本文是一篇计算机论文,本文针对大模型应用到农业虫害识别领域过程中存在的问题,提出了一系列解决方案。首先,针对大模型全量微调难,提出基于参数高效微调CLIP的跨模态农业虫害识别模型Dual-(PAL)G,通过引入参数高效微调方法使CLIP获得农业虫害识别能力,在农业虫害数据集以及通用公开数据集上验证了Dual-(PAL)G的有效性和迁移性;
第一章 绪论
1.1研究背景与意义
一些农作物和经济作物的产量受虫害影响较大,如枸杞、水稻、葡萄等,它们易受多虫害侵袭,抗虫性较差,易受病虫害侵害,严重影响产量和质量,造成大量的经济损失。如何精准快速的识别农业虫害,及时采取相应的防治措施,减少农药使用,对遏制病虫害进一步的扩散,提高农作物的产量和质量有着至关重要的作用。
人工病虫害识别通常是农业领域的专家与技术人员进行观察和鉴定,识别效果受限于时间、专家能力、设备成本等等,不利于推广[1]。随着深度学习的发展,深度病虫害识别方法在农业中取得多个成功应用[2]。传统的深度学习农业病虫害识别通常在单一作物虫害、单一场景以及单模态信息上训练,训练的专有模型虽然有着优秀的表现,然而泛化能力不足,不具备迁移能力,并且模型设计和训练成本高。随着大模型技术发展,在海量数据上预训练出了很多通用模型(即大模型),通过全量微调大模型,将通用知识迁移到特定领域成为一种有效的解决方案之一,如多模态大模型CLIP[3],它在4亿图文对进行对比自监督预训练,在图像识别、分割、目标检测上都有着优秀的表现,因此将CLIP强大的通用表示能力引入农业,能更快的收敛,实现精准快速的虫害的跨模态识别,是更有前景、更能满足农业发展的方法。
然而全量微调大模型不仅对GPU资源要求高,而且需要较大规模的数据避免过拟合,这大大限制大模型在农业虫害领域的使用。参数高效微调(Parameter-Efficient Fine-Tuning,PEFT)方法是一种只需极低算力的微调大模型的方法,并且能够达到与全微调媲美的性能,无需大规模的数据集。然而,不同的PEFT方法以及不同模态端的设置都会对于虫害识别起到的作用不同,盲目的组合可能会造成性能下降,因此有必要进行大量实验研究。
............................
1.2国内外研究现状
深度学习模型在农业领域应用广泛,本文统计了深度学习驱动的农作物病虫害识别研究工作,并依据模型规模分为两类:基于专有小模型驱动的和基于预训练模型微调驱动的农业病虫害识别研究进展。
1.2.1基于专有小模型驱动的农业病虫害识别研究进展
Bhattacharya等[4]在卷积神经网络(CNN)模型基础上添加两个全连接层来专门识别三种水稻叶片患病程度和患病类别,在1500张健康与患病的叶子上达到了94%识别准确率,在500张三类水稻叶片病害数据上达到了78.44%的准确率。Sudhesh等[5]研究了基于动态模式分解(Dynamic Mode Decomposition,DMD)的注意力驱动预处理机制来定位感染区域,他们使用迁移学习和机器学习模型对原始图像和DMD预处理图像的深度特征进行学习。Devi等[6]使用人工特征提取结合序列处理神经网络进行棉铃虫和稻虫检测,首先采用模糊c均值分割对图像进行分割,然后采用灰度共生矩阵、Sobel算子和多通道特征提取混合集合进行手动特征提取,最后送入长短期记忆网络和循环神经网络处理特征并实现分类。Huang等[7]结合了迁移学习、CNN和三种超参数机器学习来提取番茄害虫特征,最后使用贝叶斯优化的三个超参数机器学习分类器对提取的害虫特征进行分类,在8个害虫数据集上获得了出色的分类性能,分类准确率为97.12%。Bao等[8]依据棉花蚜虫侵害的严重程度分为四个等级,并建立棉花蚜虫数据集,将坐标注意(CA)机制嵌入到特征提取结构中,提出了CA_DenseNet_BC_40轻量级网络模型,对自然田间条件下棉花蚜虫危害程度进行分类,准确率为97.3%。
..............................
