
第一章 引言
1.1 研究背景与意义
随着互联网进程的加快,互联网上的信息量也随之指数级的增涨,据中国互联网络信息中心的数据调查,2009 年我国网民数量为 3.38 亿人,国际出口带宽数为747,541.4Mbps,2014 年我国网民数量为 6.32 亿人,国际出口带宽数为 3,776,909Mbps,网民数量在五年内翻了一番,有接近一半的国人都成为了网络用户,国际出口带宽数也翻了五倍,到了 2018 年,我国网民规模已经达到了 8.02 亿之多,互联网普及率为也达到了 57.7%,国际出口带宽则为 8,826,302Mbps,较 14 年提升了 133%,由此可见,我国信息化进程在飞速的推进。
1.1 研究背景与意义
随着互联网进程的加快,互联网上的信息量也随之指数级的增涨,据中国互联网络信息中心的数据调查,2009 年我国网民数量为 3.38 亿人,国际出口带宽数为747,541.4Mbps,2014 年我国网民数量为 6.32 亿人,国际出口带宽数为 3,776,909Mbps,网民数量在五年内翻了一番,有接近一半的国人都成为了网络用户,国际出口带宽数也翻了五倍,到了 2018 年,我国网民规模已经达到了 8.02 亿之多,互联网普及率为也达到了 57.7%,国际出口带宽则为 8,826,302Mbps,较 14 年提升了 133%,由此可见,我国信息化进程在飞速的推进。
国际数据公司(IDC)的发布的研究报告,2008 年,也就是 10 年前全球产生的数据量为 0.49ZB(1ZB=1024EB,1EB=1024PB,1PB=1024TB,1TB=1024GB),一年之后,全球产生的数据量增长为 0.8ZB,两年之后,增长为 1.2ZB,三年后,增长为 1.82ZB,截止到 2012 年,人类现存的所有印刷材料所产生的数据量仅有 200PB,而全人类在整个历史中总共说过的话的数据量大约有 5EB。而在 IBM 的研究声明中,也可以看到在过去的两年中,产生了人类历史中 90%的数据。此外,IBM 还研究表明,全世界总共的数据规模在 2020 年之时将 会达到当年的 44 倍。由此,不难看出大数据时代已经来临了。
而随着大数据时代的来临,人们每天接触的数据量也在日益激增,如何从海量的数据中快速找到自己所需的数据,成为了迫切的需要,因此,文本摘要重新为人们所重视,文本摘要提取[1]的研究也由之前的无人问津变的炙手可热。
.............................
1.2 文本摘要提取的国外研究现状
20 世纪五十年代,美国 IBM 公司的 Luhn[15]就提出了自动文摘的概念,并据此进行了研究,他提出利用词频的信息来统计文本中的高频词,然后以高频词作为特征来加权,提取出文中的关键句作为摘要。这种方法在当时已经非常的超前了,但是也有一些比较大的缺憾,就是一些比较重要的低频词信息被忽略了。
20 世纪五十年代,美国 IBM 公司的 Luhn[15]就提出了自动文摘的概念,并据此进行了研究,他提出利用词频的信息来统计文本中的高频词,然后以高频词作为特征来加权,提取出文中的关键句作为摘要。这种方法在当时已经非常的超前了,但是也有一些比较大的缺憾,就是一些比较重要的低频词信息被忽略了。
20 世纪八十年代末,美国的学者们开始将统计方法和自然语言处理中的一些知识相结合,通过对文章的语法信息以及内容进行分析,来提取文本中的重要信息作为摘要。
20 世纪九十年代末,谷歌的两位创始人 Larry Page 和 Sergey Brin 从学术界用来评判论文重要性的方法——“论文引用次数”中获得灵感,建了评价网页重要性的方法PageRank[16],而之后的几年里,Mihalcea R 和 Tarau P 以此方法为基础,改进出了用以计算文本中句子重要性的方法 Text Rank[17],TextRank[18]算法将词视为“万维网上的节点”,根据词之间的共现关系来计算每个词的重要性,以此来计算文本中句子的值,得出文本的摘要。
20 世纪九十年代末,谷歌的两位创始人 Larry Page 和 Sergey Brin 从学术界用来评判论文重要性的方法——“论文引用次数”中获得灵感,建了评价网页重要性的方法PageRank[16],而之后的几年里,Mihalcea R 和 Tarau P 以此方法为基础,改进出了用以计算文本中句子重要性的方法 Text Rank[17],TextRank[18]算法将词视为“万维网上的节点”,根据词之间的共现关系来计算每个词的重要性,以此来计算文本中句子的值,得出文本的摘要。
21 世纪初期,密西根大学的 Gunes Erkan 和 Dragomir R Radev 提出了一种基于图论的自然语言处理方法[19],主要通过句子之间的相似度来对文本和词汇进行分类,并根据相似程度来为每个句子评分,最终根据评分,以一定的阈值将分数较高的句子作为文章的摘要句。
............................
