本文是一篇计算机论文,本文提出的基于迁移学习的病症识别方法能够解决有限样本条件下的病症识别问题,但仍需要借助少量的高质量标注数据来完成迁移工作,且处理流程较为复杂需要人工干预,参数调节困难。
第一章 绪论
1.1研究背景与意义
心血管疾病作为健康的头号杀手,引起了国内外专家的高度关注,将信息化技术应用于心血管类疾病成为了研究的重点[1]。随着人工智能技术的发展,机器学习技术为解决这一问题提供了一种选择。目前主流的病症识别技术主要将患者的心电图数据作为训练数据,利用机器学习或者数据挖掘技术构建相应的病症诊断模型,从而完成对患者的病症诊断分析。
计算机论文怎么写
心电图病症识别主要采用有监督学习的方法。而有监督学习要想取得良好的效果,基于两个假设[2]:第一个假设是训练数据集满足独立同分布条件,第二个假设是需要有大量的标注准确的数据,这直接影响分类器的精度和泛化性能。然而,一方面实际中带标签的数据是很少的,获取标签数据是一项繁琐的任务,甚至有时候人力难以完成,因此高质量的人工标注数据是有限的,而相对容易获取的弱标签数据往往标注质量较低,无法满足训练需要。另一方面,病症数据本身具有一定的时效性,随着时间的推移病症会演化到新的阶段,不同时间段所采集的信息存在一定的差异性,无法同时用于建模工作。针对这种问题,迁移学习提供了良好的解决思路。
迁移学习[3]是运用现有的知识解决特征不同或者目标任务不同问题的机器学习方法。与传统的机器学习方法相比,迁移学习放宽了传统机器学习的两个假设条件,可以利用与目标域相关的其他领域数据构建模型,也可以使用带有少量标签甚至没有标签的数据解决目标领域中的问题,充足的标签数据不再是必须条件。迁移学习广泛存在于我们的日常活动中,当两个领域的相关性越强,学习就越容易;相反,如果两个领域的相关性不强,那么学习起来就很困难,甚至出现负迁移的现象[4-5]。迁移学习刚好适用于医疗行业的众多场景[6],因为我们可以获得少量的标注准确度比较高的人工标注数据,也可以获取到标注准确度不高但量级庞大的弱标签数据。这两组数据并不完全相同但存在高度的相关性,数据的特征空间分布不同,任务目标却是相同的,正符合迁移学习的要求。利用迁移学习来解决有限样本条件下的心电图病症识别问题是很有必要的,文献[3,7,8]表明迁移学习训练得到的分类模型具有较高的准确性和可靠性。
.....................
1.2国内外研究现状
1.2.1 心电图病症识别
心电图记录了人体不同部位的电位变化信息,是反映心脏兴奋的发生、传播及恢复过程的客观指标,也是心脏病诊断和治疗中最常用、最简便的检查手段。心电图[17]在心血管疾病诊断中具有不可替代的作用,而机器学习在病症诊断自动化方面显现出独特优势。文献[18]中提出了一种预测谵妄症的模型,取得良好的效果;文献[19]则是将贝叶斯模型用于预测阿尔茨海默病,借助贝叶斯模型良好的解释性来构建病症诊断模型;此外集成模型[20]也被引入了疾病辅助诊断系统中,且表现良好;国内也有研究将机器学习模型用于中医疾病预测分析[21-22]。这表明了传统的机器学习已经开始运用于病症识别问题,并且在单标签病症预测上取得了极佳的效果,但这种单标签病症识别模型很难适用于多标签病症数据的预测中。
与单标签病症识别相比,心电图病症识别问题一般是多标签学习问题。常用的解决多标签学习[23-25]问题的方法主要包含两类,一是问题转换策略[2],将多标签问题转换为多个单标签二分类的子模型,再将子模型的结果结合得到最终结果;二是算法适应策略[26,27],通过调整流行的学习算法来适应多标签学习。Boutell等人提出的方法[9]最具代表性,将多标签分类问题转化为一组二分类问题来解决;文献[9]中提到的基于支持向量机的BSVM算法,也是一种通过二元关联的方式利用SVM解决多标签分类问题。J.Read等人提出的ECC[28]则是一种分类器链法,该方法对标签进行随机排序,然后使用这些不同的排序序列训练多个二分类器链,通过集成获得最终结果。该方法的效果受到排序的影响,很难找到合适的标签依赖关系,如果前一个标签的分类模型效果不佳也会导致排序靠后的标签预测效果不佳。为解决这一问题,Dembczynski等人[26]提出遍历所有可能的标签组合,寻找一组置信度最高的组合训练分类器链,但这种方法将会导致较高的时间复杂度。文献[29]则使用了算法适应策略,通过对现有的单标签预测算法进行改造,使其能够应用于多标签学习的场景;ML-kNN[11]算法也是一种算法适应策略,该算法对k近邻算法进行了改造,通过寻找k个最近邻元素,借助最大后验概率(Maximum aposteriori,MAP)完成模型预测工作,充分利用了邻域间的信息,因此准确率较高,然而计算复杂不适用于解决数据量较大的任务。多标签学习技术目前已经广泛投入了生产实践中,这为研究心电图病症诊断识别提供了一定的帮助。
.................................
