1 绪论
1.1 研究背景及意义
随着人工智能和计算机视觉、大数据等技术的迅速发展,无人机等智能设备的研究进入了一个新的阶段。无人机综合了软件技术、硬件控制、动力学、机械制造等各种先进技术,是一种跨学科专业技术的智能设备。无人机具有高机动性、高灵活性、复杂地形高适应性等优势,不仅在军事上具有重要用途,在抢险救灾,地质勘测,植保作业,物流配送等诸多民用邻域也具有广阔的应用前景。
在复杂的弱信号环境中,无人机依靠机载设备进行自主飞行是无人机发展的必然趋势。无人机实现自主导航,要求无人机能够在复杂的环境中实现自主定位;能够准确感知周围环境信息;能够理解任务并实现路径规划[1]。在实际应用场景中,无人机所处的环境是未知的,因此没有可靠的地图信息进行自身定位。同时,由于缺乏精确的自身位置估计,无人机同样无法完成周围环境地图的构建。基于视觉的同时定位与建图(Visual Simultaneous Localization and Mapping, VSLAM)任务是完成无人机的定位与地图构建,而视觉里程计(Visual Odometry,VO)是 VSLAM 的子问题,主要完成无人机的定位任务。VSLAM/VO 使得无人机能通过相机由相应的运动估计算法估计出当前的位置和姿态。单目相机具有价格便宜、体积小、功耗小的特点被无人机广泛使用。目前,VSLAM/VO 算法研究取得了很大的进展,但是仍然存在着很多挑战。
第一,视觉里程计通常基于几何信息估计自身位姿及运动,他们不提供对周围环境的高层次理解。随着无人机技术的发展,需要对周围环境的物体进行识别分析。深度学习技术的突破,为无人机环境感知技术提供了新的思路。在视觉里程计中,通过视觉传感器感知周围环境,不仅可以理解外部环境还能够利用外部环境信息来提升自己定位的准确度。传统的视觉里程计主要是基于空间几何[2],现在越来越多的研究者开始着眼于将深度学习与视觉里程计结合,通过将物体语义信息进行识别从而进行自主定位[3-5]。
...............................
1.2 国内外研究现状
在 VSLAM/VO 技术发展的早期阶段,基于稀疏特征的间接法(简称特征点法)一直是研究的主流方向。然而随着处理器技术的进步,基于稠密光度信息的直接法(简称直接法)已经可以在高性能计算设备上运行[8]。特征法首先从采集到的图像中提取特征并连续跟踪,建立图像帧之间的联系,构造世界坐标系下的特征在图像坐标下的投影误差为目标函数;再通过最小化视觉投影误差来估计相机运动和空间三维地图。直接法将图像帧对应像素之间的光度误差作为目标函数,通过非线性优化寻找使得目标函数达到最小时的解[9]。特征法的计算复杂度主要集中在特征提取、跟踪和目标函数优化,而直接法需要利用整幅图像的光度差来优化目标函数,相比于特征法而言其计算复杂度较高,很难在嵌入式计算环境下实时性运行。但是直接法充分地利用了图像信息,计算精度高于特征法。利用整幅图像中全部像素光度信息的 VSLAM/VO 技术称为稠密法,而利用图像中稀疏特征的VSLAM/VO 技术则称为稀疏法[10]。为了在计算精度和实时性之间取得平衡,研究人员又在稠密方法和稀疏方法的基础上提出了半稠密方法[11],即利用特征邻域内像素的光度信息或者利用图像梯度变化较大像素的光度信息,从而减少了计算量,提高算法运行效率。
香港科技大学沈劭劼[14]等人开源的单目视觉惯导框架 VINS 是 SLAM 邻域的经典之作,VINS 是基于优化和滑动窗口的 VIO,使用 IMU 预积分构建紧耦合框架,还具有自动初始化、重定位、闭环检测和全局位姿优化的功能。国防科技大学的 Zhiqiang Long[15]等人提出一种基于深度神经网络的单目视觉里程计 UnDeepVO,通过使用无监督学习估计位姿和深度。Liangliang Pan[16]等人提出一种基于特征均匀提取与精确匹配的视觉里程计 UFSM VO,通过设置自适应特征阈值,在每个局部区域选择有限数量的特征来进行统一特征提取,通过基于运动模型的双重验证来实现精确匹配,在 KITTI 数据集下取得了良好的精度。Xiangwei Wang[17]等人提出了一种使用几何约束的单目视觉里程计尺度恢复方法,通过几何模型,以匹配的特征点为顶点,使用 Delaunay 三角剖分方法将输入图像分割为多个三角形,完成视觉里程计的尺度恢复。Dingfu Zhou[18]等人一种基于平面的单目视觉里程计尺度估计方法,利用平面及相机高度的鲁棒性,分治式估计图像的绝对尺度,并且提出一种有效的比例矫正策略,以减少单目视觉里程计的尺度漂移问题。
............................