第二章 相关知识介绍
2.1 抽取式文本摘要提取相关技术介绍
常用的文本摘要提取技术[43][44]通常是基于统计或基于规则的抽取式摘要,通过计算句子的权重或者计算句子之间的相似度等方法来抽取文本中的摘要句,本文中,我们选择这几种方法与基于深度学习的方法做对比。
2.1.1基于 TF-IDF 的文本摘要提取技术
TF-IDF 是一种非常常见的基于统计的方法,TF 为词频,即文本中一个词出现的次数;IDF 为逆文档频率,是对词语普遍重要性的一种度量。TF-IDF 算法的主要思想是:如果某个词语在某一特定文本中的词频很高,但是它在其他文本中的频率却很低,就可以说明这个词有很好的类别区分作用,那么它的权重也就越高,也就越关键。相反,如果在某一特定文本中的频率很高,但是在其他文本中的频率也很高,这个词的权重就会很低,也就不那么关键。TF-IDF 的具体计算方式如公式(2-1)所示:

.............................
2.2文本向量表示相关技术介绍
文本向量化表示就是将文本转化为计算机能够直接进行处理的格式化数据,而这一步也是深度学习输入数据的必要一步和关键一步。本文所用的文本向量化表示工具为Word2Vec。
............................
第二章 相关知识介绍
2.1 抽取式文本摘要提取相关技术介绍
常用的文本摘要提取技术[43][44]通常是基于统计或基于规则的抽取式摘要,通过计算句子的权重或者计算句子之间的相似度等方法来抽取文本中的摘要句,本文中,我们选择这几种方法与基于深度学习的方法做对比。
2.1.1基于 TF-IDF 的文本摘要提取技术
TF-IDF 是一种非常常见的基于统计的方法,TF 为词频,即文本中一个词出现的次数;IDF 为逆文档频率,是对词语普遍重要性的一种度量。TF-IDF 算法的主要思想是:如果某个词语在某一特定文本中的词频很高,但是它在其他文本中的频率却很低,就可以说明这个词有很好的类别区分作用,那么它的权重也就越高,也就越关键。相反,如果在某一特定文本中的频率很高,但是在其他文本中的频率也很高,这个词的权重就会很低,也就不那么关键。TF-IDF 的具体计算方式如公式(2-1)所示:
.............................
2.2文本向量表示相关技术介绍
文本向量化表示就是将文本转化为计算机能够直接进行处理的格式化数据,而这一步也是深度学习输入数据的必要一步和关键一步。本文所用的文本向量化表示工具为Word2Vec。
Word2Vec 是谷歌发明的一种开源的词嵌入工具,该工具能够生成词向量,然后通过所生成的词向量,我们可以很好的对词与词之间的相似性进行度量。在 Word2Vec 出现之前,人们在进行自然语言处理任务之时,常使用 One-Hot Encoder 的方式来进行向量化,就是用“0”和“1”来表示一个词。假如有这么一段话,“我 喜欢 学习 新技术”中,“我”就可以表示为[1,0,0,0],“喜欢”为[0,1,0,0],“学习”为[0,0,1,0],“新技术”为[0,0,0,1],但是这样的话,各个向量之间相互独立,看不出有什么关系,而且向量维度的大小取决于语料库中字词的多少,如果字词数量过大,就容易使这个矩阵变的过于稀疏,继而造成维度灾难。而 Word2Vec 的诞生很好的解决了这个问题,Word2Vec 能够将 One-Hot Encoder 转化成低纬度的连续值,也就是稠密向量,而且向量中意思相近的词也会被映射到向量空间中的相近位置。Word2Vec 有两种训练方式,分别是 CBOW(Continuous Bag of Words)模型以及 Skip-Gram 模型。
........................