第二章 相关理论基础
2.1心电图病症识别
心电图记录了人体心脏的电位信息变化,是进行病症诊断的主要工具[54]。心电图数据的特点主要有以下几个方面:
(1)心电图数据属于多标签数据,每条数据都对应着多个病症标签,且标签的数量远远多于大多数多标签数据;
(2)心电图数据较为复杂易受环境的影响,数据采集的工具或者方式都会对数据本身产生影响,这导致了心电图数据往往会包含众多的噪声信息;
(3)心电图数据会因为患者个体的差别而表现出巨大的差异,在不同的个体中,同一种病症可能表现出相差悬殊的形态,不同的病症则可能表现出相同的特征,这是由于每个患者本身的状态会影响病症的表现形式,诸如年龄、身体机能等的影响;
(4)心电图数据本身代表了一种变化的趋势,病症之间存在一定的转换情况,患病初期患者的症状不太明显,随着时间的推移病情加重,此时患者所得病症可能已经发生了改变,这是一个动态的演化过程,不同的阶段具有不同的表现。
心电图本身的特点决定了病症识别的困难,传统的病症识别技术主要是使用多标签学习技术来解决。主要的方法有:可以将心电图识别问题转化为二分类或者多分类问题,通过为每个病症单独构建模型的方式来识别病症[18-19],这种方式的好处在于不考虑各个病症之间的相互影响,简化了问题便于模型构建,缺点在于分离了病症之间的相互作用,模型泛化性能较差;可以借助集成的思想[55],构建病症识别方法,诸如分类器链法、标签幂集法等,这种方法综合了多个模型的优点,也考虑了标签之间的相互作用,这也意味着时间复杂度的提升,难于计算。这些方法都需要大量的数据才能构建出性能良好的模型,但实际上心电图标注数据往往数量较少,难以满足训练的需要,无法有效解决有限样本条件下的病症识别问题。
............................
2.2多标签学习
多标签学习与单标签二分类学习以及多分类学习存在着明显的区别,最重要的区别在于标签集个数不同。在多标签学习中每个样本对应了多个标签,这些标签所组成的标签集合是整体标签集的子集。而单标签二分类学习和多分类学习中每个样本只有一个标签,多分类学习的这一个标签可能具有多种情况,但这后两者的本质都可以看做同一种类型,区别仅仅在于标签空间的大小。
计算机论文参考
目前,解决多标签学习问题的方法[28,56-57]主要包括两类,一种是基于问题转化(Problem transformation,PT)的方法和基于算法适应(Algorithm adaptation,AA)的方法。PT方法将多标签分类问题转化成传统的单标签分类问题或者转化为多分类问题,从而运用已有的单标签分类方法或多分类方法来解决。而AA方法则是通过对已有的单标签分类或多分类方法进行改造,使其能解决多标签分类问题。PT方法主要包括二元关联法、分类器链法、标签幂集法,其中的代表算法有BSVM、ECC、RAkEL等;AA方法主要是改造现有算法,代表算法有ML-kNN、ML-DT、RankSVM等.
.......................
