本文是一篇工程硕士论文,本研究首先提出一套预处理流程,辅佐在线模型进行预训练;在此基础上提出一套在线风速预测模型,另外分析了风向的时序特性,在风速预测模型的基础上提出一套高效准确的风向预测模型,弥补了现有风速风向预测算法的不足,为智慧风场中风能的精准预测提供了一套完备的工程解决方案。
1 绪论
1.1 研究背景及意义
1.1.1 风力发电背景
能源作为人类社会生存和发展的最基本物质基础[1]。进入近代以来,伴随着技术革命的不断创新和发展,尤其是进入工业时代以来,人类对于能源的消耗水平不断攀升,化石能源的开发利用极大地促进了全球工业化的进程和经济的高速增长[2]。然而,基于传统化石能源本身的局限性,地球上可供方便开采的化石能源储量不断下降,在其使用过程中更是引发了大量生态环境污染,例如化学烟雾、温室效应、雾霾、酸雨等[3],能源结构的深层次变革已成为未来发展趋势。以清洁、环保、高效、丰富为核心特征的新能源行业逐渐成为全世界诸多国家能源变革的新动力,我国也将其加入战略性新兴产业,在市场、技术、资金和政策多项支持下加快能源转型,尽快实现碳达峰和碳中和[4]。
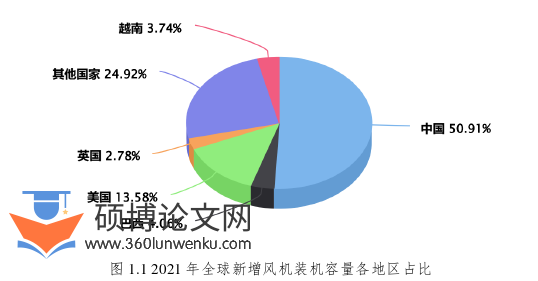
风力发电作为新能源产业中重要组成部分,在全球范围内受到越来越多政府和国家的重视。2022年上半年由全球风能理事会发布的《2022年全球风能报告》指出,2021年全世界风电机组装机容量新增93.6GW,风电领域全球累计机组装机容量(包括海上风电和陆上风电)已经到达837GW,相比2020年同比增长12%[5]。如图1.1所示是2021年全球新增风机装机容量各主要国家的占比。
工程硕士论文怎么写
....................................
1.2 国内外研究现状
气象学领域对于风资源预测的研究相对起步较早。早在二十世纪九十年代,丹麦的气象系统研究人员开发出名为Prediktor的风速预测算法系统,可以搜集到各类相关物理信息,包括但不限于:实时压强变化、湿度信息、地形信息等,建立起一套完整的数值天气预测系统[30];紧接着西班牙采用自己的物理信息系统搭建了名为LocalPre的风能预测系统,相比于荷兰的数值气象模型,西班牙的物理信息系统采用的是统计学模型,他们着重于风速风向的短期预测[31];德国也意识到短期预测的重要性,模仿西班牙LocalPre系统建立起Previento系统预测风速风向变化,这些短期预测一般在小时级[32];美国太平洋西北国家实验室(PNNL)针对超短期风速预测的实时性要求开发出一套针对超短期的预测模型,能够对于分钟级别的风速变化进行预测[33]。
随着数据挖掘研究的不断成熟,数据科学开始专注短期和超短期风能预测。风能作为矢量,风速和风向的预测都是必要的,两变量互相耦合。无论是风速还是风向,从预测方法分类,主要包括时序统计预测法、信号分解预测法、模型参数优化预测、大规模人工神经网络预测和多模型组合预测法。
(1). 时序统计预测法
风速风向序列都属于时间序列,最常用的方法就是采用统计预测法。统计预测模型主要是指利用统计学方法,计算得到预测值,最典型的时序统计预测方法有针对平稳序列的自回归滑动平均模型(Auto-Regressive and Moving Average Model,ARMA模型)[34],主要由自回归模型(Auto-Regressive Model,AR模型)与移动平均模型(Moving Average Model ,MA模型)为基础融合新构成的自回归模型,以及针对非平稳序列的差分整合移动平均自回归模型(Autoregressive Integrated Moving Average model,ARIMA),其通过差分使得序列平稳然后采用ARMA去预测。另外,马尔科夫预测模型[35]、卡尔曼滤波预测[36]、拓展卡尔曼纳滤预测[37]等都是基于统计学知识建立预测模型。
(2). 基于信号分解的预测方法
信号分解被广泛应用在很多时序预测的研究中。信号分解能够显著降低原始信号的复杂性,通过将风速序列分解为多个模态信号作为数据预处理的核心步骤,分解后可以通过重构信号减少噪声和干扰,也可以针对不同模态信号特点,针对性构建预测模型,将预测结果叠加得到最终结果,还可以将模态分解的结果作为新特征输入到预测模型中,让模型获得更多可训练的信息。常见的分解方法包括经验模态分解(Empirical Model Decomposition, EMD)以及小波变换分解(Wavelet Transform, WT)与小波包分解(Wavelet Packet Decomposition, WPD),还有奇异谱分析分解(Singular Spectrum Analysis, SSA)和变分模态分解(Variational Mode Decomposition ,VMD)等。
...................................