3.1 基于传统的文本摘要抽取技术的实现 ........................................... 16
3.1.1 基于 TF-IDF 的文本摘要抽取的实现 ...................................... 16
3.1.2 基于 TextRank 的文本摘要抽取的实现 .................................... 17
第四章 文本信息提取系统的设计与实现 ................................................ 38
4.1 系统设计 ........................ 38
4.2 系统设计 .................................. 38
第五章 总结与展望 .............................. 44
5.1 总结 ............................... 44
5.2 展望 .................................... 44
第四章 文本信息提取系统的设计与实现
4.1 系统设计
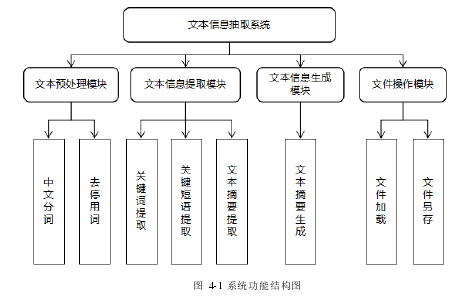
文本信息提取系统从功能结构上可以分为文本预处理模块,文本提取模块,文本生成模块以及文件操作模块。其中,文本预处理模块包括中文分词和去停用词功能;文本提取模块包括传统的关键词抽取,关键短语抽取以及文本摘要抽取模块;文本生成模块包括了基于深度学习的文本摘要生成模块,可以用以生成文本的标题;文件操作模块包含文件加载操作和文件另存操作,方便用户直接对文本进行操作。系统功能结构图如图 4-1 所示。
文本信息提取系统从功能结构上可以分为文本预处理模块,文本提取模块,文本生成模块以及文件操作模块。其中,文本预处理模块包括中文分词和去停用词功能;文本提取模块包括传统的关键词抽取,关键短语抽取以及文本摘要抽取模块;文本生成模块包括了基于深度学习的文本摘要生成模块,可以用以生成文本的标题;文件操作模块包含文件加载操作和文件另存操作,方便用户直接对文本进行操作。系统功能结构图如图 4-1 所示。
..............................
第五章 总结与展望
5.1 总结
随着互联网进程的加快,大数据时代已经到来了,与海量数据相对应的是信息抽取相关技术也越来越被更多的学者所关注,而信息抽取中,最为重要,实用价值也最高的,当属文本摘要抽取,而海量的数据也为文本摘要生成的产生和发展提供了强有力的保证,本文针对各种文本摘要生成技术,也展开了深入的研究,并借助该研究内容以及相关的准备工作,设计并实现了文本信息抽取系统。本文的工作总结如下:
5.1 总结
随着互联网进程的加快,大数据时代已经到来了,与海量数据相对应的是信息抽取相关技术也越来越被更多的学者所关注,而信息抽取中,最为重要,实用价值也最高的,当属文本摘要抽取,而海量的数据也为文本摘要生成的产生和发展提供了强有力的保证,本文针对各种文本摘要生成技术,也展开了深入的研究,并借助该研究内容以及相关的准备工作,设计并实现了文本信息抽取系统。本文的工作总结如下:
1) 通过充分的调查以及国内外期刊论文的阅读,对文本摘要抽取领域有了比较深入的了解,也对文本摘要抽取的发展历程有了清晰的概念,为之后的研究指明了主题和方向。同时对一些传统的方法进行了相关的学习以及实现,了解了传统方法的优点以及其局限性;
2) 数据集的选择和词向量的训练。由于目前的中文文本摘要语料库数量相对较少,而深度学习算法对语料库的规模依赖程度相对较高,因此选择了哈尔滨工业大学的LCSTS 数据集来作为本文的训练集和测试集,该语料库有接近 70 万条新闻正文和其对应的标题,比较适合用来做短文本摘要生成。由于选择的数据集是新闻数据集,因此,本文选择了搜狗实验室的新闻数据集来训练词向量,该数据集大小为 250 万条,生成的词向量规模为 399502 个词语,每个词语为 300 维的向量;
2) 数据集的选择和词向量的训练。由于目前的中文文本摘要语料库数量相对较少,而深度学习算法对语料库的规模依赖程度相对较高,因此选择了哈尔滨工业大学的LCSTS 数据集来作为本文的训练集和测试集,该语料库有接近 70 万条新闻正文和其对应的标题,比较适合用来做短文本摘要生成。由于选择的数据集是新闻数据集,因此,本文选择了搜狗实验室的新闻数据集来训练词向量,该数据集大小为 250 万条,生成的词向量规模为 399502 个词语,每个词语为 300 维的向量;
3) 基于深度学习的文本摘要生成技术研究。详细介绍了两种文本摘要生成技术的研究,Seq2Seq+Attention 机制模型在 Encoder 和 Decoder 中都采用了 LSTM,充分利用了上下文的信息,提高了生成的摘要的语义相关度。而基于 Transformer 的文本摘要生成模型的构建中,本文采用了 6 个 Encoder 和 Decoder 来建模,最大化的提升生成摘要和原文的语义相关度,经测试,两种模型相对于传统的方法,都有着较好的表现;
4) 文本信息抽取系统的设计与实现。借助文本摘要的研究以及在研究中对相关知识的实现,设计并实现了文本信息抽取系统,该系统包含了文本预处理,文本信息提取,文本信息生成,文件操作等模块。此外,针对该系统的性能,与开源的工具做了简单的对比,实验结果表明,该系统拥有良好的实际应用价值。
参考文献(略)
参考文献(略)