第一章 绪论
1.1课题背景及研究意义
在 21 世纪,计算机技术呈现蓬勃发展的趋势,互联网遍布着生活中的各个角落,从出行到购物,从观影到音乐等很多应用场合,给人们带来极大的便捷。例如,作为国内最顶尖的电子商务平台之一,阿里巴巴让人们不仅能够通过网络购物,也可以轻松地申请成为店家,客户既可以制造商品也可以购买商品,足不出户便可享受互联网带来的福利。诸如抖音等移动终端上的短视频应用软件,让人们利用碎片化时间获取热点新闻,每个人既可以发布视频也可以观看视频,这种吸引人的特性促进了短视频平台的迅猛发展。根据阿里巴巴和字节跳动发布的最新财报,前者的活跃用户量已达到 7.42 亿,后者的活跃用户量也超过了 6 亿。然而,凡事都是各有利弊的,活跃用户和在售商品数量的爆炸式增长为商家和用户双方带来了信息过载的困扰,即商家只能将时下流行的热门商品推荐给所有用户,而无法有效地针对某用户从海量商品中过滤出他感兴趣的商品。面对体量如此庞大的数据信息,为了提高用户体验,个性化的推荐系统应运而生。
目前,一大批工业界和学术界的人员已经投入推荐算法的研究中。在工业界,字节跳动仅用九年时间便从零开始一跃成为估值 750 亿美元的超级独角兽公司,而它最让大众津津乐道的则是“千人千面”的个性化推荐算法,旗下的今日头条、西瓜视频和抖音短视频等多款 APP 产品无一不证实着个性化推荐算法能够为企业带来巨大利润和经济效益;另外,美国最大的视频网站 YouTube 的成功也离不开精准的视频推荐系统,相关技术部门在公司内一直都得到大力的资金扶持。在学术界,始办于 2007 年美国明尼苏达州的 RecSys 是专门聚焦于推荐算法的 ACM 学术会议,由于近些年推荐系统应用越来越广泛,该会议的与会人员也越来越多,此外还有国际上顶级的学术会议 WWW(WorldWide Web Conference),该会议在 2020 年收到了 1129 篇论文投稿,录用 217 篇,而其中关于推荐算法的论文就高达 38 篇,占比 17.5%,作为人工智能中的一门新兴研究方向,推荐算法的火热程度可见一斑。
..........................
1.2 相关研究现状
关于推荐算法的研究普遍认为起始于上世纪 90 年代初期,Goldberg 等人[3]于 1992年开创性地提出协同过滤的思想,并将其应用于施乐帕洛阿尔托研究中心的 Tapestry 系统,以此为用户过滤出感兴趣的邮件。Resnick 等人[4]于 1994 年使用协同过滤实现了新闻消息推荐系统 Grouplens 以及音乐推荐系统 Ringo。1997 年,Resnick 等人[5]首次提出“推荐系统”的概念,但此时的推荐系统其实只是协同过滤的代名词。美国的流媒体播放平台 Netflix 于 2006 年 10 月举办了一场推荐算法比赛[6],要求参与者的算法精度能够在他们发布的一个包含 1亿匿名电影评分的数据集上超越公司使用的原算法Cinematch,该竞赛吸引了大量相关人员的积极加入,让推荐系统的研究水平达到了一个空前的新高度,同时也使得“推荐系统”一词被更多人熟知。作为早期最热门且迄今为止最经典的推荐算法,协同过滤直到 2000 年初都是国内外学者的重点研究对象,其中的部分思想甚至在当下的前沿算法中都仍有体现。根据建模方式的不同,可将协同过滤分为两类[7],即基于内存的协同过滤和基于模型的协同过滤,前者包含基于用户的协同过滤和基于商品的协同过滤,这类算法使用指定的相似度指标计算用户之间(或商品之间)的相似度,依据相似度对其他用户(或商品)加权,得出推荐结果,而基于模型的协同过滤中常见的如矩阵分解,即利用低秩矩阵分解技术对评分矩阵中的缺失值(即负反馈值)进行填充,以此实现评分预测。
1.2.1 国内研究现状
直到 21 世纪初,国内的推荐算法研究人员主要是针对基于内存的协同过滤进行改进。文献[8]考虑到评分矩阵的稀疏度往往很高,若直接计算两用户之间的相似度则会导致被他们共同标注过评分的商品太少,相似度计算的准确度不高,因此提出先对评分矩阵进行填充,在此基础上使用相关相似性公式寻找用户的近邻,再根据相似度加权以此完成推荐。为了更好地寻找商品的近邻,文献[9]提出一种基于聚类的协同过滤算法,利用评分数据稀疏差异度和商品类别构造集合差异度度量公式,在对商品聚类后,依据用户已购买商品的近邻完成推荐。
然而,评分矩阵的稀疏性对于基于内存的协同过滤的制约仍非常明显,因此,此后的研究主要针对基于模型的协同过滤进行改进。文献[10]提出了一种基于奇异值分解的推荐算法,该算法考虑到多数矩阵分解模型容易出现过拟合,于是引入正则化项对用户和商品的隐特征进行约束,使用迭代最小二乘法在 Hadoop 平台上并行求解参数,不仅提高了评分预测精度,也优化了算法的运行效率。文献[11]融合了矩阵分解与用户近邻两种思想,在矩阵分解模块中为用户和商品引入评分基准值和偏移量,在用户近邻模块中对近邻根据余弦相似度加权,最后综合考虑两模块得到损失函数,使用梯度下降优化模型中的参数。另外,有些国内学者针对不同时间段用户和商品特征的漂移性质提出了动态推荐算法。
.........................
