
第一章 绪论
1.1 研究背景与意义
命名实体(Named Entity,NE),一般分为通用命名实体和特定领域命名实体。其中通用命名实体指的是三个大类和七个小类组成的实体[1]。它包括人名、地名、组织机构名称等具有具体可描述意义的,以及其他以名称为标识的领域实体和表示时间、日期、数字、货币和具体地址短语等信息的统称为命名实体。其中,三个大类分别是实体类、时间类和数字类。而剩下的七个小类有包括时间、日期和货币、人名、地名、机构名、以及百分比等。其中,除了通用命名实体外,特定领域实体,如医疗领域、农业、社交媒体等特殊实体的定义根据实体所属领域特征会相应地对该领域内的各种实体类型给下定义。
1.1 研究背景与意义
命名实体(Named Entity,NE),一般分为通用命名实体和特定领域命名实体。其中通用命名实体指的是三个大类和七个小类组成的实体[1]。它包括人名、地名、组织机构名称等具有具体可描述意义的,以及其他以名称为标识的领域实体和表示时间、日期、数字、货币和具体地址短语等信息的统称为命名实体。其中,三个大类分别是实体类、时间类和数字类。而剩下的七个小类有包括时间、日期和货币、人名、地名、机构名、以及百分比等。其中,除了通用命名实体外,特定领域实体,如医疗领域、农业、社交媒体等特殊实体的定义根据实体所属领域特征会相应地对该领域内的各种实体类型给下定义。
电子病历命名实体识别(Named Entity Recognition,NER),是指从电子病历文本文档中找出带有生物医学特征的实体,如药物﹑手术﹑独立疾病和症状描述以及解剖部位等,并标出实体类型及其在完整一条实体里出现的位置信息。
1.1.1 研究背景
随着 Internet 时代的迅猛发展以及人工智能时代的到来,信息交流变得日益频繁,使得信息量呈现爆炸式的增长。同时,数据资源共享基本覆盖全球范围,人们足不出户即可获取多种多样的信息,包括娱乐信息、专业知识以及能够满足人们需求的其他任何形式的网络资源。然而,面对着网上各式各样的信息,人们难以辨别有些广告和误导购买性质的信息的真假。尤其是专业性较强的医疗信息,除了专业人士外,大多数人对医疗相关知识了解不深,很容易被网上良莠不齐的复杂医疗信息误导从而导致严重后果。因而,如何对这些冗余复杂的医疗信息进行智能化管理与分析,使其成为多数人都能够理解的有用信息,是网络清理以及防范欺骗消费者行为的当务之急。
随着 Internet 时代的迅猛发展以及人工智能时代的到来,信息交流变得日益频繁,使得信息量呈现爆炸式的增长。同时,数据资源共享基本覆盖全球范围,人们足不出户即可获取多种多样的信息,包括娱乐信息、专业知识以及能够满足人们需求的其他任何形式的网络资源。然而,面对着网上各式各样的信息,人们难以辨别有些广告和误导购买性质的信息的真假。尤其是专业性较强的医疗信息,除了专业人士外,大多数人对医疗相关知识了解不深,很容易被网上良莠不齐的复杂医疗信息误导从而导致严重后果。因而,如何对这些冗余复杂的医疗信息进行智能化管理与分析,使其成为多数人都能够理解的有用信息,是网络清理以及防范欺骗消费者行为的当务之急。
...............................
