本文是一篇计算机论文,本文聚焦于个性化信息的提取与利用方式,以及增强模型建模时频特征能力的方式开展一系列研究。
第一章绪论
1.1研究背景及意义
抑郁症是一种常见的精神疾病,给患者本人、家庭和社会都造成了巨大的负面影响,是全球主要的疾病负担之一[1]。据世界卫生组织(World Health Organi-zation,WHO)统计,全球大约有超3亿人患有抑郁症,占全球人口的3.8%[2]。中国的抑郁症患者已经超过9500万,每年大约有28万人自杀,其中40%的人患有抑郁症[3]。抑郁症会导致患者情绪持续低落、自我价值感下降、注意力不集中、食欲或体重变化、睡眠障碍等,严重时甚至可能引发自残和自杀行为[4-5]。·一些研究表明,抑郁症会增加心血管疾病、癌症、糖尿病的风险[6-8]。抑郁症不仅给个人健康带来巨大危害,还在家庭和社会层面引发了深远的经济后果。根据世界经济论坛的估算,抑郁症造成的全球经济损失累计约为25000亿美元,预计到2030年,累计经济损失将超过60000亿美元[9]。
早期诊断与及时治疗对减轻抑郁症危害至关重要。尽管抑郁症对患者、家庭和社会的危害显著,但目前已存在多种有效的治疗方法,包括心理治疗和药物治疗等[10]。然而,由于当前的抑郁症诊断方法存在主观性,并且精神专科医生资源有限,实现早期诊断仍面临较大挑战。目前,抑郁症的诊断主要依靠精神科医生的专业评估,医生通过综合分析患者的临床访谈、评估量表、病史资料等进行判断[11]。常用的量表包括9项患者健康问卷(the 9-item Patient Health Questionnaire-9,PHQ-9)[12]、汉密尔顿抑郁量表(Hamilton Depression Scale,HAMD)[13]等。然而,这种诊断方式在很大程度上依赖于精神科医生的主观经验和患者的参与意愿,这两者都可能导致诊断结果产生偏差。根据《2020年中国精神卫生资源状况分析》的数据,我国每10万人对应的精神专科医生人数仅为3.55[14]。因此,构建一种客观、有效、便捷的抑郁识别系统对于减轻抑郁症的危害具有重要意义。
计算机论文怎么写
..................
1.2国内外研究现状
从研究演进的角度来看,基于语音的抑郁识别研究可分为三个阶段:有效特征的探索阶段、基于传统机器学习技术的研究阶段,以及基于深度学习技术的研究阶段。本节将按照这三个阶段,依次综述基于语音的抑郁识别研究的国内外研究现状,并总结本领域公开可用的数据集,以提供对现有研究基础的认识。
1.2.1有效特征的探索阶段
有效特征探索的研究工作主要集中在20世纪初至2015年,期间经历了不同的发展阶段。在早期阶段(20世纪初至21世纪初),研究主要侧重于临床观察语音信号与抑郁症之间的关系。随着研究的深入,研究开始聚焦于探索可作为客观检测指标的有效特征。
早期相关研究对语音信号与抑郁症关系的分析揭示了抑郁症患者的语音特征与正常人群存在差异,并表明语音信号具有作为抑郁症检测指标的潜力。1921年,Kraepelin[26]对大量抑郁症患者进行临床观察发现,相较于正常人群,抑郁症患者的语音通常呈现出沉重、犹豫和缓慢的特征。这表明研究人员已经注意到抑郁症患者语音的特殊性。1976年,Szabadi等人[27]分析了四名抑郁症患者康复前后自动语音(从1数到10)的停顿时间差异,发现与康复后测量的停顿时间相比,他们在抑郁时的停顿时间更长。Szabadi等人[28]在1980年又观察了单相抑郁症患者在发作期间语音停顿时间的特点,发现这一时期他们的停顿时间有所延长。为了扩展这一临床观察结果,他们记录并分析了四名单相和三名双相内源性抑郁症患者的自动语音数据,结果显示,随着临床症状改善,两类患者的语音停顿时间均逐渐缩短。这说明停顿时间较长这一特点在抑郁症患者中较为常见。在后续研究中,研究者们进一步揭示了抑郁症患者与健康群体在语音特征上的差异。1987年,Nilsonne等人[29]记录了16名抑郁症患者在抑郁发作期间和临床改善后朗读寓言故事的语音数据,对比分析发现基频变化率的标准差、基频分布的标准差、停顿时间的百分比以及语音变化的平均速度与抑郁状态相关。1997年,Christina等人[30]综述了与抑郁症心理运动症状相关的研究,进一步确认了抑郁症患者在语音特征上与正常人群存在差异。
.....................