2 视觉里程计的理论基础
2.1 相机模型
视觉里程计通过相机采集图像,图像中包含带有亮度和色彩信息的像素点。相机通过光学系统接收三维世界中的反射光,并将其投射到相机的图像平面上,然后由相机对接收到的光线进行测量,最终形成可观测到的像素。通常使用几何模型来描述 3D 坐标点在 2D 图像平面上的投影,针孔模型描述了穿过针孔的光束与投射在针孔背面图像之间的关系。相机镜头上的光学元件会导致光在成像平面上的投影出现畸变,因此我们可以使用针孔模型与畸变模型来表示相机成像的过程。
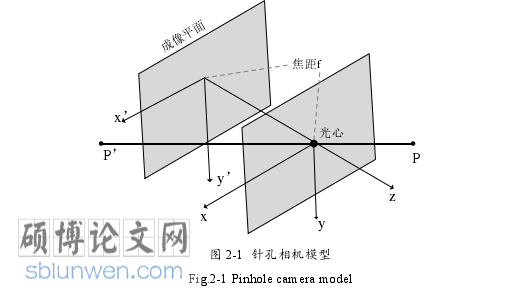
2.1.1 针孔相机模型
针孔相机模型如图 2-1,描述了将三维世界中的物体反射光通过微小孔洞投射到二维图像的过程D 点在世界坐标系下的坐标可以表示为 ( ,,)w w w wP X Y Z ,3D 点相机坐标系下可以表示为 ( ,,)c c c cP X Y Z ,相机坐标系下 3D 点在图像中所对应的坐标可以表示为’ ’ ’ ’P ( X, Y ,Z) ,成像平面中像素坐标系的坐标为 p(u, v) ,其中 f 表示焦距。
.计算机论文怎么写
2.2 视觉里程计的状态估计方法
视觉里程计描述 3D 空间中对象的运动,该空间由三个轴组成,因此可以使用三个坐标来指定空间中点的位置。刚体在 3D 空间中的运动不仅具有位置,而且还具有其自身运动特征,相机也可以视为 3D 空间中的刚体,因此位姿是指相机在空间中的位置和朝向。
在现实情景中,通常有世界坐标系和相机坐标系两个坐标系,例如可观察到的一个向量 p,pc 向量 p 在相机坐标系下的坐标,pw 表示向量 p 在世界坐标系下的坐标。图 2-4 描述了 p 在不同坐标系下的不同表示,物体的运动与坐标系之间的运动相同,是通过刚体运动,即平移与旋转来完成,通常使用正交矩阵 T 来表示不同坐标系下的转换关系。在运动过程中,由于 p 本身不发生改变,因此使用欧式变换来描述不同坐标系下的转换。
视觉里程计是通过由亮度与颜色矩阵表示的图像来推断相机的运动,在实际的图像采集过程中,相机会以不同的视角进行移动,相机采集图像通常可以达到每秒二十多帧的速度,因此每帧图像中相机的视角变化很小。根据这个条件,可以在图像中选取一些不会发生变化的路标点,通过在相邻近帧中找到相应的路标点来估计相机的位姿。这些不发生变化的路标点也称为特征点。
特征点选取是使用图像中特殊的位置,比如图像中的角点、边沿等。以角点为例,通过在图像中选取角点作为特征点,然后再邻近帧中识别角点,获得其相对应的关系。角点具有可变性,传统的角点有 FAST 角点、GFTT 角点等。实际应用中,相机所采集的图像中,比如屋顶,在当前帧中属于角点,但是当我们对相机进行平移或者旋转之后,屋顶外观将发生变化,此时将不具备角点的特性。针对交角点随相机采集姿态发生变化的问题,随后出现了更加稳定且高效的 ORB、SIFT、SURE 等特征点。
............................
