本文是一篇计算机论文,本文结合无触发词的事件抽取任务特点,基于现有的文档级事件抽取框架, 出了新的事件抽取模型。
1 绪论
1.1 研究背景与意义
1.1.1 研究背景

计算机论文参考
随着我国金融市场的不断发展与完善,以及人民物质生活水平的 高,参与金融市场投资的居民人数逐年增加,导致民众对金融信息的关注度得到极大的 升。文本是一种常见的非结构化数据。在金融领域,通常使用文本数据进行信息发布,使信息准确无误地传达至市场,本文将这些文本称为金融文本。这些金融文本可能是企业发布的日常经营公告,也可能是券商投行对公司运营信息的分析报告。其特点是信息丰富,包含企业近期的营业状况,为投资交易决策 供最直接的参考依据。充分理解金融文本的信息能够帮助投资者了解公司近况,从而作出正确的投资决策。对于投资者来说,这些信息具有非常重要的实际意义。
中国经济快速发展导致金融文本数量爆发式增长,每天都有大量的企业和投资机构发布金融信息。在2022年,我国A股上市公司共发布约63万篇公告①,平均每天约1700篇。海量的数据信息不但增加了投资者搜集整理信息的时间,还给监管机构对上市公司进行合规检查带来沉重的负担。近年来,深度学习技术的进步和计算机算力的大幅 升,促进了人工智能领域的迅速发展,而信息抽取技术也是其中一个受益的领域。如何借助信息抽取技术对大量的金融文本信息进行快速且准确的处理, 取出文本的关键信息,帮助人们更快地获取信息,更准确地理解信息的含义,成为了当前的研究热点。
...........................
1.2 国内外研究现状
事件抽取是信息抽取任务的研究热点,可以帮助人们快速理解文本信息。在事件抽取技术的发展历程中,研究者使用了许多不同的方法来实现这一目标。主流的方法可以分为3类:基于模式匹配的方法、基于机器学习的方法和基于深度学习的方法。下面将分别介绍这3类方法的国内外研究现状。
1.2.1 基于模式匹配的方法
基于模式匹配的事件抽取方法是一种使用预先定义的模式来 取事件信息的方法。这种方法主要依靠文本的基本句法结构和词汇含义来识别文本中出现的事件信息。首先,需要根据事件的特点定义抽取模式,系统通过这些模式识别文本中特定的关键词或短语结构。随后,根据一定规则对文本进行分析,从而 取出文本中包含的事件信息。抽取效果主要取决于模式的有效性和完备性。根据模式的构建过程不同,这种方法可以分为人工归纳方法和弱监督方法。
人工归纳方法是利用领域专家对事件的理解,直接通过经验构建事件抽取模式的方法。抽取模式的好坏取决于专家对于领域知识和文本特点的理解程度。Kim等(1995)[2]通过语义框架和短语链接构建事件模式,抽取过程中融合了WordNet知识库信息,在特定领域取得了接近人工标注的抽取效果。Wong等(2008)[3]通过构建模式从股票分析师对股票市场的评论中抽取股票观点事件,并将抽取结果应用于市场趋势预测。万齐智等(2021)[4]基于依存句法分析技术设计了一个结合句法和语义依存分析的中文事件抽取框架,抽取结构为(Sub, Pred, Obj)三元组的开放域金融事件,并针对4种常见的缺省情况设计了补全规则,缓解了事件成分缺失问题。
.........................
