
第一章 绪论
1.1 研究背景与意义
随着互联网的技术更新,社交网络在人们的日常生活中愈发重要,许多社交网络媒体应运而生并快速发展。在诸类社交网站中,新浪微博由于操作简单、传播迅速、灵活度高等特点,从传统社交网络中脱颖而出,已成为最普及、最重要的社交服务网站之一,成为广大网民共享、获取和传播信息的一种新的互动形式。它极大地方便了人们的交流互动,成为人们在线交流和传播情感的主要平台,用户可以在微博上自由的发表个人的意见和观点,宣泄自己的情感。据第 43 次《中国互联网络发展状况统计报告》[1]显示,截至 2018 年 12 月,中国网民规模达到8.29 亿,全年新增网民 5653 万,互联网普及率达 59.6%,比 2017 年底增加了3.8 个百分点。截至 2018 年 12 月,新浪微博月活跃用户 4.62 亿,日均活跃用户达 2 亿[2]。因此,新浪微博作为国内信息获取的主要来源,具有重要的研究意义。
然而,另一方面,随着社交媒体的爆炸式增长,社交网络给人们带来便利的同时,也产生了许多异常用户。这些用户将其作为牟取利益的平台,通过社交网络在社交媒体中以语言文字、图片、视频等形式发布大量不利于民族团结、不利于社会稳定、恶意攻击、辱骂他人等的不良内容。国外的 Twitter、Facebook,国内的网易、新浪等在线社交系统的许多用户经常受到各种异常用户的困扰,这不仅扰乱了社交平台的正常营销和推广,违反了平台管理规范,侵犯了公众的利益,污染了社交网络环境,还对社会造成了不良的影响。因此,识别和检测社交网络中的发表这些不良内容的用户对净化网络环境、维持网络秩序、提高用户上网体验、促进社会的和谐发展等具有重要作用。
............................
1.2 国内外研究现状
现有对不良言论用户的识别多是从用户发布的文本内容进行检测的,而且这些文本内容多是敏感性、攻击性、辱骂性的。目前国内针对不良言论用户的研究很少,参考文献也比较少。不良言论用户是本文的重点研究对象,针对此类用户的研究,将重点放在了该用户发表的言论上。
3.1 研究的问题 .................................... 171.2 国内外研究现状
现有对不良言论用户的识别多是从用户发布的文本内容进行检测的,而且这些文本内容多是敏感性、攻击性、辱骂性的。目前国内针对不良言论用户的研究很少,参考文献也比较少。不良言论用户是本文的重点研究对象,针对此类用户的研究,将重点放在了该用户发表的言论上。
近年来,诸多专家学者对社交媒体安全性的研究有了长足的发展,与此相关的一个方面是检测博客、微博、论坛等社交网络中以各种形式出现的具有攻击性、敏感性、辱骂性、煽动性和仇恨性的不良文本。现有对这个问题的研究,大多数都是使用黑名单、规则表达式和分类技术来过滤不良内容。文献[3]手工编写了一个辱骂性词典,里面包含了不同程度的单词短语,并且词典中给每一个词汇分配了权重。Gitari 等人[4]建立了一个包含仇恨动词的词典,用于检测仇恨性的言论。文献[5]认为一个句子中含有黑名单列表中的词不一定就是不良的,在使用黑名单列表的基础上加入了编辑距离,检测故意拼写错误的词。文献[6]将不良言论检测问题视为词义消歧问题,使用基于规则的方法生成特征,分类精确度达到 94%,但由于只考虑了浅层的句法,无法检测到更多的语言模式,导致召回率仅为 60%。Silva 等人[7]根据句子结构构造了一个基本表达式来检测 Whisper和 Twitter 中的仇恨言论,并采用人工的方式对这些言论进行了细粒度的划分。Davidson 等人[8]将 Twitter 中的推文标记为三类:仇恨言论、攻击性言论和两者都不是,然后使用逻辑回归的方法对其进行分类,但受到主观意愿的影响,导致这些言论的分类有一定的误判,并且无法检测出一些新出现的术语。为了弥补以往的句子攻击检测方法中存在的不足,文献[9]在考虑了词汇特征和句法特征的基础上,提出了一种基于攻击性词汇和句法结构的句子层次分析的新方法(LSF),实验结果表明,LSF 句子攻击预测和用户攻击估计算法在精度、召回率和 F 值方面均优于传统学习的方法。Sood 等人[10]将情感分析与仇恨言论相结合,先采用一种专门检测负极性的分类器对帖子进行情感分类,然后再对在仇恨言论进行分类。基于黑名单和规则表达式的方法,严重依赖于黑名单列表和规则,并且无法检测出一些混淆的字词或短语,同时还会影响言论和表达的自由;基于分类的技术,对注释数据较为依赖,耗费了大量的人力物力,并且在面对新出现的不良术语时,显得无能为力。
...............................
