本文是一篇计算机论文,本文通过多组严谨的实验,从主观和客观两个方面对本文的损失函数和模型进行充分的实验分析,最终证明本文所设计的损失函数和模型具有一定的优越性。
第一章 绪论
1.1 研究背景与意义
随着人工智能的快速发展,计算机视觉领域研究取得了突破性的进展,尤其是基于人脸图像的研究。人脸,作为人类识别的核心生物特征,其相关技术开发和应用日益多样化,广泛渗透到当今社会的诸多领域中。例如,人脸检测[1]可用于安全监控、数字摄影的自动对焦;人脸识别[2,3]可以用于安全认证、执法监管;人脸对齐[4]既可用于美颜应用,也能用来对图像进行预处理;人脸跟踪[5]既可以用来在视频监控中跟踪特定个体、分析人群行为,也可以用来增强视频会议的用户体验;人脸建模[6]可以在游戏娱乐、医疗美容等方面大显身手;年龄估算[7]可以为个性化营销和内容过滤提供帮助。最近,人工智能大模型风靡全球,极大地推动了生成式人工智能(Artificial Intelligence Generative Content,AIGC)的发展,研究者们纷纷将目光投向绘画合成等艺术创作领域,希望可以构建具有艺术创造力的人工智能模型。由此,作为图像风格转换的素描-人脸合成(将人脸素描转化为人脸照片)得到了学术界的广泛关注。
研究素描-人脸合成技术,在连接传统艺术和现代人工智能的同时,还能为公安机关的案件侦破提供了有力的帮助。在当今的刑事案件侦破中,视频监控通常是获取犯罪嫌疑人线索的重要手段。然而,当案件现场缺乏视频监控,或者犯罪嫌疑人故意避开监控设备时,传统的侦破方法将面临巨大的挑战。此时,公安部门需要依靠其他方式获得关于犯罪嫌疑人的有效信息,最常使用的方法是人脸模拟画像技术[8]。人脸模拟画像技术通过目击者或受害者对犯罪嫌疑人特征的描述,由画家将这些口述信息绘制成犯罪嫌疑人的素描画像。这种方法使目击者的记忆得到更有效的利用,有时甚至可以激发出更多被忽略的细节,让重现嫌疑人的面貌成为可能。刑侦人员可以将这些手绘图像同现有的数据进行比对,识别出与素描图像相似的个体,从而筛选出一批可能的犯罪嫌疑人。该技术的应用极大地提高了案件的侦破效率,为公安机关打开了一扇新的窗口,使案件侦破工作不再完全依赖于传统的视频监控证据。
........................
1.2 国内外研究现状
目前现有解决素描-人脸合成问题的方法,大致可以分为两大类:基于传统机器学习的合成方法和基于深度学习的合成方法。在基于传统机器学习的范畴内,又可以进一步细分为三种主要的合成方法:基于贝叶斯推理的合成方法[10-12]、基于子空间学习的合成方法[13,14]以及基于稀疏表示的合成方法[15-17]。基于深度学习的合成方法大致可分为两类:基于深度卷积神经网络(Deep Convolutional Neural Networks, DCNN)的合成方法[18,19]与基于生成对抗网络的合成方法[20-30]。
1.2.1 基于传统机器学习的合成方法
基于贝叶斯推理的合成方法主要可分为两类:基于嵌入式隐马尔可夫模型(Embedding Hidden Markov Model, E-HMM)的合成方法与基于马尔可夫随机场(Markov Random Field, MRF)的合成方法。
人脸图像包含丰富的二维空间信息,这一特性为各种高级图像处理技术提供了可能。在利用这些信息的过程中,Gao等人[31]采用了E-HMM方法,这是一种专门用于将素描图像转换为人脸图像的非线性映射技术,先将人脸划分为五个超状态:眼睛、鼻子、嘴巴、下巴和额头。这种划分方法允许模型专注于人脸的关键特征区域,提高了特征提取的准确性和效率。每个超状态进一步被分解为多个嵌入状态,这些嵌入状态负责捕捉超状态内更细微的局部特征,这种层次化的特征提取策略使E-HMM能够更加细致地分析和重建人脸图像的各个部分。特征提取完成后,模型利用一个选择性集合策略生成一系列候选素描图像,之后根据各种特征的一致性将这些候选素描图像融合,最终生成一个逼真的人脸图像。Xiao等人[32]对E-HHM进行了拓展,保留了素描-人脸合成功能的同时增加了人脸识别功能。Wang等人[33]在E-HMM之上利用局部证据函数构建输入素描块与目标照片块之间的关联,引入马尔可夫随机场(MRF)模型,并结合兼容性函数,优化目标照片块在重叠区域的一致性,提高了合成图像的质量。
.................................
