本文是一篇计算机论文,本文基于生成式模型T5构建统一的生成式模型框架,将问题文本和抽取的三元组文本作为模型输入,通过前缀标记法联合逻辑形式和答案编解码,同时生成问题对应的逻辑形式和答案,构造代价函数联合二者生成最终答案。
1绪论
1.1课题背景
问答系统是计算机科学中一个有着悠久历史的研究领域,目标是以自然语言提供准确的答案以响应用户的问题。早在1961年,Green[1]开发了第一个问答系统,该系统能回答关于单季美国职棒大联盟比赛的问题。然而早期的问答系统主要是专家系统,依赖大量的规则或模板。随着技术的发展,问答系统转向了基于信息检索的研究,基于信息检索的问答系统依靠关键字匹配和信息抽取来分析问题的语义并从相关文档中提取答案,但是往往只能回答简单重复的问题,缺乏可解释性。近些年,随着语义网的发展,积累了大量精心设计的结构化数据,以知识图谱的形式出现在网络上,如Yago[2]、DBpedia[3]和Freebase[4],基于这些知识图谱构建具备推理能力的知识图谱问答系统已经成为了问答系统领域最热门的研究方向之一。
在基于知识图谱的问答系统中,包括知识图谱和问答系统两部分。其中资源描述框架(RDF)[5]是知识图谱的基石,RDF提供了一个统一的标准,以<主语、关系、宾语>(SPO)三元组形式描述现实世界中的实体以及实体之间的关系,每个SPO三元组表示知识图谱中的一条知识,大型的知识图谱通常包含数十亿个相互关联的三元组,为问答系统提供了丰富可靠的知识源。另外在RDF构成知识图谱的基础上,用户需要逻辑语言操作查询知识图谱,SPARQL[6]专门用于访问和操作RDF数据,是语义网的核心技术之一。基于知识图谱的问答系统核心任务是跨越自然语言问题到可查询知识图谱的逻辑形式之间的鸿沟,将自然语言问题转化SPARQL、λ-DCS[7]、S-expression[8]等逻辑形式,或基于信息检索直接抽取知识图谱,最终目标是以自然语言形式返回准确的答案。
...............................
1.2本文工作及贡献
在对知识图谱问答领域国内外相关工作进行调研后,本文基于现有研究方法的优缺点,提出了一种联合逻辑形式解析和答案生成的知识图谱问答方法,实现了基于知识图谱生成自然语言问题对应答案的完整流程,同时将该方法应用到中医领域,构建了一个融合中医网站信息、开源知识图谱和临床病例等多源数据的中医知识图谱问答系统。
具体来说,本文将KBQA任务抽象为文本转化问题,包含信息检索和语义解析两个阶段:在信息检索阶段,将结构化的知识图谱文本化为构造知识图谱的三元组文本,将三元组文本按一定顺序和数量组织为相应的文本库,利用BM25[9]或者DPR[10]等信息抽取方法抽取和输入问题相关的文本,然后基于Bert进一步抽取其中排序靠前的三元组文本;在语义解析阶段,将输入的问题和对应抽取的三元组文本连接在一起作为生成式模型的输入,利用生成式模型同时生成自然语言问题对应的逻辑形式和答案。这里的生成式模型基于T5[11]:在编码端,将输入的问题和抽取的三元组文本连接成一个长文本,在文本前加上“答案:”或者“逻辑形式:”得到两个前缀不同的文本作为编码器的输入,将文本嵌入到低维向量空间,在解码端,对于前缀是答案的文本输入,解码器生成问题对应的答案;对于前缀是逻辑形式的文本输入,解码器生成问题对应的逻辑形式,构造代价函数联合二者得到最终答案。
在构建中医知识图谱问答系统时,核心工作是通过专业中医网站知识、大型开源知识图谱以及中医临床病历三个数据源联合构建一个满足功能要求的中医知识图谱。本文从专业的中医网站以及开源的中文知识图谱CN-DBpedia[12]、PKU-PIE[13]出发,抽取其中需要的中医领域知识,保证了知识的丰富性;同时融合了中医临床病历知识,保证了知识的实用性;最后将抽取的知识本地化,构建一个实用的中医领域知识图谱,该流程也可迁移到其他特定的领域。
..............................
