第 1 章 绪论
1.1 研究背景及意义
随着计算机和网络技术的飞速发展,人类社会已进入信息时代。根据中国互联网络信息中心(CNNIC)于2018年1月31日发布的第41次《中国互联网发展状况统计报告》显示,截至2017年12月,中国网民规模达7.72亿,普及率达到55.8%1。根据以上数据可以看出,越来越多的人倾向于使用互联网来获取所需要的信息资源。而在当前信息迅猛发展的时代,如何从海量数据中获取有用信息是当前学术界和工业界的一个研究热点。传统的搜索引擎一般都是根据关键字来检索已经排序好的文档,但是随着互联网数据的日益增加,仅仅通过关键字只能获得语言层面信息却无法深层次地获得用户检索需求。此外,其在网页信息利用率中也有着不足之处。在这种情形下,问答系统(Question Answering Systems, QA Systems)应运而生。
1.1 研究背景及意义
随着计算机和网络技术的飞速发展,人类社会已进入信息时代。根据中国互联网络信息中心(CNNIC)于2018年1月31日发布的第41次《中国互联网发展状况统计报告》显示,截至2017年12月,中国网民规模达7.72亿,普及率达到55.8%1。根据以上数据可以看出,越来越多的人倾向于使用互联网来获取所需要的信息资源。而在当前信息迅猛发展的时代,如何从海量数据中获取有用信息是当前学术界和工业界的一个研究热点。传统的搜索引擎一般都是根据关键字来检索已经排序好的文档,但是随着互联网数据的日益增加,仅仅通过关键字只能获得语言层面信息却无法深层次地获得用户检索需求。此外,其在网页信息利用率中也有着不足之处。在这种情形下,问答系统(Question Answering Systems, QA Systems)应运而生。
问答系统是新一代智能搜索引擎,它综合运用了知识表示、信息检索、自然语言处理等技术,允许用户以自然语言提问,并能够向用户返回准确的答案[1]。与传统的关键字检索相比,问答系统能更好地满足用户对快速、高效、准确获取信息的需求[2,3]。从应用角度,问答系统现已应用到各行各业,其降低了人机交互的门槛,非常适合成为互联网的入口。虽然早在二十世纪六十年代问答系统就已产生,但目前开发出的问答系统的表现效果还不够理想。与英文问答系统不同的是,中文自然语言的语句分析较为困难和复杂,其主要在于问题的句法结构复杂,字词的歧义消解,语义表达的灵活多样[4,5]。因此,在中文问答领域,对问题的精准处理可以有效帮助问答系统抽取出更好的答案。本文现阶段答案抽取是从该问题的答案集合中选择最佳答案,可等同答案选择和答案排序,为了保持上下文一致性,本文仍以答案抽取来表示对答案的选择。因此,本文主要从问题分析和答案抽取两个角度对问答系统进行进一步研究。
问题分析主要包括问题分类、主题焦点提取、问题扩展处理。问题分类是将用户所输入的问题归入不同的类别,使系统能够针对不同问题类型采取不同的答案反馈机制得到答案集合。目前问答系统通常使用机器学习算法训练问题分类器来实现用户问题的分类。例如文献[6]中通过利用最邻近(Nearest Neighbors, NN)[7]、朴素贝叶斯(Na?ve Bayes, NB)[8]、决策树(Decision Tree, DT)[8]、稀疏Winnow网络模型(SparseNetwork of Winnows, SNoW)[9]、支持向量机(Support Vector Machines, SVM)[10]等方法分别对问题的表面文本特征进行分类,结果发现SVM的分类效果明显优胜于其他几种方法。文献[11]以字符来表示文本,并通过使用深层卷积神经网络(ConvolutionalNeural Network, CNN)来对句子进行分类。无论是基于统计模型还是基于神经网络模型,这些分类算法均需要先验知识来训练模型。这在实际应用中不仅耗费大量人力物力,还具有一定的局限性。另外,还可以采用一些无监督分类算法(即聚类算法)得到分类结果。例如基于统计的模型有k-均值(k-means)、主题模型等。
..........................
