1 绪论
1.1 研究背景与意义
档案检索是合理利用档案资源的必要手段。自 20 世纪 30 年代起,我国档案学科便有检索的相关研究,主要归纳为点收、登记、分类、编目、装订、排列、庋藏、调阅等诸环节[1]。档案检索是档案资源开发利用中不可缺少的一部分。如若档案信息不能被社会使用,它将失去其生存价值。如何在海量的档案数据中快速检索到准确的档案资源,一直是档案检索的关键问题。
随着社会信息化的发展,互联网上中文信息的种类和数量迅速的增长和发展以及社会经济信息化发展程度不断的提高,电子数据已经达到了一个新的电子数据量级[2-4]。电子数据按其结构可分为两类:结构化和非结构化。对于结构化电子数据的采集处理和加工相对简单,可以快速的使用;而在我们的日常生活中,大部分的数据是以非结构化数据的形式存在,非结构化的数据比结构化的数据更难以得到标准化和被计算机所容易理解[5]。非结构化数据的采集和处理往往需要更加智能的 it 数据处理技术和更先进的信息化工具,例如全文检索信息化技术[6-8]。而面对这海量的数据,利用它的第一个前提和条件就是搜索引擎可以对海量的数据进行标准化的检索。互联网上电子信息的快速广泛检索和发展离不开全文检索技术的帮助和支持。由于全文检索信息化技术的不断成熟,越来越多的基于全文检索信息化技术的互联网搜索引擎被社会大众所广泛熟知,例如百度,谷歌[9]等。全文检索信息化技术的成熟推动了互联网搜索引擎信息化技术的快速发展。搜索引擎的技术核心是能够进行全文搜索的技术,但是全文搜索的引擎在其安全性[10-12]和功能(例如全文存档)等等方面远远无法完全满足特定的搜索用户组。全文搜索引擎技术为特定领域用户的搜索提供了很好的全文检索解决方案。搜索引擎可以根据实际的需求为用户来量身定制各种个性化的全文检索解决方案,不仅在很大程度上方便了用户进行检索,还有效的确保了用户的数据安全。在企业级移动应用程序的市场中,全文搜索引擎技术一直都是用户迫切需要的,各种高效的搜索系统都离不开对全文搜索引擎技术的开发和支持,全文检索在这个移动信息时代越来越重要。
...........................
1.2 国内外研究现状
1.2.1 全文检索研究现状
较国内而言,国外的全文检索管理技术的发展情况还是比较成熟的,比较著名的搜索引擎有 Google,infoseek,excite,opentext 等,而国内目前只有百度比较成熟。这些全文搜索的引擎已经收集了非常海量的全文检索网页,对这些全文检索网页的用户建立了全文检索引擎的数据库,所以网站的用户可以快速的检索和找到自己目标的信息。经过多年的发展,这些全文检索系统已经发展成为颇具国际影响的大型全文检索的工具,对于网络上的数据和信息资源的综合利用也起到了非常巨大的意义和作用。国内的全文检索管理技术虽然是起步较晚,但经过多年的发展已经是具有相当的市场规模,比较著名的具有国际代表性的技术就是百度全文检索,百度全文检索是世界上使用最普遍的一个大型中文网页进行全文搜索的引擎,经过多年努力,百度已经是成为了世界上最大的专注于中文搜索的引擎[25],其在全文检索的领域已经是走在了世界的前列,未来全文检索还有很大的市场发展潜力。
全文检索的技术核心是根据索引库的结构而建立,将源文档中所有基本元素出现的信息记录到索引库中[26,27]。对于中文全文检索而言,由于自然语言的知识体系不同,索引的建立机制也不完全相同。在目前进行中文检索的领域,基本的元素结构有单个汉字和词语两种,因此需要有两种基本的中文索引库结构[26.27]。对于英文的字母分词结构特征比较明显,以一个空格或者标点为单位建立分界符,分词较为简单,而英文和汉语之间没有明显的分界符,在字母分词等的文本处理中还是有着很多的缺陷和困难点。也正是因为这样的种种原因,中文全文检索更加困难。尽管如此,国内也已经发展了一些比较成熟的基于中文全文检索的解决方案,并且采用了开放源代码,这在很大的程度上也是促进了垂直行业中全文检索技术的快速发展[28]。近年来,垂直行业全文搜索的市场需求越来越高,所谓针对垂直行业的搜索,是指针对某一垂直行业的主题或专业全文搜索的引擎。而随着互联网络的快速进步和发展也是催生了越来越多的中文主题搜索网站,由于国内外全文搜索网站行业的发展水平不统一,通用全文搜索引擎的查询不准确,查询信息量大,深度不够这些问题日益明显,用户在搜索中迫切需要一个针对某一垂直行业的专业全文搜索的引擎。垂直行业全文搜索的出现,大大提高了全文检索的质量和效率,是全文检索技术快速发展的一块重要里程碑。
.....................