2相关技术及文献综述
2.1相关技术
2.1.1知识图谱
知识图谱作为一种整合从多个数据源中提取的信息的方式,将信息以结构化、可解释的形式表示。知识图谱以有向标记图的形式整合世界知识,有向标记图由节点、边和标签组成,其中标签具有明确的含义。现实世界的任何东西都可以作为一个节点,例如人、公司、计算机等,一条边连接一对节点用于表示节点间的关系,例如两个人之间的友谊关系、公司和员工之间的雇佣关系,标签用于解释关系的含义,例如雇佣关系。这里给出知识图谱的一个简单的定义:给定一组节点个数为M、一组标签个数为N,知识图谱可以看作(节点N)x(标签M)x(节点N)这个集合的子集。这个集合的每个成员都称为三元组。如图2.1所示:三元组是有向图的基本单元,用于表示各种各样的关系。比如当节点是人、边的标签是友谊关系时,三元组可以表示人与人之间的友谊关系,此时从一个表示人的节点出发,通过友谊关系链接,可以找到这个人的所有朋友。

计算机论文怎么写
在知识图谱领域,用于描述三元组数据最流行的图数据模型是资源描述框架(RDF)和属性图模型(PG)。RDF是一个在网络上表示信息的框架,RDF数据模型及其查询语言SPARQL由万维网联盟(W3C)提供统一的标准;PG模型的查询语言是Cypher,许多流行的图形数据库系统都使用PG数据模型,不同于RDF用于处理web上激增的信息,PG数据模型用于处理一般的图数据,并且优化了涉及图遍历的操作。在本章中,我们将分别介绍这两种数据模型,最后还会介绍构建知识图谱的相关技术以及国内外主流且开源的大型知识库。
................................
2.2文献综述
知识图谱问答的核心任务就是跨越自然语言到知识图谱结构化知识的鸿沟,提供用户友好自然语言接口操作知识图谱。目前知识图谱问答领域的主流研究方法大致分为两种:1.基于语义解析的方法;2.基于信息检索的方法。本节结合相关工作介绍这两类主流研究方法及中医领域知识图谱问答的研究现状。
2.2.1基于语义解析的方法
基于语义解析的方法主要思想是将自然语言问题转化为一系列逻辑形式,通过对逻辑形式进行自上而下的转化,最终得到可以操作知识图谱的逻辑形式,比如sparql查询语句,最后执行逻辑形式查询得到最终的答案。
传统基于语义解析的方法主要依赖于人工构造规则或模板将自然语言问题转化为逻辑表达式。Aqqu[26]是一个基于模板可以将自然语言问题转化为sparql语言的端到端系统,一共包含三个模板,模板由实体、关系和答案节点组成,自然语言与问题的匹配过程中需要生成候选实体和关系,结合模板生成sparql语句。Zheng[27]提出了一种基于模板数据库的自动模板生成方法,从一组初始的自然语言问题和sparql查询库出发,基于自然语言问题与候选sparql图的相似性自动生成模板,最终生成自然语言问题对应的sparql语句。QUINT[28]是一个通过远程监督和依存解析树从用户问题及其答案中离线生成基本模板的问答系统,当处理复杂的问题是,通过依存解析将问题分解为多个子问题,将子问题对应答案集合的交集作为最终答案。NEQA[29]提出了一种持续学习的KBQA模板系统,在离线阶段会从少量训练问答对中自动学习将句法结构映射到语义结构的模板,部署后会在模板不足的情况下触发持续学习逐渐扩展模板库,还会定期重新训练其底层模型保证扩展后的模板库的有效性。这些传统方法中的大多数都不可扩展,或依赖于规则、模板,问答系统能力受限,或需要手动更新以补充其完备性。
................................
