本文是一篇计算机论文,本文通过研究构建基于知识图谱的问答系统过程中的命名实体识别任务,在传统的BiLSTM-CRF模型基础上进行改进,提出一种BERT-BiLSTM-MA-CRF命名实体模型,引入BERT语言模型作为模型的词嵌入层,根据 BiLSTM结合上下文消息进行特征提取,融合了多头注意力机制捕获序列结构,使用CRF来进行序列标注,并对标签打分。
第一章 绪论
1.1 研究背景与意义
近年来,随着信息技术飞速发展,人们与终端系统的交互越发密切,从传统的人与人之间进行交流的Web2.0时代,逐渐进入到人机交互的Web3.0时代。人们的日常生活与互联网息息相关,比如网购后对商品评价,在社交软件中发布动态等等,这些活动所产生的文本数据来源丰富、结构不同,通过自然语言处理(Natural Language Processing, NLP)技术,可以挖掘出文本数据潜在的价值,为社会创造更多财富。
面对每天飞速增长的数据,用户的体验主要存在以下几个问题:一是互联网性质所造成的信息重复冗余,如何进行合理的数据分类是一个问题,二是如何根据用户需求将数据筛选出来。这些问题给人工智能从业者提出更高的要求。传统的搜索引擎存在以下几点不足:首先,其检索方式仅仅是将搜索关键词进行简单的匹配,没有考虑到一词多义的问题,经常会造成误解。其次,其返回的结果数量繁多,需要用户结合自己的认知进行二次筛选。最后,由于前面两点所导致的问题会耽搁用户的时间,进而影响到体验。
自然语言处理作为人工智能产业的重要组成部分之一[1],利用计算机对自然语言进行加工处理,通过定量化的分析实现人与计算机之间的交流,是目前人工智能界研究的热点。
为了克服传统搜索引擎存在的问题,人工智能从业者开始深入研究问答系统。问答系统一方面可以通过数据库将各种信息进行语义化分类,更符合用户认知,另一方面又将结果进行简化,用户可以直观的得到自己想要的答案,不需要进行信息的二次过滤。传统的问答系统是基于机器学习技术搭建的,比较问题和答案之间的语义相似度,这就需要进行字、词、句子级别的语义分析与对比,这项特征工程是人为手动进行提取的,往往依赖于提取者的经验,建模时间较长,因此传统的问答系统的准确率不稳定,且发展缓慢。
...........................
1.2 国内外研究现状
1.2.1 知识图谱研究现状
2012年,谷歌公司为了优化用户的搜索体验,首次提出知识图谱的概念[2],将现实世界中各种类型的数据转化为“资源-属性-属性值”三元组结构,同时记录了数据间的相互关系,这在数据存储领域是空前的,更提高了在管理和应用数据领域的效率,因此近年来是人工智能领域的研究重点,为智能问答、情感分析、个性化推荐等服务提供技术支持。
构建知识图谱的方法主要分为三大类:自顶向下、自底向上和两者混合的方法。在知识图谱发展初期,多数研究机构主要采用自顶向下的方式构建知识库[3],利用已有的知识本体,构造结构良好的层次树,例如WikiData[4]、中国科学院的HowNet[5]和上海交通大学的Zhishi.me[6],这种方法适用于小规模的知识图谱构建,可以较好体现数据间的层次,但是依赖人工操作,且更新本体层时受限。随着知识抽取技术的成熟,目前,应用最广泛的是自底向上的构建方式,这种方法借助信息抽取、知识融合和知识加工[7]等自然语言处理技术,从互联网上获取数据,提取置信度高的资源加入到知识图谱里,例如YAGO和复旦大学的CN-Probase[8]等,其中信息抽取过程是从不同结构的数据源中抽取实体、属性等信息,知识融合是规范化整合不同来源的知识,解决的是重复出现的知识以及不清晰的关系问题,知识加工包括本体构建和质量评估,这种方法适用于大规模知识图谱构建,更新快,但存在数据噪音大、准确度不高等问题。
从知识图谱覆盖范围的角度可以分为两类,一类是面向所有领域的通用知识图谱,主要包括人们生活中的各方面问题[9],例如国外Cycorp公司的CYC[10]、国内的CN-DBpedia[11]等,这一类知识图谱主要应用在搜索领域,强调知识的广度,主要采用自底向上的方式构建,大部分的本体层不规范。另一类是针对某个垂直领域而建立的特定领域知识图谱,如GeoNames[12]、养生知识图谱[13]等,特定领域的知识图谱专业性强,所以必须有严格的本体层,这样才能准确数据分析并辅助进行决策,通常采用混合方式进行构建。
...................................