...............................
第二章 相关知识与理论技术
2.1 社交网络中不良言论用户相关概念
2.1.1 社交网络异常用户分类体系
社交网络中的用户分为正常用户和异常用户。异常用户是指在社交网络中,个人或群体的行为不符合正常用户模式定义的特征行为或与其同龄人以明显不同的方式进行的互动,其表现为在同一结构中与其他用户行为不同的活动。
文献[28]根据文本表达内容以及目的(如骚扰、广告、引导舆论走向、欺诈等)的不同,将社交网络中的异常用户划分为了 7 个类别,分类体系如下图 2-1所示。
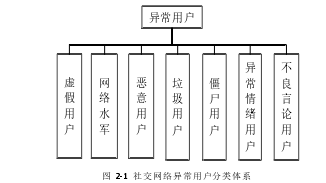
在对社交网络诸多异常用户进行分析调研之后,本文发现研究最多的几类异常用户多是僵尸用户、垃圾用户、恶意用户、虚假用户等,对最后一类用户即不良言论用户的研究很少,此类用户在社交平台传递不良信息,严重污染了社会风气,破坏了民族团结,危害社会稳定和长治久安。因此,准确的识别出此类用户具有重要现实意义。基于此,本文对社交网络中的不良言论用户展开了研究
..........................
2.2 特征选择
特征选择是一种降维技术,通过去除不相关的、冗余的或噪声特征,按照一定的选取规则,从原始特征中选取相关特征的一个子集的过程。将文本进行向量空间表示后,得到的向量维数较高且数据稀疏,因此需要采用特征选择方法解决这些问题,同时提高学习精度、降低计算成本,使其具有更好的学习效果。下面对几种常用的特征选择方法进行介绍。
2.2.1 文档频率
文档频率指的是整个文本中包含的指定特征项的文本数[32-33]。通过该方法进行特征选择的基本思想是:计算出特征词在每个类别文档中的文档频率,全部计算完后,根据给定的阈值将文档频率低于阈值的去掉,对保留的特征词按照频率大小进行降排序,并从中选取一定的特征词作为特征。
2.2.2 互信息
互信息是指系统中当一个变量出现时,另一个变量不确定性的减少量,体现了两个变量间的关联程度[34-35]。为了进行更清楚地描述,首先介绍一些相关的定义。

...........................
第三章 社交网络不良言论用户识别 ............................... 17
2.1 社交网络中不良言论用户相关概念
2.1.1 社交网络异常用户分类体系
社交网络中的用户分为正常用户和异常用户。异常用户是指在社交网络中,个人或群体的行为不符合正常用户模式定义的特征行为或与其同龄人以明显不同的方式进行的互动,其表现为在同一结构中与其他用户行为不同的活动。
文献[28]根据文本表达内容以及目的(如骚扰、广告、引导舆论走向、欺诈等)的不同,将社交网络中的异常用户划分为了 7 个类别,分类体系如下图 2-1所示。
在对社交网络诸多异常用户进行分析调研之后,本文发现研究最多的几类异常用户多是僵尸用户、垃圾用户、恶意用户、虚假用户等,对最后一类用户即不良言论用户的研究很少,此类用户在社交平台传递不良信息,严重污染了社会风气,破坏了民族团结,危害社会稳定和长治久安。因此,准确的识别出此类用户具有重要现实意义。基于此,本文对社交网络中的不良言论用户展开了研究
..........................
