
第 1 章 引言
1.1研究背景
随着科学的逐步发展,人工智能及大数据时代的来临,自然语言处理作为能够使机器处理人类语言的一门学科,其重要性已经在日常生活等各个方面中体现出来,比如苹果 iOS 系统的 Siri,小米的小爱同学,这些人工智能的智能问答系统已经在日常生活中有了很大的应用。
自然语言处理一般分为词法分析、句法分析、语义分析这三个阶段,这三个阶段相互独立却又相辅相成[1]。第一阶段为词法分析,在这个阶段中,主要是针对词语进行处理,如分词、词性标注、命名实体识别等。第二个阶段为句法分析,句法分析主要针对句子进行处理,其需要第一阶段中词性标注的结果来对句子进行分析,最终得到句法分析树。第三阶段为语义分析,前两个阶段的输出结果可以为语义分析提供基础。相比于英语、汉语的自然语言处理,哈萨克语自然语言处理起步较晚,目前哈萨克语自然语言处理方面,词法分析已经基本完成,在句法分析方面也有了一定的研究成果。
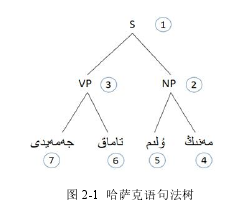
句法分析是将一个句子分析成为一个句法分析树[1],通过句法分析树可以看出一个句子由哪些词语构成短语,再由词语与短语、或者短语与短语再形成短语,最后再由短语形成句子,这样的树形结构。句法分析得到的句法树虽然不能作为解决自然语言处理问题的最终结果,但是其能够为自然语言处理的其他领域,比如机器翻译、信息检索等提供基础。
.............................
1.2研究意义
哈萨克语与汉语不同,在词语方面,哈萨克语动词词尾有很多的变化,这些变化能够表示时态的变化[10],而汉语中没有这样复杂的结构,其语法规则也与汉语不同,在汉语的句子表述中,一般采用“主语-谓语-宾语”这样的结构,而哈萨克语的句子表述则采用“主语-宾语-谓语”的结构。因此,哈萨克语的特性决定了其语言处理方面的研究与汉语相比有些许不同。
哈萨克语句法分析虽然不是哈萨克语自然语言处理领域研究的最终目的,但是其在自然语言处理的地位非常重要[17]。目前哈萨克语句法分析主要研究的是短语句法分析,短语句法分析主要针对句子中各个成分之间的关系,也被称为成分句法分析。对哈萨克语句法分析的研究能够为建立哈萨克语句法树库、机器翻译等领域提供语料基础。不仅如此,对句法分析的研究也可以为哈萨克语自然语言处理的其他领域提供一定的研究基础,例如对哈萨克语语义方面的研究提供一定的技术支持和研究基础。句法分析所得到的句法树也可以用于基于句法的机器翻译系统,在信息检索中可以用于分析输入的句子,在问答系统中可以用于处理输入输出的句子。
随着社会的不断发展,对哈萨克语展开研究的需要越来越多,对哈萨克语自然语言处理的研究是为新疆的繁荣发展、为中亚各国的文化交流做出贡献。
..........................
...........................
1.2研究意义
哈萨克语与汉语不同,在词语方面,哈萨克语动词词尾有很多的变化,这些变化能够表示时态的变化[10],而汉语中没有这样复杂的结构,其语法规则也与汉语不同,在汉语的句子表述中,一般采用“主语-谓语-宾语”这样的结构,而哈萨克语的句子表述则采用“主语-宾语-谓语”的结构。因此,哈萨克语的特性决定了其语言处理方面的研究与汉语相比有些许不同。
哈萨克语句法分析虽然不是哈萨克语自然语言处理领域研究的最终目的,但是其在自然语言处理的地位非常重要[17]。目前哈萨克语句法分析主要研究的是短语句法分析,短语句法分析主要针对句子中各个成分之间的关系,也被称为成分句法分析。对哈萨克语句法分析的研究能够为建立哈萨克语句法树库、机器翻译等领域提供语料基础。不仅如此,对句法分析的研究也可以为哈萨克语自然语言处理的其他领域提供一定的研究基础,例如对哈萨克语语义方面的研究提供一定的技术支持和研究基础。句法分析所得到的句法树也可以用于基于句法的机器翻译系统,在信息检索中可以用于分析输入的句子,在问答系统中可以用于处理输入输出的句子。
随着社会的不断发展,对哈萨克语展开研究的需要越来越多,对哈萨克语自然语言处理的研究是为新疆的繁荣发展、为中亚各国的文化交流做出贡献。
..........................
