本文是一篇计算机论文,本文聚焦基于在线社交网络的信息传播预测问题,从微观和宏观两个层面研究了用于结点感染预测和信息级联标签预测的模型和算法。
第1章 绪论
1.1 选题背景及意义
信息传播一般指信息从一个实体通过某种媒介传递到另一个或者多个实体的过程,可以发生于个人之间或者组织之间甚至整个社会范围内,在人类生产和生活中扮演着重要角色。从个体层面来看,信息传播是人类认识世界的基石,通过接收、处理信息,个体能够获取知识、学习技能、理解环境并做出决策;通过制造、散布信息,个体能够传递观点、表达自我、建立沟通并扩大影响力。从社会层面来看,信息传播不仅通过传递知识概念、习俗规范、信仰和价值观等影响着文化的传承与变迁,而且在解决社会问题以及促进社会发展方面发挥着重要作用。例如,在经济领域,信息传播影响着技术创新、市场竞争和效率提升等诸多方面;在公共卫生领域,信息传播对于预防疾病、普及正确认知以及促进健康行为等至关重要。根据传播媒介的不同,传统的信息传播可以分为两种:基于谈话、电话、信件等方式的私密化传播;基于报纸、书籍、广播、电视等方式的公开化传播。
在Web 2.0时代,移动终端设备的广泛普及与互联网技术的快速发展推动着各式各样互联网应用不断涌现。在线社交网络(Online Social Network, OSN)作为其中的典型代表,已经成为了一种新型的信息传播媒介,在人们获取知识、查看新闻、发布观点、创造内容、分享生活、即时通信等日常活动中扮演着不可或缺的角色。常见的在线社交网络类应用有国内的QQ、微博、微信、抖音、快手、头条、知乎和豆瓣等,国外的WhatsApp、Twitter、Facebook、Reddit、LinkedIn、YouTube和Yelp等。虽然这些在线社交网络应用在用户群体、内容生产、服务类型与商业模式等方面不尽相同,但是它们都为信息传播提供了更加优渥的环境与更加广阔的平台,成为了信息产生与传播的沃土。根据中国互联网信息中心(CNNIC)于2023发布的《第52次中国互联网络发展状况统计报告》,截至2023年6月,中国的网民规模已达10.79亿人,互联网普及率达76.4%。
.....................
1.2 国内外研究现状
1.2.1 信息传播结点预测研究现状
1.2.1.1 基于传播动力学的方法
早期的信息传播结点预测研究工作[53]大部分基于固定的传播动力学模型建模信息传播过程,其中最具代表性的工作是独立级联模型[20(]Independent Cascade Model,ICM)和线性阈值模型[54](Linear Threshold Model,LTM)。
独立级联模型的起源可以追溯到社会网络分析的早期阶段,2001年,Jacob Goldenberg等人[20]在研究市场营销(Marketing)模型时首次给出了规范化定义。独立级联模型的核心假设是:(1)网络中的每个结点在面对一则信息时,可能处于两种状态中的一种,即未激活状态(inactive)和激活(active)状态,未激活状态表示该结点还未和该信息产生交互,激活状态则表示已经产生过交互。需要注意的是,一般认为由未激活状态向激活状态的转变是单向的。(2)网络中的每条边(u,v)都对应着一个传播概率p(u,v),代表了结点u变为激活状态后,影响处于未激活状态的邻接结点v变为激活状态的可能性。(3)对于一个未激活的结点v,在t时刻可能存在多个于t−1时刻被激活的邻接结点同时尝试激活结点v,但是这些不同结点作出的“尝试”是相互“独立”的,这也是独立级联模型的关键所在。特别地,被激活的结点只能尝试一次去激活其处于未激活状态的邻接结点,如果失败就不再尝试。基于以上三点假设,独立级联模型下的动态传播过程可以总结为:给定由初始时刻已经处于激活状态的结点构成的种子集合(seed set),在每个时刻都计算未激活结点可能被种子集合中的邻接结点激活的概率值,根据概率大小选择在该时刻被激活的结点加入种子集合,持续迭代直至没有可激活的结点。
.......................