2 相关技术介绍
2.1 循环神经网络
循环神经网络(Recurrent Neural Network,RNN)是一种按照时间顺序来处理序列数据的神经网络。时间序列数据是指在不同时间点上收集到的数据,这类数据反映了某一事物、现象等随时间的变化状态或程度。
长短期记忆网络(Long Short-Term Memory,LSTM)是一种特殊的循环神经网络,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题,也就是说比循环神经网络能够在更长的序列中有更好的表现。
LSTM 的关键在于细胞状态,和穿过细胞的那条水平线。细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。若只有上面的那条水平线是没办法实现添加或者删除信息的,而是通过一种叫做门(gates)的结构来实现的。门可以实现选择性地让信息通过,主要是通过一个 sigmoid 的神经层和一个逐点相乘的操作来实现的。sigmoid 层输出的每个元素都是一个在 0 和1 之间的实数,表示让对应信息通过的权重。比如,0 表示“不让任何信息通过”,1 表示“让所有信息通过”。LSTM 通过输入门、遗忘门和输出门三个这样的基本结构来实现信息的保护和控制,输入门控制输入的信息,遗忘门控制细胞状态中的信息遗忘或存储操作,输出门控制细胞状态的输出信息。LSTM 的基本结构如图 2.2 所示。
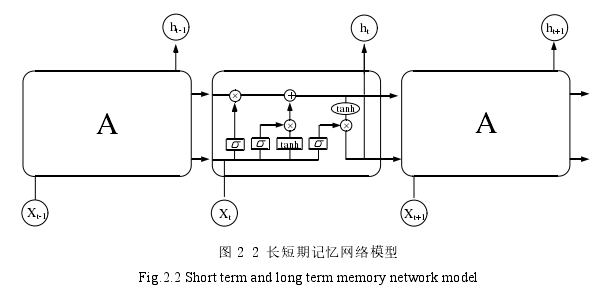
图 2 2 长短期记忆网络模型
2.2条件随机场
条件随机场(Conditional random field,CRF)是给定一组输入随机变量条件下另一组输出随机变量的条件概率分布模型,其特点是假设输出随机变量构成马尔可夫随机场。条件随机场常用于序列标注问题,比如命名实体识别等。条件随机场是一种无向模型图,它的链式模型如图 2.3 所示。
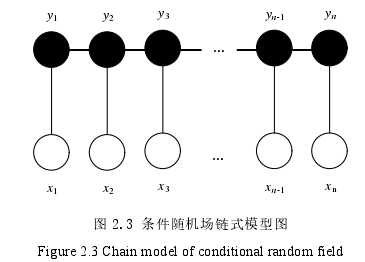
图 2.3 条件随机场链式模型图
3 档案知识图谱..........................30
3.1 档案知识本体建模.........................30
3.2 档案知识抽取模型.........................30
4 基于个性化档案知识搜索引擎的搭建......................40
4.1 个性化语义检索模型......................40
4.2 用户偏好模型......................40
5 基于知识图谱的档案语义检索平台设计与实现....................50
5.1 平台系统需求分析....................50
5.1.1 功能需求....................50
5.1.2 性能需求....................50
5 基于知识图谱的档案语义检索平台设计与实现
5.1 平台系统需求分析
目前档案信息化工作己经取得了非常大的进展,但如何利用海量档案面临新的挑战。基于语义的检索平台不仅要求管理部分能管理知识,还能按普通用户随时随地便利查询与使用档案。因此一个能满足用户利用档案信息平台便成了一个重要的需求。
5.1.1 功能需求
整个档案管理系统主要分为两个前台的档案检索和一个后台的检索服务管理,前台的检索为所有用户很好的提供了档案的检索服务,后台的管理对于前台的检索,档案数据,知识图谱,检索用户等相关的资源信息做统一的管理。档案检索服务主要面向管理系统全体的用户,所有的用户都是可以随时访问公开的档案数据,后台的管理服务面向所有的系统管理员,可实现系统的维护和对档案数据的统一管理。
(1)前台检索的功能需求
系统的核心功能是档案检索,也是设计的主要目的。前台检索包括常见搜索引擎的所有功能,如全文检索,热门搜索,拼音纠错,相关检索,布尔语法等。在此基础上,为了更加符合档案检索的实际需求,设计为前台检索增加档案知识图谱查询,记录用户,历史搜索,在结果内查询,智能推荐,个性排序,语音检索等独有的功能。
前台检索为用户提供高效的检索服务。系统要保证用户在有限的时间内检索到准确的档案数据,并实现在线预览。与传统的档案检索系统不同的是,系统增加了智能推荐功能,很大程度地扩展了检索结果的数量和检索的正确率。前台检索的功能模块图如图5.1 所示。
............................
6 总结与展望
6.1 总结
本文针对档案的高效检索,设计了基于知识图谱的智能语义档案检索系统。经过调研发现在当前技术下,档案检索存在很多实际性问题。为了解决这些实际性问题,通过对档案结构的观察,提出了基于知识图谱的智能语义档案检索技术这一解决方案。进而展开对档案知识图谱的研究,个性化搜索引擎的研究,最后将知识图谱技术和搜索引擎技术相结合,设计开发了智能语义档案检索系统。
本系统的主要技术优点是实现了企业档案相关信息采集检索的处理速度快,检索信息结果的准确率高,完成了系统设计的主要任务和目标。系统通过个性化搜索引擎的技术,解决了网络上和现实中普遍存在的档案检索速度慢和效率低下的档案检索问题。通过先进的知识图谱分析技术,解决了使用者在档案快速检索中检索的结果不准确的各种问题。为档案管理的单位和用户给出了新的档案快速检索的解决方案。为了进一步提高档案检索的效率,让档案检索更快,本系统采用了先进的缓存管理技术,利用 redis 来做同义词的缓存,既更加方便管理,又大大提高了同义词的检索结果速度。而为了更好的让同义词检索的结果更加准确,系统增加了对同义词的判断和进行个性化排序的工具和方法,使得项目测试系统在更快运行的同时也更加的智能。为了更好的让项目测试系统更加的人性化,系统增加了人性化的语音阅读听写功能,让项目测试系统在更快更智能的基础前提下也更加方便。而要更好服务广大的用户,也为了满足项目测试的需要,系统可以直接部署于网上或者云端的服务器,通过注册域名便可以直接访问,让广大的项目测试人员有了更好的成长发展空间。
参考文献(略)