第 2 章 基于转移的句法分析
2.1 基于转移的句法分析介绍
句法分析的基本方法主要包括基于图和基于转移的两种基本方法,在本文中句法分析采用的方法为基于转移的方法,本小节主要对基于转移的方法进行介绍。
基于转移的方法在思想上来源于自动机,与基于图的方法在解空间方面相比较,在一定程度上减小了解空间,其主要思想为[17]:设定一个转移系统,由初始状态开始,根据系统进行相应的转移操作,系统进入中止状态后,得出相应的动作序列。
2.1 基于转移的句法分析介绍
句法分析的基本方法主要包括基于图和基于转移的两种基本方法,在本文中句法分析采用的方法为基于转移的方法,本小节主要对基于转移的方法进行介绍。
基于转移的方法在思想上来源于自动机,与基于图的方法在解空间方面相比较,在一定程度上减小了解空间,其主要思想为[17]:设定一个转移系统,由初始状态开始,根据系统进行相应的转移操作,系统进入中止状态后,得出相应的动作序列。
基于转移的方法在实现时需要设定三个区域[19][20],缓冲区、堆栈区、历史动作区,首先将输入的句子放入相应的缓冲区之中,然后按照一定的转移规则,将输入句子的词语按照一定的转移操作进行相应的操作,例如将缓冲区的内容放入堆栈,或者将堆栈区的内容弹出,进行操作后再推入堆栈,在操作过程中会构成句法树的子树并标记相应的句法标记,然后生成以一定规则形成的动作序列。
2004 年 Niver 提出了 arc-standard 的基于转移的方法[21],该方法从左向右解析一个句子,使用堆栈来存储部分构建的语法结构和一个缓冲区用来存储将要输入的信息。解析算法通过分数在每个配置中选择一个动作。在 arc-standard方法中,依赖关系树是自底向上构建的,因为头的右依赖关系仅在完全解析依赖关系下的子树之后才被附加,只有当所有的单词都处理完毕,并且堆栈中有且仅有一个子树的时候,该句法分析才完全结束。
2004 年 Niver 提出了 arc-standard 的基于转移的方法[21],该方法从左向右解析一个句子,使用堆栈来存储部分构建的语法结构和一个缓冲区用来存储将要输入的信息。解析算法通过分数在每个配置中选择一个动作。在 arc-standard方法中,依赖关系树是自底向上构建的,因为头的右依赖关系仅在完全解析依赖关系下的子树之后才被附加,只有当所有的单词都处理完毕,并且堆栈中有且仅有一个子树的时候,该句法分析才完全结束。
...........................
2.2 自底向上的句法分析
基于转移的方法一般分为自底向上和自顶向下的方法,该方法的本质是将待分析的句法树输入后,按照一定的规则,将相应的操作转化为动作序列。
基于转移的句法分析模型最典型的是自底向上的 Shift-Reduce 模型,在 2005年,Sagae 和 Lavie 提出了用于解决短语句法分析的 Shift-Reduce 方法[22],该方法采用堆栈来保存部分输出,使用队列来保存句子中下一个要处理的单词。
SHIFT:将队列中的单词转移到堆栈 S 中成为堆栈 S 的栈顶元素。
基于转移的方法一般分为自底向上和自顶向下的方法,该方法的本质是将待分析的句法树输入后,按照一定的规则,将相应的操作转化为动作序列。
基于转移的句法分析模型最典型的是自底向上的 Shift-Reduce 模型,在 2005年,Sagae 和 Lavie 提出了用于解决短语句法分析的 Shift-Reduce 方法[22],该方法采用堆栈来保存部分输出,使用队列来保存句子中下一个要处理的单词。
SHIFT:将队列中的单词转移到堆栈 S 中成为堆栈 S 的栈顶元素。
REDUCE-UNARY-XX:用一元文法规则对堆栈 S 的栈顶元素进行拓展,拓展完成后得到的新子树将推入到堆栈 S 中成为新的栈顶元素,新子树的句法标记是 XX 类型(其中 XX 是非终端符号,例如 NP,VP,PP);
REDUCE-LEFT-XX:采用二元文法对堆栈 S 栈顶的两个元素进行拓展,拓展完成后得到的新子树将推入到堆栈 S 中成为新的栈顶元素,新子树的句法标记是 XX 类型,LEFT 表示选择左侧的孩子为中心词。
REDUCE-RIGHT-XX:采用二元文法对堆栈 S 栈顶的两个元素进行拓展,拓展完成后得到的新子树将推入到堆栈 S 中成为新的栈顶元素,新子树的句法标记是 XX 类型,RIGHT 表示选择右侧孩子为中心词。
.............................