3 基于多尺度视觉特征提取的轻量级语义分割算法 .............................. 15
3.1 语义分割算法研究概述 ....................................... 15
3.1.1 语义分割方法相关工作 ................................................ 15
3.1.2 语义分割性能的评价机制 .............................................. 17
4 基于空间和语义信息融合的视觉里程计方法 .................................. 27
4.1 空间和语义信息融合的局部优化建模 ................................. 27
4.1.1 光度误差模型 ....................................... 27
4.1.2 语义误差模型 .......................................... 30
5 总结与展望 .................................... 41
5.1 总结 .......................................... 41
5.2 展望 ......................................... 41
4 基于空间和语义信息融合的视觉里程计方法
4.1 空间和语义信息融合的局部优化建模
4.1.1 光度误差模型
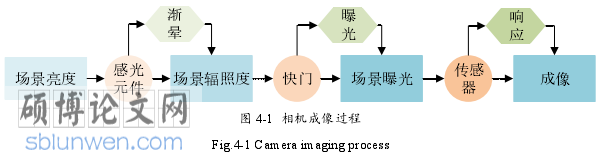
直接法是根据图像的灰度信息来估计相机运动与点的投影,通常直接法中以灰度值不变假设作为前提。在实际的工作过程中,为保持采集图像的质量[59],相机预先对信息进行调整,如伽马矫正、白平衡、饱和度、自动曝光等。经过调整后的图像更符合人眼观测习惯,却改变了物体原始的灰度值,不符合直接法灰度值不变假设。
相机成像时,通过感光元件接收场景亮度(scene radiance)获得场景辐照度(scene irradiance),按下快门时获得场景曝光,经过相机传感器调整得到像素灰度值形成图像。通过分析成像过程,图像灰度值与原始辐照度之间的差异由感光元件、曝光、以及相机传感器引起。
计算机论文参考
5 总结与展望
5.1 总结
视觉里程计技术处在高速发展阶段,现阶段涌现出了很多优秀的开源系统及学术成果。本文以计算资源受限的无人机作为应用背景,通过对主流视觉里程计技术进行分析研究,提出了一种基于空间和语义信息融合的视觉里程计方法,实现了无人机在无导航信息的环境下,实现自主定位。主要的研究成果如下:
1)提出了一种基于多尺度视觉特征提取的轻量级语义分割方法:LitNet,网络基于编码-解码结构,在保证图像分割精度的同时实现快速推理。编码部分的特征提取模块融合空洞卷积增大感受野保留图像空间信息;多尺度提取模块利用融合空洞卷积空间金字塔结构获取多尺度上下文。在解码部分使用三次融合上采样,不仅能保留图像细节与边缘信息还能更精确的恢复图像的多尺度特征。通过与经典分割模型进行比较,本文所提方法模型的 MIoU 达到 69.01%且平均分割速度维持在 25.7 FPS。
2)提出了一种空间和语义信息融合的视觉里程计方法:SPSVO,将相机帧与语义分割标签同时作为输入进行位姿估计与局部建图。提出了一种基于直接法的视觉里程计框架,在建立局部地图时使用特征点法进行初始化,跟踪部分使用直接法,最后使用融合光度误差和语义误差的滑动窗口优化模型进行局部地图优化。本文所提方法在 NVIDIA Jetson TX2 平台上进行实验。精度方面,本文算法在 TUM-mono 数据集上绝对轨迹的均方根误差 0.23 以下;时耗方面本文算法可达到 41.5 FPS,本文所提算法更好地平衡了视觉里程计的时耗与精度。
参考文献(略)