2.2 特征选择
特征选择是一种降维技术,通过去除不相关的、冗余的或噪声特征,按照一定的选取规则,从原始特征中选取相关特征的一个子集的过程。将文本进行向量空间表示后,得到的向量维数较高且数据稀疏,因此需要采用特征选择方法解决这些问题,同时提高学习精度、降低计算成本,使其具有更好的学习效果。下面对几种常用的特征选择方法进行介绍。
2.2.1 文档频率
文档频率指的是整个文本中包含的指定特征项的文本数[32-33]。通过该方法进行特征选择的基本思想是:计算出特征词在每个类别文档中的文档频率,全部计算完后,根据给定的阈值将文档频率低于阈值的去掉,对保留的特征词按照频率大小进行降排序,并从中选取一定的特征词作为特征。
2.2.2 互信息
互信息是指系统中当一个变量出现时,另一个变量不确定性的减少量,体现了两个变量间的关联程度[34-35]。为了进行更清楚地描述,首先介绍一些相关的定义。
...........................
第三章 社交网络不良言论用户识别 ............................... 17
3.2 不良言论用户识别总体设计 ....................................... 18
3.3 基于多特征融合的不良言论检测 ........................................... 19
第四章 实验以及结果分析 ..................................... 30
4.1 不良言论检测 .................................. 30
4.1.1 实验环境与数据 ........................................ 30
4.1.2 评价指标 ................................. 30
第五章 总结与展望 ............................... 37
5.1 研究工作总结 ...................................... 37
5.2 今后研究方向 .............................. 37
第四章 实验以及结果分析
4.1 不良言论检测
4.1.1 实验环境与数据
实验环境在一台内存为 8GB、CPU 为 Intel core i5 3230M,2.5GHz、硬盘 500G的 64 位的 Windows 7 系统下进行,开发工具为 PyCharm Community Edition 3.3,使用 keras 库通过底层调用 Tensorflow 框架的方式实现 CNN、LSTM 等网络的构建,实验数据如表 4-1 所示。所有数据集按照 8:1:1 的比例分配给训练集、验证集和测试集。
4.1 不良言论检测
4.1.1 实验环境与数据
实验环境在一台内存为 8GB、CPU 为 Intel core i5 3230M,2.5GHz、硬盘 500G的 64 位的 Windows 7 系统下进行,开发工具为 PyCharm Community Edition 3.3,使用 keras 库通过底层调用 Tensorflow 框架的方式实现 CNN、LSTM 等网络的构建,实验数据如表 4-1 所示。所有数据集按照 8:1:1 的比例分配给训练集、验证集和测试集。

...........................
第五章 总结与展望
5.1 研究工作总结
针对社交网络不良言论用户的识别研究,本文将重点放在用户的言论检测上。首先使用网络爬虫采集微博用户数据,得到原始的用户言论数据;原始的数据存在大量噪声,直接进行分类的效果不好,本文通过分析微博数据中不良言论的特点,提出了针对不良言论的数据预处理操作,其中包括文本去噪、分词、去停用词等,然后提取文本特征进行不良言论检测。在此基础上,对微博不良言论用户进行识别。本文主要研究内容如下:
(1)通过分析社交网络用户的属性及行为特征,针对目前研究的异常用户概念冗余、定位模糊等问题,给出了社交网络中异常用户的定义及其划分依据,将异常用户划分为七类,并给出了本文的主要研究对象—不良言论用户。
(2)分析了不良言论文本的特点,提出了针对不良言论检测的改进的文本预处理流程,利用词向量相似度计算的方式,对本文采集的不良言论进行不良词的扩充,构建了一个高质量的不良词典。
(3)通过对从社交网络中获取的不良言论数据的特点进行分析,发现不良言论具有变形字使用较多、负面倾向明显、语义复杂等特点,提出了基于Bi-gram特征、情感特征和语义特征相融合的特征提取方法,对不良言论进行检测,在此基础上,利用不良言论检测模型对微博不良言论用户进行识别。
(4)利用本文提出的方法在本文构建的不良言论数据集及不良言论用户数据集上进行了实验,实验结果表明,本文提出的方法对提高不良言论的检测准确率及不良言论用户的识别准确率上有一定的帮助。
参考文献(略)