第二章 知识图谱问答系统相关理论
2.1 基于知识图谱的问答方法
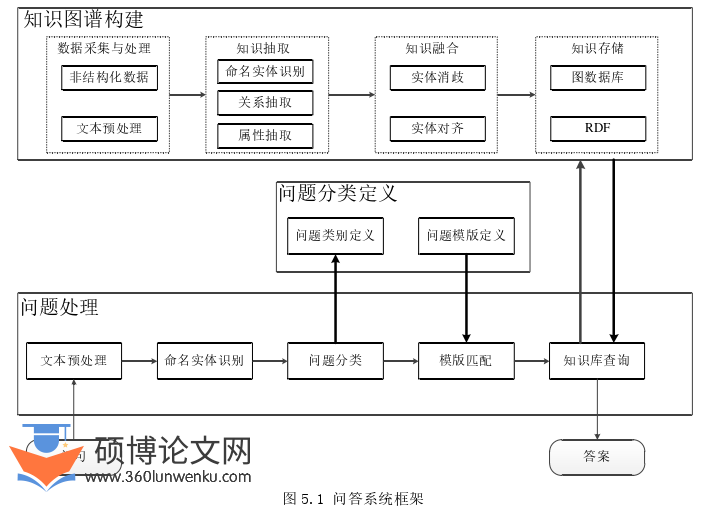
近年来,基于知识图谱的问答系统是把知识图谱作为知识库,将使用者的问题转化为知识库上的结构化查询。系统主要分为两部分:知识图谱部分和问答系统部分。知识图谱部分用三元组的方式表示知识,通过命名实体识别、关系抽取、知识存储等步骤,将互联网海量数据进行结构化表示。问答系统部分首先对自然问句进行命名实体识别,随后把抽取出的实体与知识图谱中的数据进行映射,最终通过结构化查询方法找到知识图谱上对应的知识,返回问句答案,实现知识图谱问答系统。当前主流的几种问答方法是:构建模版、语义解析、基于深度学习的方法,具体介绍如下:
早期的问答系统主要基于模版构建,用预设模版匹配句子中的内容,与问句中的实体进行映射来表示句子,一个模版可以对应多个问题。这种方法准确性高,不足之处在于依赖人工,所以生成模版的成本较高,且只能处理特定模版的问句,因此适用于一些简单查询。随着人工智能技术的发展,Cui等[29]在模版数据量大的场景下,提出一种自动生成学习模版的方法,将问句转化为知识库查询。
语义解析方法则是通过解析并提取用户问句实体,再转化成知识库可以理解的逻辑表达式,通过对应的查询语句来查找知识库中的相关信息,并根据返回的实体集合生成答案语句。整个流程分为问题解析和知识库查询两个部分,问题解析又分为命名实体识别、知识映射和语义结构化。命名实体识别是指将问句中的实体提取出来,实体类型一般为知识库中包含的类型,知识映射一般利用已有的词汇表进行关系匹配,语义结构化是将命名实体和知识库中的关系属性通过函数进行组合。当通过问句解析得到结构化信息后,需要进行知识库查询,此处需要根据结构化信息的形式选用对应的数据库进行查询,返回需要的结果,比如Cypher语言需要选用Neo4j图数据库,SPARQL语言需要选用RDF知识库。
.........................................
2.2 深度学习相关理论
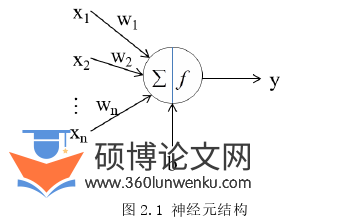
深度学习的基础是多层神经网络,神经网络是研究学者提出的一种多层次的模型。它的基本组成单位是神经元,每一个神经元都包括输入、运算和输出三个部分,其中输入是文本转化后的输入向量或者上一个神经元的输出,运算函数通常是非线性函数,例如sigmoid、tanh等等,目的是使该模型更好地表达语义,输出则是将输入向量经神经元内部运算后得到对应的结果[35]。神经元结构如图2.1所示:
计算机论文怎么写
.............................
