本文是一篇计算机论文,本文从性能以及效率综合对比,选择双编码器模型结构为检索模型实例,通过微调手段将其应用到规模较小的数据集中,模型在下游任务上仍然展现了良好的性能。之后通过采用不同的负采样策略进一步优化了模型性能,为集成自动化需求追踪提供了一种可能的选择。
1绪论
1.1课题研究背景与意义
近年来,软件产业发展快速,随着用户需求越来越多样化,软件公司的开发压力也越来越大。为了提供更好的服务,软件公司需要迅速响应用户的反馈。面对不断增加的用户需求和快速的版本迭代,大部分公司采用了敏捷开发模式。然而,频繁的交付不仅给开发部门带来巨大的压力,也对运维部门提出了严峻的挑战。
在传统应用开发模式中,开发人员完成代码开发和测试后,将代码打包成可执行文件,然后交给运维人员在服务器上部署和运维。在这种模式中开发环境和运维环境是割裂的,开发人员往往不了解运维环境,忽视了运维环境的复杂性,导致运维工作中遇到诸多困难。造成这种情况的根本原因在于开发人员与运维人员的关注焦点不一致,开发人员更关注技术的可行性,而运维人员更关注工作环境的稳定性,当系统发生故障时,由于两者的关注焦点不一致,容易陷入矛盾,从而降低软件交付速度。为了解决这一问题,业界提出了DevOps的概念。
DevOps[1](Development and Operations)是一种文化和实践的结合,旨在促进软件开发(Dev)和信息技术运维(Ops)之间的沟通、协作和集成,以加快软件交付的速度、提高软件质量和增强服务稳定性。它源自敏捷软件开发,并进一步强调了开发与运维团队之间的紧密合作。DevOps作为一种软件开发和交付方法论,已经成为许多组织实现快速、高质量软件交付的重要手段。在传统开发的时代里,大部分软件的发布周期都是以月计的,甚至可以用年计,而在DevOps的指导下,软件开发周期已经被缩短到以天计了。
.........................
1.2国内外相关研究工作进展
1.2.1 DevOps发展及应用情况
Kent Beck[6]通过强调代码持续集成的多种好处,为持续集成概念的形成奠定了基础。Jez Humble[7]等人于2006年进一步提出了在软件交付过程中使用部署流水线的概念。这些观点为DevOps的发展提供了理论支撑。DevOps的核心理念是将持续集成、持续部署与持续交付等流程整合进运维活动中,实现运维的自动化。这一理念旨在通过自动化流程,加速软件的开发和部署,提高产品质量和交付效率。
实现DevOps技术链需要多个领域的支持和整合,涉及领域包括版本控制、自动化构建与测试、持续集成、持续交付、容器化平台、配置管理、微服务架构、日志管理以及监控等[8]。通过整合这些领域的技术,DevOps不仅加快了软件开发和交付的速度,还提高了软件开发过程的透明度和可预测性。
随着各大公司的投入加大,加速了技术链中各部分技术的演进和落地,DevOps实践得到了广泛的应用和推广。通过采用开源技术和工具,公司能够更容易地构建和维护自己的DevOps流程,从而更好地响应市场变化,满足客户需求。这一发展趋势标志着软件开发和运维领域向着更高效、更协作、更自动化的方向进步。在工业领域,像谷歌、微软和亚马逊这样的公司已经采用了DevOps平台和工具来促进快速可靠的软件交付[8]。亚马逊的云平台AWS就是将DevOps理念投入实际生产的典型商业化例子[1],主要由CodeCommit、CodePipeline和CodeDeploy三部分组成。CodeCommit是一个高可用的代码仓库服务,提供稳定可靠的代码托管功能,与Git兼容,允许开发者通过熟悉的Git命令来管理代码。CodePipeline是一种工作流服务,整合了编译、测试以及部署步骤,优化了从代码提交到产品部署的整个流程。CodeDeploy可以通过在AWS云上动态创建虚拟机来部署应用,支持复杂的部署策略如分批和滚动更新,并能够执行部署前后的自动化检测和验证。通过这些工具,开发者能够自动化复杂的部署和测试流程,减少了对基础设施管理的手动干预,允许团队专注于核心产品的创新。
...............................