第二章 相关理论与技术发展
2.1 视觉语言基础模型
2.1.1 预训练方法
视觉语言基础模型(Visual-Language Foundation Models,VLFMs)预训练的方式在不断发展。早期VLFMs在ImageNet[15]等千万级别数据集中进行有监督学习预训练,这需要大量的标注数据,但是标注数据的获取通常需要人工参与,随着数据集规模扩大,准确标注数据的成本不可估量,且耗费时间,特别是在医疗诊断、语音识别等专有领域,获取大规模标注数据极其困难。并且监督学习训练出来的模型在面对未知的数据时不具有泛化性。监督学习无法处理未标注数据,然而实际中往往存在大量未标注的数据,这限制了监督学习在某些场景下的应用。无监督与自监督学习的出现解决了这一问题,自监督学习很快成为VLFMs的主要预训练方式。
自监督学习是一种特殊的无监督学习,其核心在于选择合适的预训练目标与pretext task,pretext task是对目标任务有帮助的任务,简化了原任务的求解。如解决图像识别任务,其可以表达为????????(????):????→????,最终目的是获得具有推理能力的????,pretext task的作用就是可以近似获得????,如Auto-encoder(掩蔽恢复的一种方法),表示为????????(????):????→????,因为重建x的过程中能够学习到????的内在关系,这有利于学习????????(????),从而间接解决图像分类问题,关键是无需标签信息。在视觉语言领域自监督学习方法可分为两类:对比式、生成式。
计算机论文怎么写
................................
2.2 视觉语言基础模型微调范式
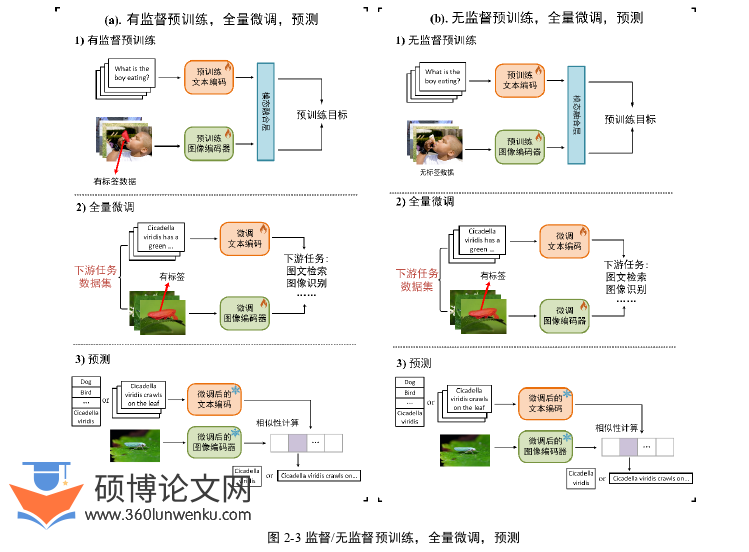
在特定下游任务微调VLFMs能大大提高收敛速度与下游任务性能。随着VLFMs的预训练方式改变,模型的规模也大大提高,进而微调范式也随之转变。依据VLFMs的预训练方式转变过程,微调范式可分为三个阶段:(1)监督/无监督预训练,全量微调,预测;(2)自监督预训练,Few-shot / Zero-shot,预测(3)大模型,参数高效微调,预测。(1)(2)是目前既定的微调范式,(3)是处在快速发展之中的范式,并且有大量工作证明其有效性,是本论文主要研究的内容。
2.2.1监督/无监督预训练,全量微调,预测
如图2-3所示,有监督与无监督的预训练模型学习到的表征有限,通常针对单一的任务,如视觉问答[37]、视觉推理[38],因此需要有监督的全量微调(Full fine-tuning)预训练模型。该范式使用预训练模型初始化网络,将与自己问题相关的Softmax层替代源网络的Softmax层,然后使用特定下游任务数据集对网络训练,并且依据数据量多少选择冻结的网络层数。因此全量微调本质上便是对预训练模型继续训练,目的是缓解数据样本、计算资源不足的情况。
2.2.2自监督预训练,Few-shot / Zero-shot,预测
无监督缓解了对标记数据的依赖,然而它学习到的迁移学习知识依然不够丰富。自监督(Self-supervised)预训练能够有效的弥补这一缺陷。在视觉语言领域中自监督利用辅助任务(Pretext task)从原始的图片或文本中挖掘潜在的监督信息,学习到更高质量的迁移学习知识,从而提高预训练模型的迁移学习能力,因此这种范式在预测阶段大多进行few-shot学习或zero-shot,即仅通过少量微调或不微调大模型(如图2-4.a所示)。
...........................