1.2 研究现状
1.2.1 通用命名实体识别研究现状
命名实体识别任务是1991年首次被Rau等人提出[1],一直到1995年9月举办的信息理解会议( Message Understanding Conference,MUC)中第一次正式采用了命名实体这一术语,同时设立了多语言实体识别的评测任务。Rau等人发现一篇财政新闻报道中未知词占全文报道的8%左右,而超过4%是公司企业名称以及一些组织机构名称,其中1/4还是未知词。为了对这个问题给出解决方案,Rau等人研究并实现从新闻语料库中自动提取机构名称的算法。他们的实验通过对已收集了千万家公司名称的一万字语料进行测试,实验结果表示:准确率超过了95%,后来这项研究被认为是命名实体识别的前身。从此之后,NER任务在自然语言处理(Natural Language Processing,NLP)领域开拓了其新的篇章。
从提出NER研究概念至今有将近三十年的发展历史,已成为自然语言处理领域基础而关键的一项任务,并且取得了相当不错的研究成果。NER发展过程中,主要经历了基于规则[1,2]、统计[3-7]、规则与统计相结合的混合方法[8-11]以及最近几年来飞快发展并成为自然语言处理领域影响最为深远的神经网络[12-15]方法。与国内命名实体识别相比,国外对命名实体识别方法研究起步较早,早期的NER方法大致采用模式和字符串匹配的方法,即人工构建有限状态机再对其进行匹配。其中,谢菲尔德大学的La SIE-Il [16]系统和爱丁堡大学的LTG [17]系统是当初以基于规则的方法为主开发的最典型的命名实体识别系统。这种方法缺乏可移植性和鲁棒性,而且此方法消耗相当大的时间和精力资源,开销又大。后来,Bikel[18]等人提出的基于隐马尔可夫(Hidden Markov Model,HMM)的英文命名实体识别方法,成为了最早提出基于统计的命名实体识别方法的研究者。Liao,Ratino等人陆续提出了基于条件随机场[19]和未标注文本训练模型[20]等方法。之后,随着命名实体识别得到学术界关注,连续不断地涌现了各种命名实体识别方法。
1.2.1 通用命名实体识别研究现状
命名实体识别任务是1991年首次被Rau等人提出[1],一直到1995年9月举办的信息理解会议( Message Understanding Conference,MUC)中第一次正式采用了命名实体这一术语,同时设立了多语言实体识别的评测任务。Rau等人发现一篇财政新闻报道中未知词占全文报道的8%左右,而超过4%是公司企业名称以及一些组织机构名称,其中1/4还是未知词。为了对这个问题给出解决方案,Rau等人研究并实现从新闻语料库中自动提取机构名称的算法。他们的实验通过对已收集了千万家公司名称的一万字语料进行测试,实验结果表示:准确率超过了95%,后来这项研究被认为是命名实体识别的前身。从此之后,NER任务在自然语言处理(Natural Language Processing,NLP)领域开拓了其新的篇章。
从提出NER研究概念至今有将近三十年的发展历史,已成为自然语言处理领域基础而关键的一项任务,并且取得了相当不错的研究成果。NER发展过程中,主要经历了基于规则[1,2]、统计[3-7]、规则与统计相结合的混合方法[8-11]以及最近几年来飞快发展并成为自然语言处理领域影响最为深远的神经网络[12-15]方法。与国内命名实体识别相比,国外对命名实体识别方法研究起步较早,早期的NER方法大致采用模式和字符串匹配的方法,即人工构建有限状态机再对其进行匹配。其中,谢菲尔德大学的La SIE-Il [16]系统和爱丁堡大学的LTG [17]系统是当初以基于规则的方法为主开发的最典型的命名实体识别系统。这种方法缺乏可移植性和鲁棒性,而且此方法消耗相当大的时间和精力资源,开销又大。后来,Bikel[18]等人提出的基于隐马尔可夫(Hidden Markov Model,HMM)的英文命名实体识别方法,成为了最早提出基于统计的命名实体识别方法的研究者。Liao,Ratino等人陆续提出了基于条件随机场[19]和未标注文本训练模型[20]等方法。之后,随着命名实体识别得到学术界关注,连续不断地涌现了各种命名实体识别方法。
.............................
第二章 命名实体识别相关研究方法与理论介绍
2.1 基于统计学习的命名实体识别研究
2.1.1 基于分类模型的实体识别
基于分类器的实体识别方法将实体识别问题视为一种分类问题,最终将记录对归类为匹配和不匹配两大类。例如,假定实体的类别为文章,每篇文章对应一条数据记录,由文章名、作者名、出处等属性进行描述。实体识别的目标就是要从这些记录中识别出重复的文章记录。也就是说,针对每两条记录,根据它们的匹配程度,赋予其一个“匹配”或“不匹配”的类别标签。问题的核心是要确定合适的参数(如属性权重、相似度阈值)、匹配函数以及匹配规则等。借助于机器学习理论中的决策树、贝叶斯分类器、SVM、主动学习等模型及相关策略,能够很好地解决分类问题,进而解决实体识别问题。