第二章相关理论及技术介绍
2.1语音信号的定义及预处理方式
在信号处理领域,语音信号被定义为语言的声学表现形式[67]。在基于语音的抑郁识别领域中,研究重点仍然是语音信号的声学属性(如频率、音调、节奏等),特别是利用深度学习模型从原始语音信号及其特征中提取与抑郁症相关的信息。
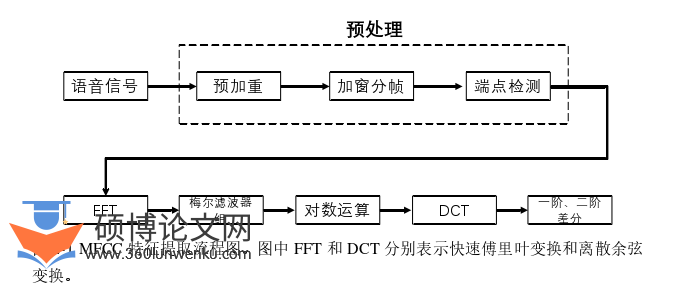
从语音信号中提取语音特征之前,需要对其进行预处理操作,其主要目的是改善信号质量以提高所提取特征的质量。预处理的环节主要包括:预加重、分帧加窗和端点检测。接下来将详细介绍这些环节的操作目的及数学原理。
(1)预加重
预加重的主要作用是补偿语音信号中由口鼻辐射引起的功率衰减,提高语音信号的高频分辨率。在语音信号的传输过程中,受声门激励和口鼻辐射的影响,信号功率会大幅衰减,尤其在高频部分的表现较为明显。由于语音信号频谱中的高频部分能量相对较低,未经预加重的信号在计算高频特征时较为困难,因此需要通过预加重来提升高频部分的能量。
预加重的核心思想为:通过高通滤波来增强语音信号的高频成分。本文使用的滤波器为一阶高通滤波器。
...............................
2.2相关语音特征
本节主要介绍三类与抑郁识别相关的语音特征,即韵律特征、共振峰特征和谱特征[68],并重点介绍本文采用的语音特征:梅尔频率倒谱系数(MFCC)、滤波器组(Fiterbank,Fbank)、线性预测系数(Linear Predictive Coding,LPC)和eGeMAPS特征集(extended Geneva Minimalistic Acoustic Parameter Set,eGeMAPS)[34]。
韵律特征反映了语音信号在整体层次上感知的节奏变化、能量、音高、语调等。常见的韵律特征包括语速、音高、响度和能量的动态变化,这些特征与抑郁症患者的部分临床表现相关,例如语速慢、基频范围小和停顿长[69]。研究表明,基频(F0)、语速、能量等较为常用的韵律学特征能够作为抑郁检测的有效指标[68,70]。
共振峰特征描述了语音信号频率响应的峰值[71]。由于声道形状和肌肉张力的变化,抑郁症患者的共振峰特征可能与正常人群存在差异。语音信号通常包括四至五个稳定的共振峰,其中前三个共振峰(F1、F2和F3)在抑郁识别领域被经常研究[72]。France等人对比了抑郁症患者和正常人之间的共振峰特征,发现共振峰特征可以作为抑郁检测任务中的有效指标[73]。
谱特征描述了语音信号在特定时间示例上的频率分布信息,通常包括频谱、功率谱、倒频谱、频谱包络等特征[69],MFCC和Fbank是本领域较为常用的谱特征。Low等人利用谱特征对青少年人群体进行抑郁识别,实验结果表明谱特征是有效的抑郁检测指标[74]。本领域所构建的深度抑郁识别模型常使用谱特征作为输入特征,例如Ma Xingchen等人将MFCC特征作为CNN+LSTM架构的抑郁识别模型的输入特征[44]。此外,谱特征也是本领域中构建抑郁识别模型时考虑说话人特征对语音信号的影响的研究常用的原始输入特征,例如Lishi Zuo等人将Fbank特征作为基于条件互信息的说话人特征不变抑郁检测器的原始输入特征[60]。
..........................