2相关理论与技术
2.1深度学习技术
2.1.1预训练语言技术
随着深度学习的发展,深度神经网络在人工智能领域的应用越来越广泛,常见结构包括卷积神经网络、循环神经网络、图神经网络及注意力机制。传统的机器学习方法,需要人工来设计实现特征提取。神经网络模型摆脱了复杂的人工特征工程,可以从大量数据中捕获到有效的特征信息,将高维度的数据转换为低维的分布式数据,降低数据复杂度的同时保留主要特征和结构,实现了数据驱动的自动化特征工程,在许多领域都刷新了SOTA成绩。然而,深度神经网络在训练数据不足时会出现过拟合的问题。由于高昂的标注成本,许多自然语言处理(Natural Language Processing)任务的标注数据量都比较少,此时模型表现往往不如能力有限的浅层神经网络模型。
预训练模型(Pre-Trained Models)可以充分利用大规模的无标注语料,主要方法是使用掩码语言模型(Masked Language Modeling)和下一句预测(Next Setence Prediction)这样的预训练任务进行预训练,由于足量的数据可以使模型学习到更准确通用的语言表示,模型在下游任务上具有更好的泛化能力。预训练模型本质上结合了自监督学习与迁移学习的范畴,通过微调技术更好地将预训练阶段学到的通用知识应用在下游任务中。
早期预训练模型在自然语言处理领域中的应用集中于词向量学习,如Word2Vec、GloVe、FastText等,预训练后的词向量只包含了词汇的语义信息,忽略了上下文信息,无法有效区分一词多义的情况,且基于浅层模型构建,泛化能力不强,当迁移到下游任务上时表现不加。Transformer模型的提出,通过自注意力机制使得模型可以学习到词汇的上下文编码表示,使用下游数据微调模型参数可以使模型有效地迁移到下游任务上,列入,BERT、GPT、T5等预训练模型通过微调在文本分类、翻译等具体任务上当取得了很好的表现。
...............................
2.2 DevOps理论
DevOps旨在通过自动化和持续的过程改进,加速软件的开发和交付,提高软件质量和安全性,并增强团队间的协作。我们着重介绍它的核心理念及实现插件。
2.2.1 CICD理念
计算机论文怎么写
CICD(Continuous Integration/Continuous Deployment)是DevOps理论的核心概念,其中CI(Continuous Integration)代表持续集成,CD(Continuous Deployment)代表持续交付。这一系列实践旨在提高软件开发的速度和效率,同时确保高质量的输出。通过自动化软件的构建、测试和部署过程,尽可能减少人力工作,CICD极大地缩短了从开发到产品交付的时间,提升了软件开发和运维团队的协作效率。
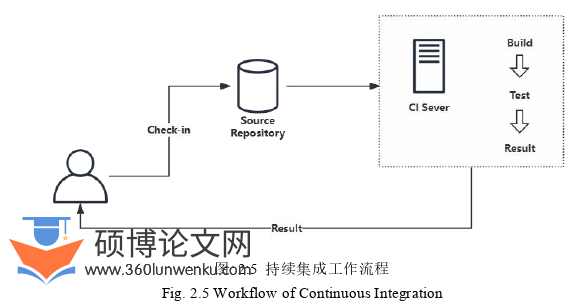
持续集成主要是将指在软件开发过程中,需要开发人员频繁地将代码变更集成到代码仓库中。这样的好处是,可以快速的暴露代码BUG,便于发现和解决集成错误,同时,每次集成都通过自动化构建和测试来验证,可以减少人工干预,提高效率。图2.5展示了一个典型的持续工作流程,开发人员将代码提交到共享仓库,由CI服务器自动化地执行构建、测试任务并生成结果报告,再将结果反馈给开发人员,形成了一个高效的开发闭环。整个工作流程通过自动化技术和持续反馈,可以有效地提高软件质量,减少发布时的风险。
................................