2 面向风资源预测的风电数据分析与预处理研究
2.1 引言
在预测模型建立之前,本章节将对本研究使用的数据来源和风电数据特点进行深入分析,在此基础上完成数据预处理工作,作为第三章和第四章风资源预测研究的基础。
尽管模型在工程部署后是在线运行,但初始化时需要丰富的离线数据进行特征工程和预训练。面对海量风电数据存在的特征维度高冗余大、时序特征复杂分析难、数据质量低缺失多的问题,在预训练离线场景下提出了一套完善的数据预处理方法:首先依据原始数据信息,提出了融合Pearson相关系数-互信息-χ方分布的特征选择方法,利用互信息与Pearson相关系数筛选出备选特征,这些特征与风速风向存在线性或者非线性关系,再依靠χ方分布对特征进行二次筛选,并再次使用Pearson相关系数消除线性冗余特征,从而选择出合适的特征;其次通过对数据时序特性进行分析,考虑自相关系数和协自相关系数并结合实际工程经验选择样本输入步长和在线预测训练集大小;在得到需要的特征和输入步长的基础上,提出了Pre-BiLSTM缺失值填补算法,定义了风电采样数据中整行缺失的缺失模式,并利用邻近均值插补法对于缺失数据进行预填充,并基于改进的BiLSTM建立自映射网络模型,优化了传统损失函数进行缺失数据的二次填补,大幅提高了填补精度。
本章节的其他小节安排如下:第2.2小节介绍了数据的主要来源, 包括风能产生原因,风电场的SCADA数据采集系统以及激光雷达测风雷达装置;第2.3小节介绍数据预处理与特征工程,解决了离线场景下的时序特征分析和特征选择、以及在线特征工程的问题;第2.4小节通过实验证明了本章节提出的最大创新点——Pre-BiLSTM离线缺失值填补模型的有效性;第2.5小节对本章内容进行总结和归纳。
............................
2.2 数据来源
2.2.1 风能的产生
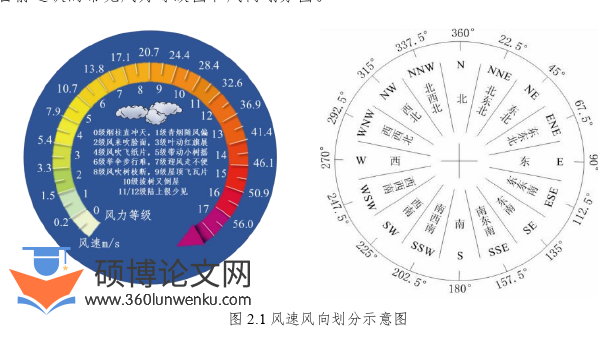
风是地球上常见的气象现象之一,太阳辐射热是风能产生的原因[57]。当地球表面接收到日光照射,造成地表的温度上升,受热膨胀的地表空气逐渐上升,之后低温的冷空气从横向不断流入,之前在上升中的热空气温度逐渐降低,地表温度较高继续使得地表附近热空气循环上升,这种大规模的大气流动就是风[58]。对于风电领域研究的风速风向问题,其指代是大气湍流中空气相对于地表运动的水平分量,因为垂直方向的湍流对于风电机组是没有意义的[59]。图2.1为目前通认的常见风力等级图和风向划分图。
工程硕士论文参考
风电场关注的风速,是空气在单位时间内相对地面移动的平均距离,单位是米/秒[60]。风电场所在位置一般选择都是风况较好,风能较大的位置,例如海边、山地、大面积远离市区的平原,更确切的说,风电场更关注风资源丰富的地方[61]。
.............................