第二章 相关背景知识
2.1 生成对抗网络原理
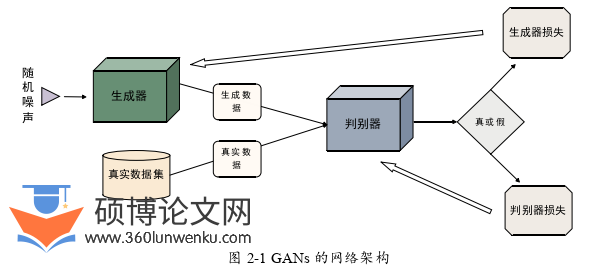
GANs[9]包括两部分:生成器(Generator)和判别器(Discriminator)。GANs的网络架构如图2-1所示。
计算机论文怎么写
生成器的目标在于生成尽可能逼真的数据,以便欺骗判别器。生成器接收一个随机噪声向量作为输入,并通过一系列的网络层转换这个输入向量,最终输出一个与真实数据相似的数据实例。生成器在训练过程中不断学习如何改进生成的数据,以使其越来越难以被判别器区分。
判别器的任务是区分输入的数据究竟是来自真实数据集,还是来自生成器。它是一个二分类模型,输出一个标量,表示输入的数据是真实数据集的概率。判别器在训练过程中通过不断学习如何更好地区分真实数据和生成数据,以提高判定的准确性。
GANs的训练过程由生成器和判别器的对抗组成。训练生成器的过程如下:固定判别器,同时更新生成器的参数,让判别器正确识别生成数据的概率达到最低。判别器的训练过程为:固定生成器,同时用真实数据和生成数据训练判别器,让判别器具有正确区分真实数据和生成数据的能力。GANs整体训练是一个迭代过程,生成器和判别器交替训练,直到达到某种平衡状态。
.................................
2.2 残差网络原理
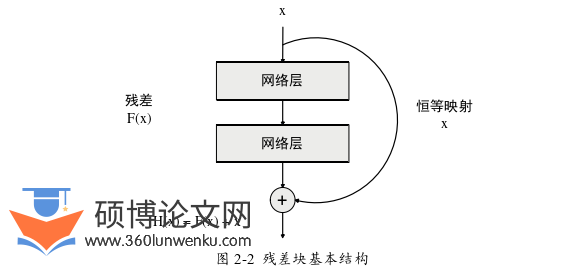
残差网络(Residual Network, ResNet)[41]是深度学习领域的一个重要里程碑,解决了深度神经网络训练中的退化问题,即随着网络层数的增加,训练误差反而会上升。残差网络的核心是残差块(Residual Block)。残差块的思想是引入一条“捷径”(shortcut connection或skip connection),允许数据绕过一些层直接传播,其基本结构如图2-2所示。
计算机论文参考
如图2-2所示,若将网络层看成是映射函数,则x为某段网络的输入,F(x)为这段网络所代表的函数变换,H(x)为这段网络的输出结果。传统网络结构学习的是H(x),如公式2-3所示: ????(????)=????(????)+???? (2-3)
残差网络通过恒等映射,令H(x)等于x。令网络的学习目标从H(x)变成“残差”F(x),如公式2-4所示: ????(????)=????(????)−???? (2-4)
学习“残差”的好处在于:若很难将网络的输入映射到目标结果,可以令H(x)等于x,这样F(x)也就等于0,即相当于这段网络不存在。这体现了残差网络的“保底”思想,也就是:加入了更多的网络层,模型的性能可以不变,但不能变得更差。凭借“保底”思想,ResNet大获成功,在多个重要的视觉识别任务上达到了前所未有的性能。
............................