3联合逻辑形式解析和答案生成的知识图谱问答方法...............................19
3.1知识图谱文本化...................................19
3.1.1 Freebase架构........................................20
3.1.2 Freebase文本化....................................20
4实验结果及分析......................................31
4.1实验数据.....................................31
4.2评价标准..............................31
5联合逻辑形式解析和答案生成的中医问答系统..................................41
5.1中医知识图谱的构建......................................41
5.1.1知识图谱数据源..........................................41
5.1.2中医知识图谱构建....................................47
5联合逻辑形式解析和答案生成的中医问答系统
5.1中医知识图谱的构建
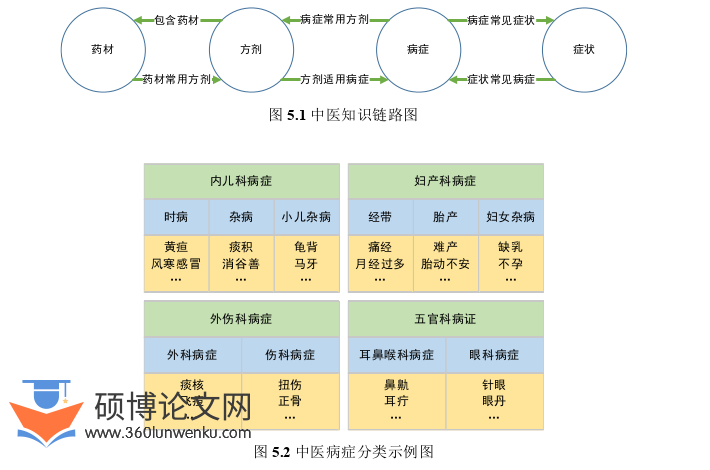
目前垂直领域的知识图谱在教育、金融、医疗、客服等众多领域被广泛落地应用,但领域知识图谱的构建仍不是一件简单的事情。以构建中医知识图谱为例,在构建的过程中主要面临两个挑战:清洗中医领域数据知识难度大、鲜有高质量且开源的中医知识图谱供参考。本节将介绍如何通过专业中医网站知识、大型开源知识图谱以及中医临床病历三个数据源联合构建一个满足功能要求的中医知识图谱,该知识图谱主要包括药材、方剂、病症、症状四个方面的知识,核心的知识链路如图5.1所示,具备从症状到病症到方剂到药材的推理能力,同时药材、方剂、病症、症状这四类节点本身具备大量的属性链路,赋予中医知识图谱丰富的知识。
5.1.1知识图谱数据源
5.1.1.1中医网站知识抽取
随着互联网时代的发展,传统的中医知识开始以互联网为载体得到了广泛的传播,权威的中医网站成为了中医领域不可或缺的知识源。在构建中医知识图谱时将中医网站作为知识源之一,爬取并清洗其蕴含的中医知识供中医知识图谱使用。具体来说,基于Scrapy框架编写爬虫程序爬取中医药网:http://www.pharmnet.com.cn/tcm/,并对数据做定制化清洗。在爬取中医药网时,主要爬取药材、方剂、病症、症状这四个方面的知识,建立它们之间的知识链路,为后续知识图谱的构建提供知识基础。在爬取病症时主要爬取常见的病症并将其分类为内儿科病症、妇产科病症、外伤科病症以及五官科病症,具体分类如图5.2所示。关于药材、方剂、病症包含的数据知识和爬取的数据分析见表5.1。
计算机论文参考
6总结与展望
6.1工作总结
本文提出了一种联合逻辑形式解析和答案生成的知识图谱问答方法。该方法的创新之处在于将KBQA任务简化为信息索引和语义解析两个阶段,在信息索引阶段将知识图谱看出一个结构化的信息库并将其文本化,抽取其中与问题文本相关的三元组文本;在语义解析阶段同时生成输入问题对应的逻辑形式和答案,联合二者生成最终答案。具体来说,本文基于生成式模型T5构建统一的生成式模型框架,将问题文本和抽取的三元组文本作为模型输入,通过前缀标记法联合逻辑形式和答案编解码,同时生成问题对应的逻辑形式和答案,构造代价函数联合二者生成最终答案。该方法将KBQA简化为先检索后生成的两阶段任务,相较于主流KBQA解决方案流程更短,同时避免了实体识别等子任务的累计误差;另外在处理自然语言问题时,有些问题对应的逻辑形式复杂但答案相对简单,部分问题对应的逻辑形式简单但是答案相对复杂,该方法充分利用了生成式模型对逻辑形式和答案的编解码能力,同时生成逻辑形式和答案并联合二者生成最终的答案,提高了问答的准确性。
基于上述方法,本文实现了一个中医领域知识图谱问答系统,系统实现包括两部分:从专业中医网站知识、大型开源知识图谱以及中医临床病历三个数据源抽取并清洗数据,联合构建一个满足功能要求的中医知识图谱;构建了一个联合Cypher语句解析和答案生成的中医问答系统。该系统可以查询中医领域药材、方剂、病症和症状之间的知识链路并作推理。中医领域蕴含大量复杂的知识,基于知识图谱的中医领域问答系统可以为用户提供便捷、高效的中医知识获取途径,帮助用户更好地理解中医的原理和实践,提高中医知识的可及性,使其更广泛地为大众所用。
参考文献(略)