3基于改进宽度学习的实时风速预测研究 ...................... 37
3.1 引言 ............................. 37
3.2 风电机组实时超短期风速单模型预测 ................. 38
4 基于区间划分概率决策的实时风向预测研究 ........................... 69
4.1 引言 ........................................ 69
4.2 风向特性分析 .................................... 70
5 总结与展望 .............................. 87
5.1 论文工作总结 .......................... 87
5.2 工作展望 .......................... 88
4 风电机组超短期实时风向预测研究
4.1 引言
第三章节介绍了对于风速的超短期预测,但是对于风电系统来说,风向预测也是同样重要。准确有效的风向预测可以提升机组偏航系统的响应速度,有效的降低机组运行载荷;还可以协助尾流在线计算,对于不同的未来风向,风电场将会决策出不同的迎风面机组,建立实时风电场尾流模型,用以辅助机组的场级功率分配。风速与风向作为两个强相关变量,有相似也有不同,本章节将在第二章预处理和第三章风速预测模型的基础上,针对风向与风速的差异性提出一套在线风向预测算法,提升风向预测的精度。
本章节从保证风向预测的实时性和准确性角度出发,提出一套基于区间划分概率决策的mBLS组合风向预测算法。首先,分析了风向特征的旋转特性和风电场本身由于位置和季节导致的样本不均衡特点;其次,针对旋转特性提出分解风向以平滑风向变化;之后,根据之前分析的主导风向特性提出先分类后预测的策略,本研究使用随机森林对风向先做分类预测,在不同分类决策下进行并行预测;最后,采用概率决策机制,考虑单分类结果不确定性,采用输出预测区间概率分布,让概率决定不同区间模型对于最终结果的决定权重,多区间模型利用所在区间训练集预测最终结果,用概率作为权重进行叠加,输出最终预测结果。该方法针对因为风电场主风向的存在导致的样本不均衡特性,通过多分类预测保证了模型预测的准确性,每个区间的预测迁移了风速预测的mBLS组合预测架构,最终通过实验证明了模型的有效性。
..........................
5 总结与展望
5.1 论文工作总结
风能作为自然界存储量丰富、环保无污染的清洁能源,在能源市场上占据着越来越重要的位置,尤其是随着世界各国对于能源短缺、环境污染等问题的进一步重视,早日实现碳达峰和碳中和成为全人类未来发展的共同期望和目标。由于风能本身的不稳定性、间歇性和突变性,一方面给风电机组的控制、调度以及安全运行带来隐患,另一方面对电网并网和电压稳定提出更大挑战。对于中长期的风速预测,气象领域有较为成熟的方法——数值天气预报NWP,用以解决机组维修规划、风电场选址、保证长期并网安全可靠等问题,而机组的稳定控制、功率调度与尾流实时计算等都依赖于超短期实时预测,现有的超短期风速风向预测无法兼顾准确性和实时性双重要求。本研究首先提出一套预处理流程,辅佐在线模型进行预训练;在此基础上提出一套在线风速预测模型,另外分析了风向的时序特性,在风速预测模型的基础上提出一套高效准确的风向预测模型,弥补了现有风速风向预测算法的不足,为智慧风场中风能的精准预测提供了一套完备的工程解决方案。
本文的主要工作以及研究成果总结如下:
(1) 针对风电数据质量低、特征繁多、时序分析复杂,提出预处理方法。首先针对海量SCADA数据特征,融合Pearson相关系数、互信息与χ方分布进行特征提取;之后利用自相关系数与协自相关系数对风速/风向进行时序分析,确定模型步长和训练集的大小;在得到特征与步长基础上,面向风电SCADA系统数据整行缺失的问题,充分挖掘SCADA已有信息,利用邻近均值法对缺失数据进行预填充,在此基础上构造BiLSTM网络,建立数据自映射的编码解码网络,并优化了损失函数,经风电数据证明,所提方法明显优于其他常规的工程缺失值填补方法;
(2) 针对难以保证超短期风速预测实时性与准确性双重要求的问题,提出一种基于改进BLS网络架构与参数自适应优化的大规模并行多模型集成化组合风速预测算法。首先,根据超短期风速预测的实时性需求,为了保证工程可用性,提出了完整的参数自适应优化流程以适应单模型实时风速预测;其次,将SVR、XGBoost、BLS三种模型进行在线优化,针对各自特点完善参数在线优化环节并迁移到实时超短期风速预测领域;最后,为了提升预测的准确性,通过改进传统的BLS网络架构提出多通道融合的multi-BLS网络架构进行风速的组合预测。
(3) 在风速预测的基础上,针对风向特征本身存在的旋转特性导致的伪奇异值问题和由于主导风向导致的样本不均衡问题,本研究提出一种基于随机森林多区间决策的并行多模型组合在线自适应风向预测模型。首先迁移了其他领域对于角度变量预测的方式,对角度进行三角函数分解,使得特征变化完全连续;其次,针对样本不均衡问题,提出区间预测概率决策的预测思路,通过随机森林模型对于样本未来的风向区间依据风况和特征进行预测,输出各个区间发生的概率值;之后,迁移之前的风速预测模型,在每一组风向区间内部都使用该区间的数据训练一组mBLS组合预测模型对风向进行预测;最后,依据概率决定每个mBLS组合预测输出的权重,叠加得到最终的风向预测输出。
参考文献(略)