1.2 本文主要研究工作
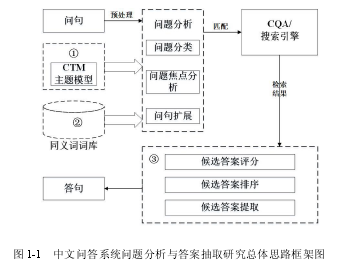
一个完整的中文问答系统主要包括问题分析模块、信息检索模块和答案抽取模块。在本研究中,本文只关注于问题分析模块和答案抽取模块。其中问题分析模块主要包括问题分类、主题焦点分析和问题扩展三个部分,而答案抽取模块包括候选答案评分、候选答案排序和候选答案提取三个部分。本文中文问答系统问题分析与答案抽取研究的总体框架图如图1-1所示。
..........................
1.2 本文主要研究工作
一个完整的中文问答系统主要包括问题分析模块、信息检索模块和答案抽取模块。在本研究中,本文只关注于问题分析模块和答案抽取模块。其中问题分析模块主要包括问题分类、主题焦点分析和问题扩展三个部分,而答案抽取模块包括候选答案评分、候选答案排序和候选答案提取三个部分。本文中文问答系统问题分析与答案抽取研究的总体框架图如图1-1所示。
中文问答系统首先对用户输入的问题进行预处理,将问题中一些语气词、标点符号等停用词进行删除,然后将处理后的问题信息传递到问题分析模块。在问题分析模块中,首先使用主题模型对问题进行细粒度分类,从而获得用户所提问题的隐式类别主题和问题焦点信息。由于用户所提问题与答案中所使用关键词或术语存在可能不一致问题,因此需要使用同义词词库对用户所提问题中的主题焦点进行扩展,进而形成问题扩展。将扩展之后的问题与社区问答(Community-based QuestionAnswering, CQA)或搜索引擎中的问题进行匹配,如果有相似或相同的问题则检索该问题并将该问题的答案输入到答案抽取模块。在答案抽取模块中,通过计算问题与答案的匹配分数,从而将答案进行排序,进而将最佳答案抽取出来并提交给用户。
...........................
第 2 章 相关工作综述
2.1 前言
本文的主要工作是对中文问答系统中的问题进行分析和利用深度学习方法进行答案抽取。前人对于利用主题模型进行问题分析和利用深度学习方法进行答案抽取方面都有很多重要且值得借鉴的工作,这些工作对于本文开展研究具有重要的启发意义。
随着互联网的兴起,问答社区内的问答数据量也呈爆发式增长。许多问答网站对用户所提问题都有字数限制,本文以百度知道8为例,其要求用户所提问题不超过50个字。针对这种长度较短的文本,本文视为短文本。使用长文本主题模型在短文本数据上通常会遇到数据稀疏问题,针对这一问题,短文本主题模型应运而生。而在实际应用中,由于数据具有时间或序列特性,且数据是实时动态变化的,使用静态主题模型重复训练问答社区中的所有问题语料显然是不合适的。为了能快速获得新文本的主题分布并增加实用性,前人提出了多种多样的主题模型。在答案抽取方面,随着深度学习的发展和广泛应用,许多研究工作者开始将深度学习模型应用到问答领域。其通过利用深度学习方法将问题和答案表示成文本向量,然后学习两者之间的关系。本章将对相关领域的研究工作进行全面细致地综述。
......................
2.2 主题模型研究综述
随着存储技术和互联网的进步,问答系统的发展引领了互联网时代知识共享的社会化浪潮。由于问答系统中的问题是以人类自然语言形式提出的,如何正确理解用户意图是当前问题分析中的一个相当有挑战的问题。目前,主流问答社区或网站都是以文本形式展示问题和答案,而在众多文本挖掘算法中,主题模型是非常经典而又常用的。它以低纬度的形式表示大量原始文本,并学习其中的隐式主题。不仅如此,它还可以根据每条信息获得其隐式主题焦点,为后续答案抽取工作提供极大便利。
2.2.1 经典主题模型的相关研究
第 2 章 相关工作综述
2.1 前言
本文的主要工作是对中文问答系统中的问题进行分析和利用深度学习方法进行答案抽取。前人对于利用主题模型进行问题分析和利用深度学习方法进行答案抽取方面都有很多重要且值得借鉴的工作,这些工作对于本文开展研究具有重要的启发意义。
随着互联网的兴起,问答社区内的问答数据量也呈爆发式增长。许多问答网站对用户所提问题都有字数限制,本文以百度知道8为例,其要求用户所提问题不超过50个字。针对这种长度较短的文本,本文视为短文本。使用长文本主题模型在短文本数据上通常会遇到数据稀疏问题,针对这一问题,短文本主题模型应运而生。而在实际应用中,由于数据具有时间或序列特性,且数据是实时动态变化的,使用静态主题模型重复训练问答社区中的所有问题语料显然是不合适的。为了能快速获得新文本的主题分布并增加实用性,前人提出了多种多样的主题模型。在答案抽取方面,随着深度学习的发展和广泛应用,许多研究工作者开始将深度学习模型应用到问答领域。其通过利用深度学习方法将问题和答案表示成文本向量,然后学习两者之间的关系。本章将对相关领域的研究工作进行全面细致地综述。
......................