2 相关理论与技术简介
2.2 词编码技术
文本是人类使用的一种符号集合,但计算机无法直接识别和处理。为了让计算机程序能够识别和处理文本数据,需要使用编码器将词汇映射到向量空间,并使用相同维度的向量表示所有的词汇。学者们做了大量探索工作来 高词汇编码的效果,从简单的独热(one-hot)编码发展到复杂的大规模预训练语言模型,使词汇编码包含更丰富的语义信息,更好地支持了下游任务。
Word2Vec[9]是谷歌公司在2013年 出的一种生成词向量的模型,它通过在数以亿计字符的语料库上使用无监督学习算法训练得到。该模型生成的词向量捕获了词汇的语义和句法关系,对自然语言处理领域产生了深刻的影响。
Word2Vec包含两种不同的模型,分别是CBOW(Continuous Bag-of-Words)模型[35]和Skip-Gram(Continuous Skip-Gram)模型[36]。CBOW模型使用目标词汇的前后词汇信息预测目标词汇出现的概率,而Skip-Gram模型与之相反。Skip-Gram模型使用当前词汇的信息预测前后词汇出现的概率。Word2Vec模型学习了词汇的语义信息,但却无法捕获同一个词汇在不同语境下所表达的不同含义。为了动态地捕获文本的语境信息,研究者们 出了ELMo[37]和GPT[38]模型进行探索。
ELMo模型采用Bi-LSTM模型实时 取词汇的语义特征,并采用加权求和的方式聚合不同层次 取的语义特征,捕获了词汇的上下文语境信息。GPT模型采用12层Transformer Decoder结构进行单向的语义特征学习,即根据前几个词汇预测即将出现的词汇。ELMo和GPT对词汇的上下文语义建模都还不够完全。
018年,谷歌 出名为双向编码器(Bidirectional Encoder Representation from Transformers, BERT)的大规模预训练语言模型[10]。该模型整体结构如图2.1所示,共使用12层Transformer Encoder结构进行双向语义特征学习。BERT还在预训练目标中增加了语句级任务,使模型对文本的语义进行充分建模。
..........................
2.3 深度学习技术
2.3.1 双向长短期记忆网络
长短期记忆网络(Long Short-Term Memory, LSTM)是RNN的一个变种,广泛应用于自然语言和语音等时间序列数据的处理任务。
(1) 长短期记忆网络
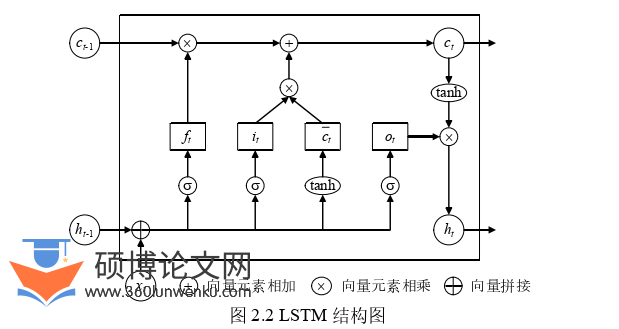
LSTM由Hochreiter等(1997)[39] 出,解决了困扰普通RNN的梯度消失和梯度爆炸问题。LSTM模型的结构如图2.2所示,通过3个门控单元控制节点之间的信息流动。
在LSTM的计算流程中,首先,根据上一节点的输出t1h和当前节点的输入tx分别计算遗忘门tf、输入门ti、输出门to和隐藏状态tc;随后,根据tf和ti的取值控制t1c和tc的权重产生新的记忆值tc;最后,根据to的值,产生输出值th,并将tc和th传递至t1的计算单元中。在计算过程中,输入门ti决定了原始信息的保留情况,遗忘门tf控制着从记忆单元中获取的信息,输出门to影响着最终的输出向量。
(2) 双向长短期记忆网络
LSTM可以按顺序传递消息,将前方的消息传递至后续节点。但根据实践经验,逆向的消息传递对理解特征也具有非常重要的作用。Cross等(2016)[40] 出了Bi-LSTM,通过两个LSTM网络分别从两个方向捕获上下文信息,其整体结构如图2.3所示。
计算机论文怎么写
............................