第三章 基于参数高效微调方法的跨模态虫害识别模型研究 .............. - 26
3.1 研究动机 ....................................... - 26
3.2 多参数高效微调模型——Dual-(PAL)G ..................... - 27
3.3 实验数据 .................................. - 32
第四章 长尾分布场景下多模型辅助增强的农业虫害识别模型研究 .. - 43
4.1 研究动机 ............................. - 43
4.2 多模型辅助增强的农业虫害识别模型——MALL ................................. - 44
第五章 基于知识蒸馏方法的轻量级农业虫害识别模型....................... - 57
5.1 研究动机 ............................................. - 57
5.2 知识蒸馏模型结构 ....................... - 58
第五章 基于知识蒸馏方法的轻量级农业虫害识别模型
5.1 研究动机
由表3-4和表3-5的数据可知,Dual-(PAL)G额外引入的参数中,GCS-Adapter模块占据了绝大部分的参数量,同时深层Prompt导致GPU内存占用上升。为了减少参数高效微调方法的冗余参数量和内存占用,在工程应用层面上更好地利用这些模型,同时尽可能的保留模型性能,本章对Dual-(PAL)G模型的PEFT模块进行轻量化设计,并进行知识蒸馏。
知识蒸馏是一种模型压缩技术,旨在将复杂模型(教师模型)的“知识”迁移到更轻量的小模型(学生模型)中,使其在保持较高性能的同时降低计算成本和存储开销。其核心思想是软标签:教师模型的预测结果(如logit分布)被称为“软标签”,真实标签被称为“硬标签”(Hard Labels),相较于原始的“硬标签”,软标签包含更多信息(例如类别间的相似性),能帮助学生模型更好地学习决策边界。
本章使用基于输出的知识蒸馏方法[88],即Logits知识蒸馏。如图5-1所示,该蒸馏方法让学生模型直接模仿教师模型的输出概率分布(即软标签),在蒸馏过程中使学生模型同时拟合两种监督信号:(1)硬标签损失(Hard Loss): 学生预测与真实标签的交叉熵损失,公式如5-1所示;(2)软标签损失(Soft Loss):学生预测与教师软标签的KL散度损失(Kullback-Leibler Divergence Loss),公式如5-2所示。
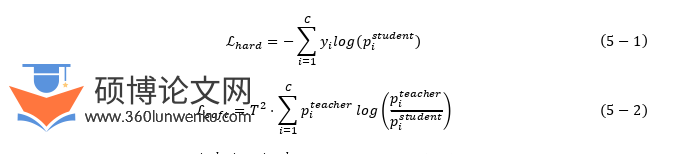
计算机论文参考
......................
第六章 总结与展望
6.1 研究总结
随着大模型的快速发展,将大模型的知识迁移到农业虫害识别领域是一种有效的解决方案,然而这种方案面临算力、数据长尾分布等挑战。本文针对大模型应用到农业虫害识别领域过程中存在的问题,提出了一系列解决方案。首先,针对大模型全量微调难,提出基于参数高效微调CLIP的跨模态农业虫害识别模型Dual-(PAL)G,通过引入参数高效微调方法使CLIP获得农业虫害识别能力,在农业虫害数据集以及通用公开数据集上验证了Dual-(PAL)G的有效性和迁移性;其次,针对长尾分布数据引起的模型难以学习到有效、平衡的特征表示的问题,引入了基于OminiControl图像编辑的样本增强方法,并提出多分支辅助logit学习模型MALL,提高模型在增强样本上的特征学习能力,并在长尾分布的农业虫害数据上进行实验,验证MALL能有效学习长尾分布数据的特征。为更好的在农业虫害识别领域应用,对Dual-(PAL)G进行轻量化设计和知识蒸馏,大大减少额外引入的参数量与GPU内存占用。本论文提出的方法同样适用于存在相同问题的其他领域。
具体研究内容如下:
(1)针对大模型全量微调难,提出基于参数高效微调CLIP的跨模态农业虫害识别模型Dual-(PAL)G。在极少的算力资源下通过PEFT方法使得CLIP模型的知识能够高效的驱动农业虫害识别,获得优秀的识别效果。通过大量实验探索,选择合适的PEFT方法以及相应的模态设置,提高模型的学习能力,并在PEFT模块内嵌入了可学习的门控单元,将Prompt、Adapter、LoRA集成起来,实现自动化平衡不同模块对特征学习产生的贡献。然后设计了GCS-Adapter增强跨模态交互,提升农业虫害细粒度识别能力。最后在公开农业虫害数据集上进行图文对比学习,在仅使用15%的样本数量就达到了先进水平。
(2)针对传统样本增强与基于生成模型的样本增强策略的弊端,引入了基于OminiControl图像编辑的约束性样本增强策略。该策略使用具有文本编辑图像能力的OminiControl大模型对农业虫害数据进行编辑。首先针对虫害的背景、自然条件、害虫的位置形态、害虫数量等方面设计多个合理的提示文本,用于编辑图片;其次,筛选可用的增强样本,避免引入负样本,最后使用Dual-(PAL)G直接对增强样本进行推理,证明增强样本的合理性和可用性。
参考文献(略)