3基于预训练语言模型的需求追踪模型.......................19
3.1引言.......................................19
3.2需求追踪模型训练..............................20
4基于DevOps理念的需求追踪系统设计与实现..............37
4.1系统需求分析..................................37
4.2功能性需求分析.........................38
5结论与展望...............................55
5.1结论...............................................55
5.2创新点...................................55
4基于DevOps理念的需求追踪系统设计与实现
4.1系统需求分析
自动化需求追踪可以帮助定位需求在开发生命周期中的状态和位置,提高项目的透明度。当需求发生变更时,可以快速识别受影响的代码和用例,也减少手动维护需求链接的工作量,能够显著提升软件开发和运维过程的效率和质量。自动化需求追踪对于DevOps理念的实践具有重要的作用。基于传统信息检索模型的追踪方法性能不高,生成的跟踪链接的准确性不足以投入实际应用,因此业界很少将自动跟踪解决方案集成到其开发生命周期中[29]。基于预训练语言模型的信息检索方法为性能带来了显著的提高,本文将基于3.4节训练的BiModel模型开发一个需求追踪系统,并与DevOps的核心功能持续集成交互。在持续集成时自动获取代码提交信息并进行需求追踪,对该功能的实际应用做初步的尝试。
计算机论文参考
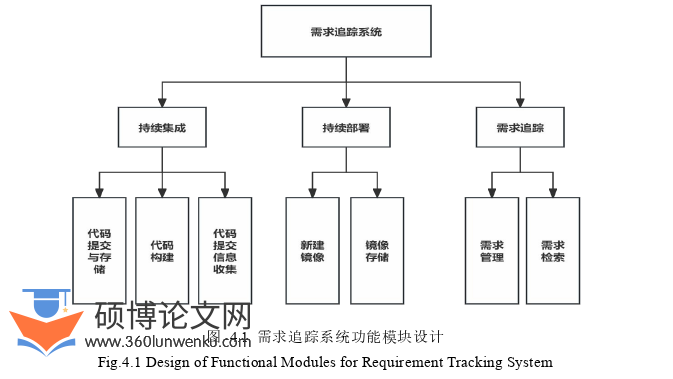
本系统主要面向软件项目开发小组,通过自动化工具实现代码的持续集成和部署功能,并通过BiModel模型实现需求追踪功能,以使整个系统更符合DevOps实践从而优化开发效率。如图4.1所示,整个系统包含3个功能模块,分别是持续集成模块,持续部署模块,需求追踪模块。
.......................
5结论与展望
5.1结论
DevOps作为一种现代软件开发和运维方法论,强调持续的集成和部署,从而快速地开发和交付软件,同时,还需要保证软件产品的质量,这显然对开发团队的软件项目管理能力提出了更高的要求。需求追踪作为软件项目管理的重要一环,实现需求追踪的自动化,可以很大程度上的解放人力,保障项目质量,提高开发效率,这与DevOps理念是不谋而合的。但是,由于传统的检索模型难以保证生成追踪链的准确率,导致难以进入实际应用中。为了解决这一问题,本文详细研究了基于预训练模型的检索模型,并与之前的检索模型进行对比,新模型可以更好的捕获复杂语义信息,在代码搜索数据集上性能得到了显著提升。本文从性能以及效率综合对比,选择双编码器模型结构为检索模型实例,通过微调手段将其应用到规模较小的数据集中,模型在下游任务上仍然展现了良好的性能。之后通过采用不同的负采样策略进一步优化了模型性能,为集成自动化需求追踪提供了一种可能的选择。
本文对将新模型与DevOps平台相结合做出了尝试,通过对持续集成、持续部署和需求管理模块的系统设计与实现,本文构建了一个集成自动化需求追踪功能的代码发布平台。
首先,持续集成模块主要负责代码的存储与构建,并收集需求信息。通过使用Jenkins流水线配置,能够自动执行代码拉取、构建、部署等一系列任务,确保代码质量并及时反馈构建状态。持续部署模块则主要负责创建和存储镜像文件,将构建生成的文件上传到指定路径,保证了软件的持续部署和交付能力。需求管理模块通过应用预训练语言模型,实现了需求制品与代码制品的自动化匹配与追踪功能。具体来说,需求管理模块利用双塔模型对需求和代码进行编码,并通过计算它们之间的相似度来实现自动化需求追踪,这种方法有效提高了需求与代码之间的匹配准确性和工作效率,更符合DevOps理念,进一步提高软件开发效率。
参考文献(略)