第二章 相关理论与技术
2.1 推荐算法的概述
传统的推荐算法可分为以下三种类型[32]:(1)基于内容的推荐算法(Content-basedRecommendation)(2)协同过滤算法(Collaborative Filtering,CF)(3)混合推荐算法(Hybrid Recommendation),以下分别进行介绍。
2.1.1 基于内容的推荐算法
在推荐系统的研究初期,人们的研究对象一般是基于内容的推荐算法,其特点是通过分析商品内容描述信息(如文章推荐问题中的文本内容)的规律和特征实现推荐。首先获取某用户已经购买过的商品记录,使用预处理算法得到所有商品的内容描述信息,再使用特定的特征提取算法从这些内容描述信息中提取出每件商品的特征向量,挖掘商品与商品之间潜在的关联度,将那些与用户已购买商品关联度高的商品推荐给该用户。由此可见,基于内容的推荐算法需要选取性能合适的预处理算法和特征提取算法,针对不同推荐问题场景有不同的算法选择。例如,对于文本商品,可以采用信息检索与数据挖掘领域中常用的词频-逆文本频率指数算法[33](Term Frequency-Inverse DocumentFrequency,TF-IDF)构造其内容描述信息,该算法的核心思想是随着某字词在当前文档中出现的次数逐渐增加,其重要性会成正比增加,但随着语料库中该字词出现频率的增加,其重要性会成反比下降。在构造出所有商品的内容描述信息向量后,由于它可充分反映出文本商品的特征,故可直接将其作为商品的特征向量。
基于内容的推荐算法的优点如下:
(1)能解决商品的冷启动[34]问题,即当一个新商品刚进入推荐系统后,可使用预处理算法和特征提取算法得到概商品的特征向量,便可根据某用户的购买历史来做出将该商品推荐给哪些用户的决策。
(2)具有很好的可解释性[35],通过计算jv 和kv 的余项相似度可向用户解释为什么将该商品推荐给他,即商品 j 与你购买历史中的商品k 特征很接近。
但该算法的弊端也很明显,由于推荐给用户的商品都与其购买过的商品相似度很高,所以无法挖掘用户的潜在偏好,会导致系统推荐的商品的局限性很高。
.....................
2.2 概率图模型的基本概念
概率图模型(Probabilistic Graphical Model)是用来表示问题中各随机变量之间概率依赖关系的图模型,由 Pearl 于 1986 年提出,它同时结合了图论与概率论,因此具有良好的可解释性、强大的表达能力以及坚实而优雅的理论基础[40],近年来已受到人工智能、模式识别和数据挖掘等众多领域研究人员的广泛关注。
根据概率图模型中边的有无方向性可分为三类:(1)贝叶斯网络[41](BayesianNetwork,BN),又称贝叶斯信念网络、有向图模型,其网络结构为一个有向无环图(Directed Acyclic Graph,DAG)(2)马尔可夫网络[42](Markov Network,MN),又称无向图模型,其网络结构为无向图(3)局部有向模型,同时存在有向边和无向边,如条件随机场[43](Conditional Random Field,CRF)。在推荐系统的背景下,一般将问题考虑为生成模型,即用户对商品的评分变量是由该用户的特征向量和该商品的特征向量(或还包含其他随机变量)服从某种特定分布生成得到的,且用户的特征向量和商品的特征向量也是服从某种先验分布生成得到的,故一般使用贝叶斯网络与推荐算法相结合。
如在图 2-3 的贝叶斯网络中,每个结点代表一个随机变量,结点间的弧代表随机变量之间的概率依赖关系,当一条弧从随机变量 A 指向另一个随机变量 B 时则说明 A 的取值会对 B 的取值产生影响,依从图论中的定义,此时弧尾 A 称为弧头 B 的双亲结点,B 为 A 的孩子结点,如果从一个结点 A 有一条路径指向 C 则称 A 为 C 的祖先,C 为 A的后代。
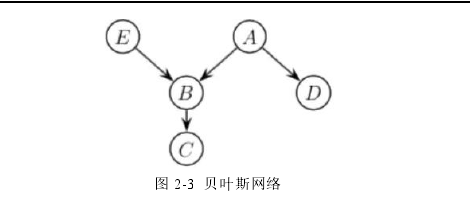
图 2-3 贝叶斯网络
第三章 基于 ExpoMF 算法改进的个性化推荐算法研究................................... 23
3.1 引言............................................ 23
3.2 VAHR 算法............................................ 23
3.2.1 推断层............................................24