3 基于依存句法语义增强的文档级金融事件抽取方法研究 ......................... 18
3.1 引言 .................................. 18
3.2 基于依存句法的金融实体语义增强 .................... 19
4 基于实体距离的文档级金融事件抽取方法研究 ............................ 32
4.1 引言 ............................. 32
4.2 实体距离信息的表示建模 ..................... 32
5 总结与展望 .................................... 41
5.1 总结 ...................................... 41
5.2 不足与未来展望 ...........................42
4 基于实体距离的文档级金融事件抽取方法研究
4.1 引言
在有触发词的事件抽取中,事件抽取通常分为4步,分别是触发词的识别和分类、论元的识别和分类。在论元的识别和分类的过程中,主要是根据候选论元与触发词之间的语义信息进行判断。而在无触发词的事件抽取中,由于没有触发词作为一个事件存在的标志信息,只能通过实体之间的语义信息判断哪些实体共同构成了一个事件。因此,候选论元之间的句法语义信息在无触发词的事件抽取中尤为重要。
在Zheng等(2019)[34] 出的Doc2EDAG模型中,通过外部记忆模块存储部分论元的信息,在填充事件记录的过程中通过候选论元与记忆模块的交互来捕获各论元间的语义信息。这种方法虽然能捕获一定的语义信息,但未对实体之间的句法语义进行更多的探索。Lu等(2022)[45]使用结构为(head entity, relation, tail entity)的实体实例元组表征事件,并利用实体在语句中的共现情况预测实体实例元组,探索了句法信息在无触发词事件抽取任务的应用。Xu等(2021)[46]在Doc2EDAG的基础上,利用包含句子和实体两种节点的异构图,构建了基于异构图的跟踪器交互模型(Heterogeneous Graph-based Interaction Model with a Tracker, GIT),使用句子-句子、句子-实体和实体-实体等3种类型的边来增强实体之间的语义交互。这种方法进一步探索了实体之间的句法语义,但只有两个实体同时出现在一个句子时才存在直接连边,对句法语义利用不充分。
在自然语言的表述中,存在关联的事物通常会出现在相近的文本内,以便读者阅读和理解,而距离较远的文本往往在语义上有较大的差别。基于这种句法现象,本章 出计算实体的最短语句距离和最短依存距离,并将其用于文档级事件抽取,捕获更丰富的实体句法语义, 升无触发词的文档级事件抽取效果。
.............................
5 总结与展望
5.1 总结
封闭域事件抽取任务的主要目的是按预定义的事件模板,抽取与特定类型事件相关的信息。事件抽取可以为预测金融走势、辅助司法判决和监控新闻舆情等具体应用 供有效信息,还可以为构建知识图谱、 取文章主题以及文本聚类等任务 供支撑信息。本文结合无触发词的事件抽取任务特点,基于现有的文档级事件抽取框架, 出了新的事件抽取模型。本文的主要工作如下:
(1) 在无触发词的文档级事件抽取任务中,往往面临着缺乏行为语义信息和候选论元语义建模不充分的问题。为了解决这些问题,第3章 出PTPCG-DSSE模型。该模型通过句法依存树寻找实体的核心动词,以获取实体所依赖的行为语义。同时,该模型采用GAT学习依存关系图的结构信息,以增强实体依存句法语义,从而为事件抽取任务 供语义信息更丰富的候选实体嵌入向量。在大规模无触发词的文档级金融事件抽取数据集ChFinAnn上进行实验,该模型获得了80.5%的F1值,相较于基础模型PTPCG 高了1.1个百分点;在5种不同的金融事件类型的F1值中,分别 升了0.4~3.3个百分点。实验结果证明了基于依存句法语义增强的文档级金融事件抽取模型的有效性。
(2) 在无触发词的文档级事件抽取任务中,由于缺少触发词作为事件的核心,需要更准确地建模实体间的句法语义,才能更精确地捕获事件语义信息。为了达到这一目的,第4章 出计算实体的最短语句距离和最短依存距离,并构建了3个使用不同距离嵌入方式的文档级事件抽取模型,分别为PTPCG-ED-division、PTPCG-ED-plus和PTPCG-ED-concat。经过实验分析,PTPCG-ED-concat模型取得了0.814的F1值,相较于PTPCG-DSSE模型 升了0.9个百分点;在多事件文档中,平均F1值 升了1.5个百分点,证明实体距离信息可以为事件抽取 供有效信息。
参考文献(略)