3.1 神经网络句法分析相关技术介绍................................ 11
3.1.1 神经网络在句法分析上的应用............................... 11
3.1.2 堆栈长短期记忆网络(Stack-LSTM) ................................... 12
第 4 章 生成模型哈萨克语句法分析................................... 25
4.1 判别模型与生成模型........................... 25
4.2 重排序与候选树............................ 28
第 5 章 总结与展望............................... 31
5.1 总结................................ 31
5.2 展望...................................... 32
第 4 章 生成模型哈萨克语句法分析
4.1 判别模型与生成模型
在有监督学习当中,进行训练的目的就是得到一个模型,通过这个模型,能够将给定的输入数据输出相应的数据。监督学习的方法分为两种,一种被称为生成方法(generative approach),另一种被称为判别方法(discriminative model)[42]。
生成方法是从训练数据中学习到联合概率分布 P(X,Y),然后求出条件概率分布 p(Y|X)作为预测的模型[43],生成方法学习到的模型为生成模型(generative model),该方法训练得到的模型表示了在输入 X 的情况下,能够得到输出 Y 的生成关系。
判别方法则是通过训练数据直接学习决策函数 f(x)或者条件概率分布 p(X|Y)作为预测的模型,判别方法学习到的模型为判别模型(discriminative model),该方法训练得到的模型能够根据输入 X 预测出相应的输出 Y。
生成方法与判别方法的关注点不同,生成方法更注重输入 X 与输出 Y 的生成关系,能够还原出联合概率分布 P(X,Y),而判别式方法关注的则是输入 X 怎样预测出输出 Y,不考虑其内在关系。
........................
第 5 章 总结与展望
5.1 总结
本文针对哈萨克语的句法分析进行研究,句法分析的方法大体上分为两种,基于转移的方法和基于图的方法,本文采用的方法为基于转移的方法。基于转移的方法需要三个区,一个用于存储输入句子的缓冲区,一个用于存储分析出的部分句法树的堆栈区,一个用于存储动作序列的历史动作区。该方法将句法分析的难点之一解空间巨大的问题,在一定程度上有了改善,因为基于转移的方法将一个句子按照一定的规则,会生成相应的动作序列,其问题也由如何构成一个句法树简化成为了如何预测出一个动作序列,减小了问题的复杂度,将一个结构化的问题转化为了一个序列化的问题。
本文采用由三个不同的长短期记忆网络构成的句法分析器,分别对应转移方法中需要的三个区,堆栈区、缓冲区和历史动作区,将基于转移的方法与神经网络相结合,充分发挥神经网络在序列化模型上捕捉信息的优势。三个长短期记忆网络会传到一个 softmax 层中,softmax 层将会根据当前时刻的信息计算得出当前所采取动作序列的概率。
本文采用由三个不同的长短期记忆网络构成的句法分析器,分别对应转移方法中需要的三个区,堆栈区、缓冲区和历史动作区,将基于转移的方法与神经网络相结合,充分发挥神经网络在序列化模型上捕捉信息的优势。三个长短期记忆网络会传到一个 softmax 层中,softmax 层将会根据当前时刻的信息计算得出当前所采取动作序列的概率。
在转移方法上,本文将自顶向下的方法与中序遍历句法树的方法相比较,实验结果证明,中序遍历句法树的方法确实要优于自顶向下的方法。中序遍历句法树的方法能够更好地捕捉句子中的全局信息和局部信息,也更加符合人脑再处理句子信息时的思考方式。
参考文献(略)
参考文献(略)