3.2.2 推断层的时间复杂度分析...........................30
第四章 基于曝光隐变量的社会化推荐算法...............................................48
4.1 引言.................................................. 48
4.2 EBSR 算法...................................... 48
4.2.1 生成过程................................................49
4.2.2 参数求解......................................52
第五章 EBSR 算法在知乎问题推荐中的应用...................................67
5.1 引言.................................................. 67
5.2 数据预处理............................... 67
第五章 EBSR 算法在知乎问题推荐中的应用
5.1数据预处理
5.1.1 数据源介绍
知乎是一个中文互联网高质量的问答社区和创作者聚集的原创内容平台,并提供了以信任为基础的社交网络关系,有着相同爱好的用户之间可添加关注,追踪彼此动态。除此之外,知乎还提供了话题功能,即问题的提出者可指定五个以内的话题,用户也可选择关注某话题,如下图所示。
图 5-1 知乎页面
...........................
第六章 总结与展望
6.1 工作总结
近年来,随着互联网时代的到来,海量数据带来便利的同时也出现了信息过载问题,很难实现针对某用户的精准个性化推荐,因此推荐系统的研究价值越来越高,用户和商家都迫切地需要优秀的推荐算法来优化用户的使用体验。在人工智能领域,推荐算法毫无疑问已经成为了当下最火热的研究方向之一,对推荐算法的改进会为工业界和学术界带来巨大利益。在此需求下,本人通过导师的悉心指点和大量国内外文献的调研,最终确定从结合概率图模型和推荐算法的角度进行研究。本文首先在第一章对推荐算法的研究背景、课题意义以及国内外研究现状等内容进行详细阐述,在第二章介绍概率图模型与推荐算法两个方向的相关知识,在第三四章分别介绍了两种基于 ExpoMF 算法改进的个性化推荐算法,通过仿真实验,将它们与同类型的算法进行对比,以此验证所提出算法的有效性,通过并行框架对改进后的算法进行并行实现,并分析在运行效率上的提升效果,最后通过在知乎上爬取真实数据对 EBSR 算法进行验证。本文的主要工作如下:
(1)在第三章,首先分析 ExpoMF 算法在参数估计时的缺点,即 ExpoMF 使用最大化期望算法求解模型中参数时破坏了用户隐特征、商品隐特征和用户-商品曝光概率似然函数与先验分布之间的共轭关系,致使无法将前一轮迭代得到的结果作为下一轮迭代的先验分布,只能实现非迭代式的参数求解,即每轮迭代中只能使用以零向量为均值的球形高斯分布作为先验,因此参数求解的精度较差。针对这个问题,本文提出 VAHR算法,使用吉布斯采样捕获上述三种参数似然函数与先验分布之间的共轭关系,以实现基于吉布斯采样的迭代式参数推断。另外,启发式地将 ExpoMF 在前一轮 M 步用最大后验概率求出的用户隐特征和商品隐特征的解析解作为下一轮迭代的先验分布的均值,以实现基于最大后验概率-期望最大化算法的迭代式参数估计,并将其命名为 VAHR-I。通过在 citeulike 数据集上的仿真实验,将 VAHR、VAHR-I、ExpoMF 等若干同类型的推荐算法做对比,以召回率作为评估指标,分析各算法之间的优劣性,实验证明了与其他算法相比 VAHR 具有更好的推荐效果。另外,针对 ExpoMF 无法预测用户曝光概率的问题,VAHR 将前一步推断得到的用户曝光向量用变分自编码器抽取隐特征并对其进行重构,以此预测哪些商品在未来曝光给该用户的概率更高。针对 ExpoMF 无法解决新商品的冷启动问题,VAHR 将推断得到的参数结果作为观测变量,使用变分自编码器抽取商品隐特征,构造概率图模型,使用小批量梯度下降对神经网络中的权重参数和偏置参数进行优化后,便可对新进入系统的商品使用该变分自编码器抽取其隐特征以此实现新商品的推荐。在 citeulike 数据集上通过仿真实验,将 VAHR 与其他同类型的冷启动推荐算法做对比,可证明 VAHR 能取得更高的召回率。
参考文献(略)