2.2 主题模型研究综述
随着存储技术和互联网的进步,问答系统的发展引领了互联网时代知识共享的社会化浪潮。由于问答系统中的问题是以人类自然语言形式提出的,如何正确理解用户意图是当前问题分析中的一个相当有挑战的问题。目前,主流问答社区或网站都是以文本形式展示问题和答案,而在众多文本挖掘算法中,主题模型是非常经典而又常用的。它以低纬度的形式表示大量原始文本,并学习其中的隐式主题。不仅如此,它还可以根据每条信息获得其隐式主题焦点,为后续答案抽取工作提供极大便利。
2.2.1 经典主题模型的相关研究
LSA主题模型是最早的主题模型,其和向量空间模型(Vector Space Model, VSM)一样使用向量来表示词和文档,并将两者映射到隐式语义空间,从而去除原始向量空间中的一些噪声。虽然该模型不是真正意义上的概率主题模型,但其为主题模型的发展奠定了坚实基础。尽管LSA主题模型取得了一些成功,但由于其基于奇异值分解(Singular Value Decomposition, SVD),而SVD分解计算过程是非常耗时。另外,
该模型还缺乏严谨的数理统计基础,Hoffmann等人利用概率统计对其进行了扩展。该模型对每个变量以及对应的概率分布和条件概率分布均有明确的物理解释,且其参数学习算法采用最大期望(Expectation Maximization, EM)[38]算法。相对于LSA主题模型来说,PLSA主题模型隐含的多项式分布假设更符合文本特性。但由于EM算法需要反复迭代和大规模计算量,且PLSA主题模型在文档层面并没有提供合适的概率模型使得PLSA并不是完备的生成式模型。因此,人们在此基础上又提出了LDA主题模型。LDA主题模型是完备的生成式模型,也是对PLSA主题模型在贝叶斯理论上的扩展。它解决了PLSA主题模型中生成语义不一致的问题。
LDA主题模型包含词、主题、文档三层结构,是一种无监督机器学习技术,可以用来识别大规模文档集和语料库中隐藏的主题信息。简单来说,语料库中的每篇文本包含 个主题,且其对应一个随机多项式主题分布θ,其中 值可以通过实验来确定。而每个主题对应预处理后的语料库中所有互异单词组成的词汇表(V个单词)中的多项式主题-词分布φ。θ和φ分别表示文档-主题和主题-词的狄利克雷先验分布,
α和β则分别为该分布的超参数。组成文本d的每个词,按照如下步骤进行迭代:先从该文本对应的多项式分布中抽取主题,再从主题对应的多项式分布中抽取词。假设文本有N个词,则将上面的过程重复多次,从而生成有N个词的文档。具体地,LDA主题模型的生成过程可以用下面的数学化语言来描述:
..........................