第2章 基于深度协同嵌入的信息传播结点感染预测模型
2.1 引言
近年来,随着脸书(Facebook)、推特(Twitter)和微博(Weibo)等在线社交网络服务(online social network service)的普及,信息级联(information cascade)逐渐成为在线社交网络中的常见现象,并且吸引了大量研究者的关注[1]。作为一项备受瞩目的研究课题,信息级联预测任务的主要目标是预测未来时刻在线社交网络的用户或者结点被一则信息所“感染”的可能性[6–9]。本文中的“感染”表示用户与信息之间发生的交互行为,例如用户发布、转发或者评论一条推特、图片或者其他形式的信息[13]。
虽然针对信息级联预测任务已经存在不少相关的研究工作[6,11,14–17],但是这些现有工作通常具有以下三个不足之处中的一个或者多个:
首先,现有的部分工作往往假设信息在网络中的传播过程遵循一个预先设定的动力学模型,如独立级联模型[20(]Independent Cascade model,IC)、线性阈值模型[34,54(]Linear Threshold model, LT)以及易感-感染模型[21](Susceptible-Infected model,SI)。然而在现实情况中,信息传播的过程是非常复杂的,人们很少能够准确地获知信息传播的潜在动力学机制[22],也很难使用单一的动力学模型适配各种不同的传播网络。
其次,某些现有工作经常假设信息在结点之间的历史传播路径是能够准确观测到的。但是事实上在很多现实场景中,人们只能观测到某些结点在某些时刻发生了感染行为,却很少能够明确获知究竟是什么因素影响了这些感染行为的发生[15]。例如在病毒式营销活动中,系统后台可以追踪到一个用户于某时刻购买了一件商品,但是系统或者营销者并不知道是什么因素影响了此次购买行为。此外,某些工作甚至直接假设信息沿着网络中的静态链接进行传播。这种假设是有失偏颇的,例如在微博网络中,用户不仅可以转发评论它关注的用户的微博,也可以转发评论它从未关注过的用户的微博,即感染行为的发生不一定依赖静态链接。
最后,现有工作常常局限于预测结点在未来某个时间被感染的概率,而忽略了预测结点之间发生感染的顺序,即一个结点的感染是会早于还是晚于网络中的其他结点。预测结点的感染顺序在很多场景中都是比较重要的,例如在舆论监测场景中,预先知道谁是下一个被感染的结点对于阻止谣言的扩散是非常有帮助的[18,19]。
.......................
2.2 基本概念与问题定义
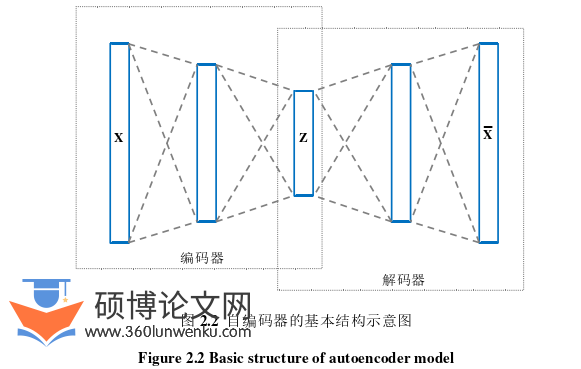
自编码器(Autoencoder)是一种经典的无监督神经网络模型,在图像处理、语音识别、推荐系统、自然语言处理等诸多场景被广泛应用,主要用于数据降维、特征提取和数据重建等任务。一般来看,自编码器的基本结构包含编码器(Encoder)和解码器(Decoder)两部分,如图2.2所示。相应地,自编码器的作用流程也分为两个阶段:编码阶段,通过编码器将输入数据映射到低维特征空间得到低维特征向量;解码阶段,通过解码器将低维特征向量映射回到原始数据空间中。自编码器的优化目标是最小化输入数据和重建数据之间的差异,以学习到更加有效的特征表示。
计算机论文怎么写
本章以自编码器作为模型基础组件,为网络中的每个信息级联分配了对应的自编码器,捕捉结点在信息级联中的各种特征。针对信息级联的结点感染预测任务面临的两大研究挑战,本章进行了巧妙提出了级联间协同和结点间协同模块,将这些自编码器组件有机结合,实现了具备良好预测性能的DCE模型。具体模型设计细节将于2.4节介绍。
............................