第三章 基于双视损失优化的生成对抗网络素描-人脸合成 ............... 20
3.1 基于 Pix2PixGAN 素描-人脸合成 ......................... 20
3.1.1 基本原理 ............................. 20
3.1.2 损失函数 ................................ 22
第四章 基于 CSFF-GAN 的素描-人脸合成方法......................... 42
4.1 CSFF-GAN 的基本原理 ......................... 42
4.2 CSFF-GAN 的损失函数 .................................. 46
4.3 CSFF-GAN 的网络结构 .................................. 48
第五章 基于 CFA-GAN 的素描-人脸合成方法 ................................. 56
5.1 CFA-GAN 的基本原理 ................................. 56
5.2 CFA-GAN 的损失函数 ..................................... 60
5.3 CFA-GAN 的网络结构 ................................... 61
第五章 基于CFA-GAN的素描-人脸合成方法
5.1 CFA-GAN的基本原理
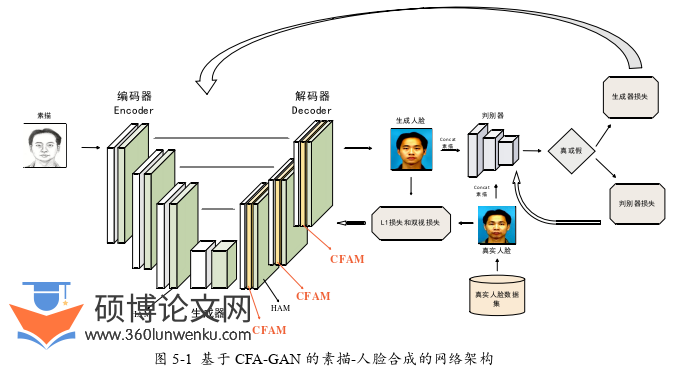
CFA-GAN 的网络架构(如图5-1所示)和CSFF-GAN的网络架构基本相同,这两个模型的主要区别是生成器的结构,CFA-GAN在使用HAM强化生成器的特征提取能力和图像重建能力的同时,还使用CFAM对特征融合过程进行了优化。
计算机论文参考
CFA-GAN解码阶段HAM的作用和CSFF-GAN解码阶段HAM的作用相同,二者的不同在于前者输入的特征图要经过CFAM。CFAM是CFA-GAN的核心机制,旨在解决“U-Net型”生成器特征融合阶段的信息冗余问题。
“U-Net型”生成器之所以能够在图像转换领域广泛使用,是因为该结构将编码阶段得到的特征图传递给解码器进行特征融合,使解码器能够利用被转换图像中的许多信息(例如生成人脸图像时可以利用素描的轮廓),不需要重新生成这些信息,使“U-Net型”生成器在保证生成图像质量的同时,拥有很高的生成效率。不过“福兮祸之所依”,虽然特征融合可以让生成器更加充分地利用被转换图像中的信息,但这些信息中往往存在冗余信息,且生成器对特征图中的所有信息“一视同仁”,这就导致特征融合后所得的特征图,其冗余信息被生成器多次学习,进而干扰生成器学习其他的有效信息,从而使生成图片的质量下降。
..........................
第六章 总结与展望
6.1 本文工作总结
在素描-人脸合成任务上,GANs表现出色,但生成的人脸图片在颜色、轮廓和纹理方面仍存在不足,有一定的提升空间。为了生成更高质量的人脸图片,本文在深入研究基于GANs的素描-人脸合成后,设计了一个可以充分利用人脸特征的损失函数、一种拥有良好特征提取能力和图像重建能力的GAN和一种能够消减冗余信息干扰的GAN。本文通过多组严谨的实验,从主观和客观两个方面对本文的损失函数和模型进行充分的实验分析,最终证明本文所设计的损失函数和模型具有一定的优越性。本文的主要工作可总结如下:
(1)设计出DV Loss,解决了传统GANs在素描人-脸合成任务中未能充分利用人脸特征,导致其生成的人脸图像轮廓不清晰、颜色不准确、纹理不精确的问题。DV Loss用预训练的VGG19处理生成人脸和真实人脸的各层次特征(轮廓、颜色、纹理、语义),用预训练的CLIP进一步处理生成人脸和真实人脸的人脸语义特征,分别计算损失并求和,让GANs生成的人脸图像在各个特征层次上都向真实人脸逼近,从而提高生成人脸图像的质量。实验的人眼主观评测结果和客观指标评测结果都表明:引入DV Loss能令GANs生成人脸图像的轮廓更清晰、颜色更准确、纹理更精确。
(2)设计出CSFF-GAN,解决了传统GANs因特征提取能力和图像重建能力不足,导致其生成的人脸图像的视觉相似性评分和结构相似性评分不高的问题。CSFF-GAN在生成器中使用了层级注意力模块(HAM),该模块基于自注意力机制对生成器的编码过程和解码过程进行了优化,提高了生成器的特征提取能力和图像重建能力。同时,设计并使用一种跨尺度特征融合跳跃连接(CSFFSC)帮助CSFF-GAN进行特征融合,CSFFSC利用跨尺度跳跃连接(CSSC)对此前所得的特征图进行步长更大的下采样,得到的新特征再由HAM做进一步处理,这些由CSSC得到的特征为编码阶段(图像重建)提供更多信息,让生成器的图像重建能力得到进一步加强。CSFF-GAN还使用DV Loss进一步提升其生成人脸图像的质量。实验的人眼主观评测结果和客观指标评测结果都表明:和传统GANs相比,CSFF-GAN生成的人脸图像在视觉相似性和结构相似性方面具有一定的优势。
参考文献(略)