第三章 基于BERT改进的命名实体识别模型....................... 21
3.1 传统命名实体识别模型 ........................................ 21
3.2 BERT-BiLSTM-MA-CRF模型构建 ....................... 22
第四章 基于知识嵌入改进的多层嵌套命名实体识别模型 ......................... 37
4.1 嵌套实体识别存在的问题 ............................... 37
4.2 KE-BTBMC模型构建 ................................ 38
第五章 基于医疗知识图谱的问答系统设计与实现 ................................ 45
5.1 需求分析 ............................................ 45
5.2 问答系统设计 ................................. 46
第五章 基于医疗知识图谱的问答系统设计与实现
5.1 需求分析
科技发展日新月异,数据流量得到空前的增长,人们对于信息检索的质量和体验提出了更高的要求,但搜索网站返回的仍是大量相关内容,需要用户主观判断筛选最终结果,不能精准满足用户搜索的需求。问答系统通过解析用户的自然语言问句,通过各种问答技术最终提供给用户唯一结果,受到各个行业的青睐。而深度学习技术的发展,也促进了知识图谱的发展,为问答系统打下了坚实的知识基础,通过命名实体识别等任务构建知识图谱后存储在图数据库中,提供结构化查询的方式,来准确检索到对应的答案。因此,基于知识图谱的问答系统具有良好的应用前景。
计算机论文参考
近年来,“互联网+医疗”行业蓬勃发展,为群众看病就医提供了便利,提高了医疗服务的质量和效率。人们自助查询医疗健康问题的需求日益凸显,由于知识的专业性和资源的平衡性,医疗行业存在以下问题:由于医疗领域专有名词很多是嵌套实体,实体识别的准确性将直接影响答案的准确度,而现有的命名实体识别模型大多针对非嵌套实体,对嵌套实体识别的效果较差,同时,线上已有的医疗网站信息鱼龙混杂,且未构建各种疾病的本体知识库,忽视了各个属性间的关系。总的来说,现有的医疗领域的智能服务人机交互较差,患者看病仍然需多次问诊,医生分布不均,且复诊占用过多医疗资源。因此,本文基于上述功能需求,设计并实现了一个基于医疗知识图谱的问答系统,进一步实现智能信息化。这个系统首先收集网络上的医疗健康相关数据,通过命名实体识别任务提取疾病相关的检查项目、药品、症状等等七类实体,然后抽取其中的疾病推荐药品、并发症状等关系构建知识图谱,通过命名实体识别等过程对问句进行语义解析,返回对应的答案,最终满足用户的问诊需求。
.................................
第六章 总结与展望
6.1 总结
随着互联网的飞速发展和普及,每日产生的数据呈几何倍数增加,在这个资讯即金钱的时代,如何在大量数据中高效获取有效信息是当前备受关注的问题。传统搜索引擎根据用户输入关键词返回所有相关结果,仍需用户自行鉴别最符合的结果,而问答系统能够以简洁准确的方式回答用户,提高了用户体验。近些年来,知识图谱作为人工智能领域的重要研究领域,对知识的表示更为直观,有助于问答系统更加智能化。因此,本文进行了基于知识图谱的问答系统研究,并在医疗领域实现应用。 本文首先阐述了基于知识图谱的问答系统的研究背景和国内外研究现状,并对知识图谱应用进行调研与分析,确定应用在医疗领域。然后介绍了相关的基础理论知识,包括深度学习相关理论、注意力机制、语言模型,通过分析基于知识图谱的问答方法,确定了本文重点研究任务:命名实体识别。首先提出基于BERT改进的BERT-BiLSTM-MA-CRF命名实体模型,然后针对嵌套命名实体,基于知识嵌入改进的多层嵌套命名实体模型KE-BTBMC。具体研究内容如下:
(1)通过研究构建基于知识图谱的问答系统过程中的命名实体识别任务,在传统的BiLSTM-CRF模型基础上进行改进,提出一种BERT-BiLSTM-MA-CRF命名实体模型,引入BERT语言模型作为模型的词嵌入层,根据 BiLSTM结合上下文消息进行特征提取,融合了多头注意力机制捕获序列结构,使用CRF来进行序列标注,并对标签打分。最终在CLUENER2020非嵌套实体数据集和CCKS2017 Task2嵌套实体数据集上做了对比实验,实验结果表明,使用该模型的命名实体识别效果均高于传统模型,但在嵌套实体识别任务上仍需提高。
(2)对于构建知识图谱过程中出现的嵌套实体识别问题,提出了KE-BTBMC模型,利用知识嵌入将外部知识低纬向量表示后和原始序列组合,并在此基础上加大尾实体的计算权重,进行平面NER层的堆叠。在CCKS2017 Task2嵌套实体数据集上和CLUENER2020非嵌套实体数据集上进行对比实验,验证了模型的有效性和适用性。
参考文献(略)