第3章 基于超图神经网络的信息级联标签预测模型 ............... 35
3.1 引言 ................................ 35
3.2 基本概念与问题定义 ................... 38
第4章 结论与展望 ............................. 55
4.1 全文总结 ....................................... 55
4.2 研究展望 ......................................... 55
第3章 基于超图神经网络的信息级联标签预测模
3.4 实验
本节将展示在两个公开的在线社交网络信息级联数据集上进行的各项实验。首先,本节对实验采用的数据集、对比方法、评价指标等各项设置细节进行了介绍,然后通过信息级联标签预测实验、模型消融实验、嵌入表示可视化实验、超参数调试实验四项内容充分展现HyNEC模型的有效性。
3.4.1 实验数据集
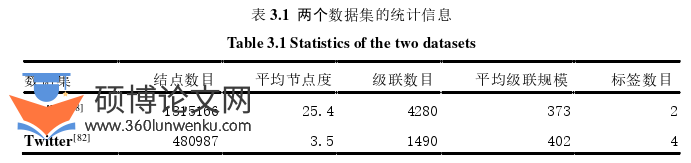
为了评估HyNEC模型在信息级联的标签预测任务中的表现,本章选取了两个从在线社交网络Weibo和Twitter收集的真实数据集进行实验验证:Weibo与Twitter。数据集的主要统计信息如表3.1所示,详细介绍如下:
Weibo数据集[68]:Weibo是一个提供微型博客(micro-blog)服务的社交网站。Weibo数据集中,原始网络中的每个用户对应一个结点,与同一则微博相关的所有带有时间戳的用户转发记录构成了一个信息级联。需要注意的是,用户转发记录中也记载了当前用户实际从哪位用户转发了该微博,用于本章中每个信息级联对应的级联图的构建。信息级联的标签有两种:“Fake News”和“True News”,表明信息级联传播的是否是虚假信息。此外,Weibo数据集还为每个结点都配备了一个配置文件(profile),给出了该结点的某些属性信息如性别、位置、关注者数量等,用于构建结点的初始嵌入表示。
Twitter数据集[82]:Twitter也是一个提供微型博客(micro-blog)服务的在线社交网站。Twitter数据集中,每个结点表示原始网络中的一个用户,每个信息级联表示一系列与同一条推文交互过的用户对应的带时间戳的交互记录。交互记录中也给出了当前用户实际从哪位用户转发了该推文。Twitter数据集中的信息级联标签有四种,即“True”、“False”、“unverified”、“non-rumor”,表示了信息的真实程度。同样的,Twitter数据集中也提供了用户的配置文件,用于构造结点的初始嵌入表示。
计算机论文参考
...........................
第4章 结论与展望
4.1 全文总结
本文聚焦基于在线社交网络的信息传播预测问题,从微观和宏观两个层面研究了用于结点感染预测和信息级联标签预测的模型和算法。本文的主要工作与贡献总结如下。 针对在线社交网络信息传播结点感染预测问题中存在的级联特征建模和级联非线性建模两大研究挑战,本文提出了深度协同嵌入模型DCE。它采用自编码器为基础组件,通过级联间协同模块和结点间协同模块的双重协同作用,实现了对结点的级联上下文和级联亲和度等信息级联特征以及静态链接结构特征的捕捉与融合,将信息级联中的结点协同嵌入至潜在特征空间。DCE模型学习得到的结点嵌入表示,不仅能够用于信息级联的感染可能性预测,也能预测信息级联的感染顺序,并且无须依赖潜在的传播机制和传播路径。实验结果显示,与现有的浅层动力学模型、基于表示学习的方法、基于循环神经网络的方法相比,DCE模型在预测信息级联中结点感染的可能性以及结点感染顺序任务中均展现了良好的预测性能。
针对在线社交网络信息传播级联标签预测问题面临的结点-结点关系建模、结点-级联关系建模与级联-级联关系建模三大研究挑战,本文提出了一种基于超图的神经协同模型HyNEC。区别于传统工作,本章创造性地引入了超图数据结构对在线社交网络中一系列的信息级联同时建模:网络中原有的结点映射为超图中的超结点,每个信息级联则映射为超图中的一条超边。基于超图的建模方式使得结点之间的高阶共现关系以及信息级联之间的特殊协同关系得以被捕捉。本章进一步提出了基于耦合-解耦迭代过程的超图卷积神经网络架构,通过学习信息级联的嵌入表示编码三种关系用于标签预测。实验结果表明,与来自五种类别的十二种先进的对比方法相比,HyNEC模型具备最优的信息级联标签预测性能。
参考文献(略)