基于分类器的实体识别方法的基本思想是:首先建立一个初始的实体识别模型;然后,利用训练数据集,即一组已人工标记好“匹配”或“不匹配”的记录对,对该模型进行反复训练,逐渐地,模型在训练中能够学习到“如果哪些属性相似,那么记录对匹配的概率会更大”,
第二章 命名实体识别相关研究方法与理论介绍
2.1 基于统计学习的命名实体识别研究
2.1.1 基于分类模型的实体识别
基于分类器的实体识别方法将实体识别问题视为一种分类问题,最终将记录对归类为匹配和不匹配两大类。例如,假定实体的类别为文章,每篇文章对应一条数据记录,由文章名、作者名、出处等属性进行描述。实体识别的目标就是要从这些记录中识别出重复的文章记录。也就是说,针对每两条记录,根据它们的匹配程度,赋予其一个“匹配”或“不匹配”的类别标签。问题的核心是要确定合适的参数(如属性权重、相似度阈值)、匹配函数以及匹配规则等。借助于机器学习理论中的决策树、贝叶斯分类器、SVM、主动学习等模型及相关策略,能够很好地解决分类问题,进而解决实体识别问题。
基于分类器的实体识别方法的基本思想是:首先建立一个初始的实体识别模型;然后,利用训练数据集,即一组已人工标记好“匹配”或“不匹配”的记录对,对该模型进行反复训练,逐渐地,模型在训练中能够学习到“如果哪些属性相似,那么记录对匹配的概率会更大”,
“应用哪种匹配函数会得到与标记结果更加类似的识别结果”,“记录之间的相似度要达到什么程度,才能认为它们是匹配的”等内容;最终,将这些学习到的参数、函数以及规则应用于实体识别模型中,以提高实体识别的准确度。上述过程如同婴儿认知世界的过程,首先婴儿来到这个世界,然后由父母、老师不断地教授其知识,使婴儿逐渐学习知识,从而建立起对世界的认知。
按照所采用的分类方法不同,基于分类器的实体识别可分为基于决策树的实体识别、基于贝叶斯分类器的实体识别、基于 SVM 的实体识别、基于主动学习的实体识别、基于误差逆传播算法的实体识别和基于遗传编程算法的实体识别等。一般情况下,这些待匹配的记录被看作独立且均匀分布的。
..........................
..........................
2.2 基于神经网络的实体识别
2.2.1 基于简单神经网络的方法
人工神经网络(Artificial Neural Network,ANN)是由许多摹仿人的大脑的生物神经元(neurons)的节点(nodes)组成的,它们是由互相作用的链接连接起来的。神经节点能够接受输入数据并对其进行简单的操作,随后,操作的结果被传递给其他神经元。节点的输出值往往成为其激活(activation)或节点值(node value),是一种自主学习基础上的数学模型。它容和了联想记忆、识别与分类和非线性映射以及优化计算功能等功能。
由非线性单元组成的BP网络作为一个有监督的学习方法,它是由输入层、隐藏层和输出层等三层组成。BP网络是通过正向和反向传播两个阶段学习。数据从输入层进入,通过隐层的一系列处理后传播到输出层来完成正向传播阶段。输出层的实际输出与希望输出值之间相差太大的时候,网络会进入误差反向传播阶段。在此阶段,主要对网络的神经元阈值和连接权值进行调整。通过频繁进行正向和误差反向传播后如果达到学习要求,即误差值小于一定阈值,会停止学习,最终得到正确的BP网络模型。
2.2.1 基于简单神经网络的方法
人工神经网络(Artificial Neural Network,ANN)是由许多摹仿人的大脑的生物神经元(neurons)的节点(nodes)组成的,它们是由互相作用的链接连接起来的。神经节点能够接受输入数据并对其进行简单的操作,随后,操作的结果被传递给其他神经元。节点的输出值往往成为其激活(activation)或节点值(node value),是一种自主学习基础上的数学模型。它容和了联想记忆、识别与分类和非线性映射以及优化计算功能等功能。
由非线性单元组成的BP网络作为一个有监督的学习方法,它是由输入层、隐藏层和输出层等三层组成。BP网络是通过正向和反向传播两个阶段学习。数据从输入层进入,通过隐层的一系列处理后传播到输出层来完成正向传播阶段。输出层的实际输出与希望输出值之间相差太大的时候,网络会进入误差反向传播阶段。在此阶段,主要对网络的神经元阈值和连接权值进行调整。通过频繁进行正向和误差反向传播后如果达到学习要求,即误差值小于一定阈值,会停止学习,最终得到正确的BP网络模型。
基于BP网络的实体识别方法由待识别实体的分块,对文本中划分好的语义块进行相似度计算,最后一步训练出实体识别模型。在实体识别过程中,训练BP 网络模型的流程如下图2-3所示:
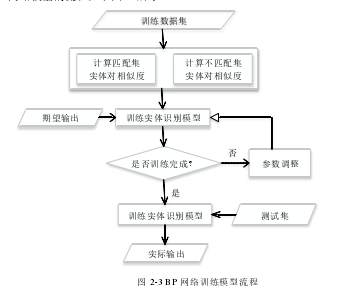
...........................