第 3 章 CTM 主题模型························· 15
第 3 章 CTM 主题模型························· 15
3.2 CTM 主题模型························· 15
3.3 Extended LDA 主题模型··················15
第 4 章 主题焦点词扩展··························23
4.1 前言·····················23
4.2 基于词性特征组合的主题焦点词扩展算法··················23
第 5 章 实验与分析·············31
5.1 前言···························31
5.2 语料说明及实验环境··················31
第 6 章 基于 Bi-LSTM 的答案抽取模型
6.1 前言
前面三章介绍了基于Extended LDA和IBTM的动态主题模型—CTM主题模型,以及从词性特征组合和同义词词库两个角度对问题文本中关键词进行扩展的方法,进行了详细描述和实验验证。通过将扩展之后的文本语料库与动态主题模型进行结合能够有效提取出问题中的主题焦点词,从而有助于从答案集合中选取出最佳答案。传统的基于关键字匹配的答案抽取模型有很多缺陷,同时也无法解决问题和答案中关键词不一致导致的词汇间隙问题。随着深度学习的发展和广泛应用,其通过利用神经网络将问题和答案的向量表示来学习,进而得到问题和答案之间的相似关系,从而抽取出最佳答案。尽管这种答案抽取模型的准确率要远高于传统方法,然而,这些模型大多只考虑了部分问题和答案之间的关系。引入注意力机制并利用问题的向量表示对答案向量进行更新的答案抽取模型,忽略了在使用Bi-LSTM对答案表示向量进行学习时,会出现信息丢失等问题。为此,本文提出了基于Bi-LSTM的答案抽取模型。
在介绍Bi-LSTM神经网络之前,本文先简单介绍LSTM神经网络。LSTM神经网络于1997年由Hochreiter和Schmidhuber提出,其可以学习数据的长期依赖信息,是循环神经网络(Recurrent Neural Networks, RNN)的一种变体。与RNN神经网络不同的是,LSTM神经网络中引入了“门”的概念,使得每个时间t的信息被LSTM神经元选择“记住”或“遗忘”某些信息。且其能够用来解决使用传统RNN神经网络处理长时间信息所产生的梯度消失和梯度爆炸等问题[75,76]。随着深度学习的兴起,LSTM神经网络已被广泛应用到语音建模[77]、机器翻译[78]、问答系统[60]等领域。
........................
结论
问答系统是一个开放领域的综合研究课题,同时也是当前自然语言处理领域中一个热门的研究点。允许用户以自然语言的方式进行提问是其一特点,该系统可以从各种信息资源中自动查找答案,然后返回给用户一个准确的答案。本课题从问题和答案抽取两个方面对问答系统展开研究。
........................
结论
问答系统是一个开放领域的综合研究课题,同时也是当前自然语言处理领域中一个热门的研究点。允许用户以自然语言的方式进行提问是其一特点,该系统可以从各种信息资源中自动查找答案,然后返回给用户一个准确的答案。本课题从问题和答案抽取两个方面对问答系统展开研究。
首先在问答系统中,对于问题分析是必不可少的一个关键环节,由于当前的深度学习技术有一些弊端,比如模型中参数众多,训练复杂,输出结果难以解释等,因而本文采用传统方法对用户输入的问题进行分析。考虑到现实生活中各种问答系统对用户输入文本字数的限制,本文从长文本和短文本两个角度利用主题模型分别对用户问题进行分析,然后又考虑到现实生活中的海量数据,本文结合在线算法提出了基于Extended LDA和IBTM的动态主题模型—CTM主题模型。
其次,本文从CTM主题模型的实验结果中观察到,仅依靠使用Zhang等人所提出的利用名词和动词作为关键词是无法将用户输入的问题文本中的主题焦点提取出来,而主题焦点却是获取答案的重要信息。为了进一步能准确获取用户所输入的问题中的主题焦点,本文分别采用基于词性特征组合的方法和基于同义词词库的方法对问题中获取的关键词进行进一步扩充,从而形成对问题的扩展。
其次,本文从CTM主题模型的实验结果中观察到,仅依靠使用Zhang等人所提出的利用名词和动词作为关键词是无法将用户输入的问题文本中的主题焦点提取出来,而主题焦点却是获取答案的重要信息。为了进一步能准确获取用户所输入的问题中的主题焦点,本文分别采用基于词性特征组合的方法和基于同义词词库的方法对问题中获取的关键词进行进一步扩充,从而形成对问题的扩展。
最后,本文以中文问题公开数据集百度QA进行实验,实验结果证明本文所提出的基于Extended LDA和IBTM的动态主题模型-CTM主题模型相对于其他动态主题模型确实能很好地挖掘主题并进行文本分类。另外,本文对第4章所提出的对关键字扩展的方法与该动态主题模型进行结合后发现,基于词性特征组合的关键字扩展方法以及基于同义词词库扩展关键字的方法确实能将用户中的主题焦点准确提取并进行扩展。
参考文献(略)
参考文献(略)