第三章数据集构建................................28
3.1纵向跟踪数据集.................................28
3.1.1实验目的..................................28
3.1.2实验设备及实验刺激材料....................28
第四章个性化信息嵌入的抑郁评估模型.........................35
4.1研究动机........................................35
4.2个性化信息嵌入的抑郁评估模型构建...................36
第五章个性化信息嵌入的时频特征增强抑郁评估模型................50
5.1研究动机..........................50
5.2个性化信息嵌入的时频特征增强抑郁评估模型构建.......................51
第五章个性化信息嵌入的时频特征增强抑郁评估模型
5.1研究动机
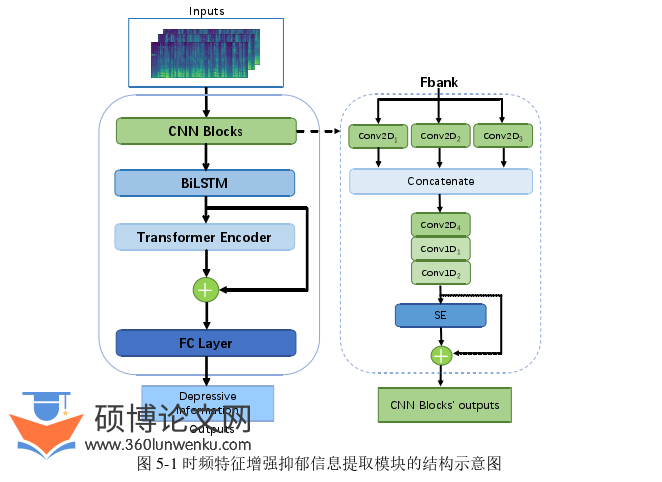
在上一章节,我们成功构建了个性化信息嵌入的抑郁评估模型。然而,随着研究工作的深入,我们认识到,该模型的抑郁信息提取模块在编码抑郁信息时受到时频特征建模能力的限制。上一章模型的重点在于提取并有效利用个性化信息,其抑郁信息提取模块采用了本领域常用的1D-CNN+LSTM架构,输入特征则是本领域常用的谱特征——Fbank特征。1D-CNN主要在时域上进行卷积操作,对Fbank中频域信息的建模能力依赖于卷积核的尺寸。如果卷积核尺寸较小,则难以捕捉跨频率的特征关联,从而影响频域信息的提取。LSTM用于建模长期依赖关系,能够在一定程度上捕捉跨时间步的特征模式。然而,LSTM在处理长期依赖时仍存在一定的局限性[117],特别是在面临复杂的时频变化时,LSTM可能难以充分学习语音信号的动态特征。因此,基于1D-CNN+LSTM架构设计的抑郁信息提取模块在时频建模能力上存在不足,可能导致上一章模型难以全面捕捉语音特征在时间和频率维度上的动态变化,从而对精确稳定的抑郁相关特征的表征不充分。为此,本章主要研究如何改进第四章模型抑郁信息提取模块的时频编码策略,以增强抑郁信息的表征能力,从而进一步提升模型的识别性能。
提升模型的时频特征建模能力,以增强其对语音信号中时域和频域变化的敏感性,一个可行的解决思路是提取更丰富的时频特征,并捕捉更全面的时序信息。基于这一思路,本章探索了抑郁信息提取模块的优化方法,并在此基础上构建抑郁评估模型。
计算机论文参考
........................
第六章总结与展望
6.1总结
尽管基于语音的抑郁识别领域已有众多研究成果,但通过对相关研究文献的综述与分析,发现本领域仍面临以下挑战:
(1)缺乏高质量大规模数据集,尤其是纵向跟踪数据集;(2)现有模型构建的抑郁相关特征表征能力有限;(3)现有模型的泛化能力不足。针对挑战(1)和(2),本文开展了相关研究,主要创新和贡献如下:(1)构建了一个光疗干预纵向跟踪数据集,为本文的研究提供了数据支持。我们通过分析发现,个性化信息具有不随抑郁状态变化且因人而异的特点。基于此特点,我们认为纵向跟踪数据集更容易提取出被试的个性化信息,有利于开展后续的研究工作。但是本领域缺乏公开的纵向跟踪数据集。因此,我们与北京大学第六医院合作,构建了一个包含54名被试两轮语音数据的纵向跟踪数据集,所有被试在两次采集数据之间会进行光疗干预,且他们在两个采集时间点的PHQ-9分数存在显著性差异。
(2)针对如何构建模型以减轻个性化信息的不利影响,提出了个性化信息嵌入的抑郁评估模型。该模型采用双通路架构,通过针对个性化信息特性设计的提取模块,以及基于1D-CNN+LSTM架构设计的抑郁信息提取模块,来同时提取个性化信息和初始抑郁信息。然后,通过基于自注意力机制设计的自适应融合模块,动态集成个性化信息和抑郁信息,从而获得稳定有效的抑郁相关特征。通过在纵向跟踪数据集上的一系列实验,验证了该模型的性能优势以及个性化信息提取方法的合理性。
参考文献(略)