第三章 基于神经网络的电子病历实体识别 ............................. 22...........................
3.2 基于 CRF 的电子病历实体识别 ...................... 24
3.3 基于 BiLSTM-CRF 的电子病历实体识别 .............................. 24
第四章 实验结果与分析 ........................... 29
4.1 数据集 .............................. 29
4.2 实体识别评价指标................................. 30
4.3 实验设置 .................................. 31
第五章 总结与展望 ..................................... 38
5.1 本文的工作总结 .............................. 38
5.2 展望 ..................................... 39
第四章 实验结果与分析
4.1 数据集
本文实验所用的数据由以下三部分组成:
(1)来自CCKS2018电子病历实体识别评测任务公开发布的数据集。评测任务发布的中文电子病历数据集总共六百(600)份电子病历文档。
(2)来自39健康网(http://disease.39.net/)的健康信息以及问答,包括内科、外科、儿科、神经科、妇科等等13个类别的100万条问答,用来预训练词向量;
(3)39健康网爬下来的数据集中选取“儿科”类的1000个问答进行手工标注,加上评测数据的基础上扩充的数据集,即从IDC词典里选取手术和独立症状类的实体并将他们与评测数据里的手术和独立症状描述类的实体替换;
以下CCKS2018评测提供的数据集称第一组训练数据(data1),手工标注的数据、评测的数据、评测数据基础上扩充的数据集称为第二组数据(data2)。其中,实验按照8:2的比例将每组数据集划分为训练集和测试集。下表4-1是CCKS2018评测提供的600份文档包含的五类实体数量统计:
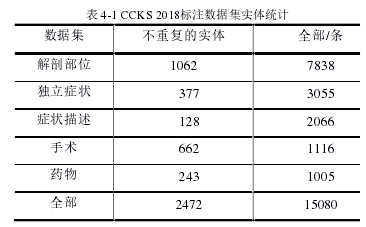
.........................
第五章 总结与展望
5.1 本文的工作总结
本文首先介绍了本文课题的研究背景及其研究意义和支撑,阐述了中文电子病历实体识别任务的紧迫性及其研究现状。与通用命名实体识别相比,电子病历实体识别人物存在的困难以及电子病历实体的语言特征。
其次,对目前被广泛应用的几种主流命名实体识别方法及其工作原理和在命名实体识别任务上的应用进行了简要的介绍,即基于统计和基于深度学习的方法。
进一步,对本文研究课题—中文电子病历实体识别模型开展了研究。首先采用 CRF 模型进行了识别并将此模型作为本文实验的基线系统用来跟其他实验的识别效果进行对比与分析。其次,利用前人的方法与经验,在 BiLSTM-CRF模型的基础上实现了基于 BiLSTM-CRF 的中文电子病历实体识别模型,实验设置及其行相关数据如 4.3,4.4 节所述。进一步,谷歌的 BERT 模型的基础上,实现了基于BERTbase的中文电子病历的实体识别模型。最后,将上述若干组实验进行对比与分析,验证了实验所采用的基于 BiLSTM-SRF 与 BERT 的方法在中文电子病历实体识别任务上的有效性。
5.1 本文的工作总结
本文首先介绍了本文课题的研究背景及其研究意义和支撑,阐述了中文电子病历实体识别任务的紧迫性及其研究现状。与通用命名实体识别相比,电子病历实体识别人物存在的困难以及电子病历实体的语言特征。
其次,对目前被广泛应用的几种主流命名实体识别方法及其工作原理和在命名实体识别任务上的应用进行了简要的介绍,即基于统计和基于深度学习的方法。
进一步,对本文研究课题—中文电子病历实体识别模型开展了研究。首先采用 CRF 模型进行了识别并将此模型作为本文实验的基线系统用来跟其他实验的识别效果进行对比与分析。其次,利用前人的方法与经验,在 BiLSTM-CRF模型的基础上实现了基于 BiLSTM-CRF 的中文电子病历实体识别模型,实验设置及其行相关数据如 4.3,4.4 节所述。进一步,谷歌的 BERT 模型的基础上,实现了基于BERTbase的中文电子病历的实体识别模型。最后,将上述若干组实验进行对比与分析,验证了实验所采用的基于 BiLSTM-SRF 与 BERT 的方法在中文电子病历实体识别任务上的有效性。