构建的模型预测性能不佳。因此,基于微阵列基因构建准确地预测 CRC 的适当模型具有重要意义。在本章中,针对微阵列基因数据,我们构建了组合模型将样本分类为健康和 CRC 组,提高预测性能。我们提出的模型由三个功能模块组成。第一个模块主要执行去除冗余基因的功能,利用最大相关最小冗余(mRMR)方法选择特征基因以减少特征的维数,从而改善预测效果。第二个模块旨在使用混合采样算法 RUSBoost 来处理由不平衡数据引起的分类问题。第三个模块侧重于分类算法优化。我们使用基于混合核函数(MKF)的支持向量机(SVM)模型将未知样本分类为健康个体和 CRC 患者,然后,应用鲸鱼优化算法(WOA)来寻找所构建 MKFSVM 模型的最佳参数。实验结果表明,所提出的模型比其他模型获得更高的GM 值,表现为更好的性能。通过对比分析表明,基于不平衡数据 RUSBoost 包装 WOA + MKF-SVM 模型可用于提高结直肠癌的预测性能。前人针对基因微阵列的结直肠癌预测模型有支持向量机模型,与他人研究不同的是本文的支持向量机模型是基于高斯核函数与多项式核函数的混合核函数,克服了单一核函数构建的支持向量机的局限性;此外,本章的研究主要是基于不平衡分类的样本,相比于基于平衡数据样本的研究,本文有效的解决了样本分类不平衡导致的预测性能不佳的问题。
...........................
第五章 总结与展望
5.1 总结
整体来讲,本文的主要工作可以概括为以下几点:
1. 针对结直肠癌传统低维数据特征选取不当的问题,提出一种基于 Logistic 回归模型和 ROC 曲线的双重特征选取方法。首先从统计学角度,利用 Logistic 回归算法从结直肠癌相关的因素中选择显著因素(p<0.05),然后利用 ROC 曲线,根据 AUC 值的大小选择最能影响疾病的组合因素作为 SVM 的输入;此外,通过比对 SVM 中四种不同核函数对分类结果的影响,选择最优核函数,从而提高了预测模型的准确率。
2. 针对结直肠癌基因微阵列数据特征维度高,存在冗余基因、不相关基因的问题,提出了一种结合差异表达基因和 mRMR 算法的特征选取方法。在结直肠癌样本的基因微阵列中包括成千上万个基因,但很多基因冗余或者与疾病不相关的,这些基因一旦带入分类器中,便会影响分类器的预测性能。因此,本文提出了结合差异表达基因判定和 mRMR算法的特征选取方法,利用差异表达选择与疾病最为相关的基因,然后利用 mRMR 算法从差异表达的基因中选择最优的特征组合,从而提高结直肠癌预测结果。
3.针对 SVM 中单一核函数功能的局限性,提出了基于高斯核函数与多项式核函数的混合核函数。高斯核函数具有很强的局部寻优功能,多项式核函数具有很强的全局搜索能力。但是在已有的基于结直肠癌基因微阵列的 SVM 预测模型中,大多采用高斯核函数或者多项式核函数中的一种来构建支持向量机,这样构建的 SVM 在局部寻优或者全局寻优的一方面具有较强能力,因此,本文提出结合高斯核函数与多项式核函数的混合核函数 SVM,使得构建的混合核函数 SVM 同时具有局部和全局寻优能力;此外利用新型优化算法:鲸鱼优化算法(WOA)对各个参数进行寻优,对提高分类性能有很大的帮助。
第五章 总结与展望
5.1 总结
整体来讲,本文的主要工作可以概括为以下几点:
1. 针对结直肠癌传统低维数据特征选取不当的问题,提出一种基于 Logistic 回归模型和 ROC 曲线的双重特征选取方法。首先从统计学角度,利用 Logistic 回归算法从结直肠癌相关的因素中选择显著因素(p<0.05),然后利用 ROC 曲线,根据 AUC 值的大小选择最能影响疾病的组合因素作为 SVM 的输入;此外,通过比对 SVM 中四种不同核函数对分类结果的影响,选择最优核函数,从而提高了预测模型的准确率。
2. 针对结直肠癌基因微阵列数据特征维度高,存在冗余基因、不相关基因的问题,提出了一种结合差异表达基因和 mRMR 算法的特征选取方法。在结直肠癌样本的基因微阵列中包括成千上万个基因,但很多基因冗余或者与疾病不相关的,这些基因一旦带入分类器中,便会影响分类器的预测性能。因此,本文提出了结合差异表达基因判定和 mRMR算法的特征选取方法,利用差异表达选择与疾病最为相关的基因,然后利用 mRMR 算法从差异表达的基因中选择最优的特征组合,从而提高结直肠癌预测结果。
3.针对 SVM 中单一核函数功能的局限性,提出了基于高斯核函数与多项式核函数的混合核函数。高斯核函数具有很强的局部寻优功能,多项式核函数具有很强的全局搜索能力。但是在已有的基于结直肠癌基因微阵列的 SVM 预测模型中,大多采用高斯核函数或者多项式核函数中的一种来构建支持向量机,这样构建的 SVM 在局部寻优或者全局寻优的一方面具有较强能力,因此,本文提出结合高斯核函数与多项式核函数的混合核函数 SVM,使得构建的混合核函数 SVM 同时具有局部和全局寻优能力;此外利用新型优化算法:鲸鱼优化算法(WOA)对各个参数进行寻优,对提高分类性能有很大的帮助。
参考文献(略)