第三章 基于迁移学习的心电病症识别 ........................ 16
3.1问题分析和解决框架 .......................................... 16
3.1.1 问题阐述和相关概念 ...................................... 16
3.1.2 基于迁移学习的病症识别方法流程 ............................... 17
第四章 基于因果关系的病症标签修正 ............................. 35
4.1相关概念及问题分析 .............................. 35
4.1.1 相关概念 ................................... 35
4.1.2 问题分析 ................................. 36
第五章 总结与展望 ................................. 60
5.1总结 ..................................... 60
5.2展望 ..................................... 61
第四章 基于因果关系的病症标签修正
4.1相关概念及问题分析
4.1.1 相关概念
因果关系[64-66]主要描述的是一个事件和另一个事件之间的作用关系,是一种强关联性,将其中一个事件称为因事件,另一件事件称为果事件,果事件是因事件所导致的结果。一般来说,一个事件可能是多个事件综合产生的结果,并且这些事件发生的时间要早于当前事件,而当前事件又有可能成为其他事件的原因,也就是说一个事件可能存在多个因事件,而该事件本身又可以成为其他事件的因事件。
定义(4.1) 因果关系:在病症识别问题中,一个病症标签和其他病症标签之间存在着某种关联关系,这种关系满足标签A的出现将导致标签B的出现即AB,将这种关联关系称为标签间的因果关系。
病症标签间因果关系具有以下特点:
(1) 客观性:病症标签之间的这种关联关系是客观存在,不会为人的主观意识所改变,因果关系大多数情况并不是存在于事务表面,而是隐藏于事务的内部信息中,需要通过特定的方法进行挖掘。
(2) 特定性:指的是本章研究的因果关系仅仅是病症标签与标签之间的一种关系,与其他的外界因素无关。
(3) 时间序列性:病症的产生具有先后顺序,当前病症的产生可能是由其他的病症影响产生的。
(4) 条件性:病症的产生遵循某种特定的条件性,只有在这种特定的条件下,两个病症之间的因果关系才会发生作用,一般指代的是自然条件下而非外力作用下。
.............................
第五章 总结与展望
5.1总结
基于心电图的病症识别方法是一种广泛用于医学领域的心血管疾病诊断方法。心电图具有独特的特性,主要体现在三个方面:一是心电图是一种多标签数据,允许一条样本有多个标签,标签之间存在着与单标签相比更复杂的联系;二是心电数据易受环境的影响,数据的采集过程会对数据产生影响,导致数据中包含了较多的噪声干扰;三是心电数据也会因患者个体的差异而表现出极大的差异,同一病症对不同的患者可能表现为不同的形态。与传统的多标签学习任务相比,心电图数据的这些特性使得心电图病症识别更加困难,少量的标注数据难以构建出高效的病症识别模型。充足且标注质量较高的数据有利于模型从复杂多变的心电数据中学习规律,降低心电数据本身特性的影响。然而实际中往往无法提供充足的高质量标注数据,基于少量标注数据构建的病症识别模型无法满足生产需要,因此研究有限样本条件下的心电诊断问题很有必要。本文提出了两种方案来解决这一问题:
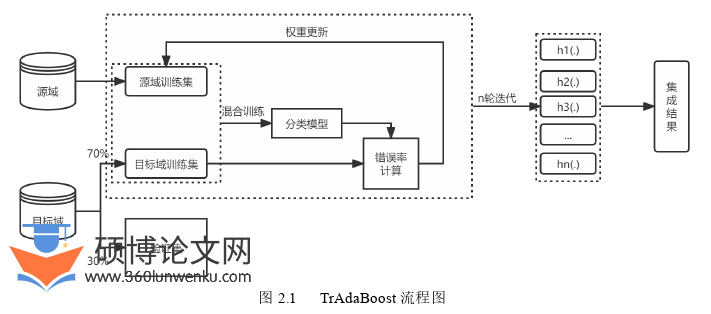
(1)从数据扩充角度出发,提出了一种基于迁移学习的病症识别方法。该方法首先将获取困难的高质量人工标注数据作为目标域,将获取较为容易的弱标签数据作为源域;接着借助特征迁移的方法将源域和目标域映射到同一特征空间,保证源域和目标域的特征分布近似;然后利用实例迁移的方法为每条样本分配一定的权重,通过权重剔除掉源域中和目标域相差过大的数据,同时实例迁移过程中借助了任务域数据,一定程度上缓解了任务域分布不同带来的影响;最后构建多标签迁移模型完成病症识别任务,为了降低数据不平衡带来的问题,采用了聚类的方法来构建实例迁移的基分类器。该方法通过迁移技术达到了数据扩充的目的,能够有效地解决有限样本条件下的病症识别问题。
(2)从知识层面出发,提出了一种基于因果关系的病症标签修正方法,降低了模型对数据量的依赖。该方法首先将基模型的病症预测结果和病症标签集合作为输入条件;然后按照设定的置信域阈值将病症预测结果划分为标签锚点集和候选集;接着通过相关性分析,将与锚点集存在相关性但还不属于锚点集和候选集的标签加入候选集,降低模型预测结果可能出现缺失的影响;再通过因果性分析,借助病症标签集合构建因果结构模型;
参考文献(略)