第 1 章 绪论
1.1 研究背景
现如今,随着互联网技术的发展与应用,社会早已进入大数据的时代,海量多变的数据已经成为当代重要的资源,如国内外一些常用的社交平台Facebook、Twitter、百度贴吧、新浪微博、微信等等,其用户的注册和访问数量每天都在以惊人的速度增加。这些社交网络[1-2]是人们进行通讯与交流的重要渠道和方式,用以建立各个用户之间关系网以及沟通分享内容等操作行为,催生出了大量的图结构形式的数据[3-4]。在图的数据规模越来越庞大的同时,图中存储的信息越来越多样化,结构也越来越复杂。如何在海量的图数据中挖掘出有价值的信息,并被最大程度地分析与利用,仍然是当前一个具有挑战性的问题。
图作为计算机科学中一种重要的数据结构,能够抽象地描述数据之间的关联性,以此来表示数据的拓扑结构。几十年来,各种有关图论的问题与处理方法应运而生。基于图的查询处理是最基本也是最核心的问题,包括图的可达性查询[5-11]、子图同构和 Top-k 子图同构查询、最大连通度的 k 边连通分量查询等问题[4]。其中,可达性查询在实际生活中有着广泛的应用。
通信网络是将各个单独的设备通过物理方式连接,实现人与人、人与计算机或者计算机与计算机之间进行信息交换的链路,从而实现资源共享和通信的目的。网络中的各个站点可视作图中的结点,链路即为边。可达性查询可以满足两个站点之间的通讯交流。
在生物信息学领域,图数据库使得生物科学与信息化处理技术完美结合,人们利用图结构来研究复杂的生物数据和生物学问题。蛋白质的相互作用可以用来预测蛋白质的功能,这是目前计算生物学的一项重要任务。单个的蛋白质往往不会独自发生作用,它需要与别的蛋白质对象相互作用,才能发挥调节作用。这种生物体的蛋白质-蛋白质相互作用(PPIs)可以总结为一个图形结构[12-13],其中每个节点表示一个蛋白质,每条边代表一个相互作用,同时,相互作用的影响因子可以简化为图中路径上的权值或标签,对蛋白质的转化有重要作用。可达性查询可以帮助蛋白质的同质识别,促进转化。
.................................
1.2 研究现状
回答可达性查询的两种极端方式:(1)直接在原图上,通过图的广度优先搜索(Breadth first search, BFS)[20]或深度优先搜索(Depth first search, DFS) [21]来判断结点之间的可达性,其花费的时间代价为 O(|E|+|V|);(2)利用传递闭包[22]的方式:将整个图的传递闭包直接进行压缩,然后给图上每一个顶点都分配一个相对应的压缩集合 TC(u),用来记录该顶点的可达性信息。当查询顶点 u 是否可以到达 v 时,只需要查找 u 对应的 TC(u)集合中是否存在顶点 v[3]。这种方法的可达性查询将顶点之间的可达性关系转换为顶点的闭包存储查询,通过花费 O(|V|2)的存储代价来换取 O(1)的查询效率。以上两种方式在大规模图上的扩展性较差,因此难以在数千万个顶点规模的图上应用[23-25]。
文献[26]已经对 2010 年以前的可达性查询方法进行了总结,在划分不同类别的同时也做了系统全面的分析与评价。这些相关算法都是基于小图上实现的,图的顶点数量大约在几千个到几万个。它们把对可达性的查询处理转化为传递闭包的存储计算,通过依靠额外的存储开销来提高查询效率[27]。但是随着数据的急剧增长,图的顶点数量达到几百万甚至上千万以上时,就难以借助这些传统的传递闭包算法去处理。近十年来,为了加快大规模图的可达性查询,不少人已经提出了各种新的算法,通过构建良好的索引结构,达到索引大小、构建索引时间和查询时间三个方面的平衡,为处理大规模的图数据提供了更多的途径与方法。
1.2.1 可达性查询的研究
可达性查询的相关算法研究主要可以分为两类:1)Label-only:Label-only类算法是全覆盖的索引,其主要思想是在图中每一个顶点上都构建覆盖可达信息的索引,当处理查询时,判断给定的查询顶点的索引中是否存在交集,存在即可达,否则不可达[28-29]。经典的算法主要有 TF[30]算法、PLL[28]算法、PathHop[18]算法;2)Label-G:Label-G 类算法是在部分顶点上的索引覆盖。它的主要思想是为部分顶点构建可达信息的索引,以减少遍历原图的时间。当需要处理查询时,如果索引可回答查询,则直接返回结果;当索引不能回答时,则需要在图上进行 BFS 或 DFS 遍历来得到结果。常见的算法主要有 GRAIL[24]算法、FELINE[25]算法、SCARAB[31]算法和 IP+[32]算法。
.......................
第 2 章 相关定义及算法
2.1 权值约束的可达性查询相关定义
本节主要分为图的基本概念以及权值约束的可达性查询问题相关的定义。
2.1.1 图的基本概念
定义 2.1 图:图是常见的数据结构之一,一般用 G (V,E)来表示,其中,G 表示一个图,V 表示为图 G 中顶点的有穷非空集合,E 表示图 G 中边的有限集合,用 E VV表示顶点之间的关系。|V|是图 G 中顶点的数量,|E|是图 G中边的数量[35]。
定义 2.2 无向图: 如果图中任意两个顶点之间的边都是无向的,则称为无向图[36]。可以用无序偶对 (V,V)ij表示,iV 、jV 为无向图的两个顶点。
定义 2.3 加权图:图中的每一条边上都带有一个数字,叫做权,它可以代表距离、时间或者其他意义。如图 2-1,图上每条边都赋有一个权值,故是一个加权图。
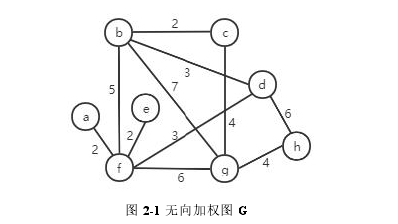
图 2-1 无向加权图 G
2.2 可达性查询的相关算法
本节主要介绍传统可达性查询的相关算法[12, 39-55],包括算法的主要思想、索引构建、查询,并且分析了算法的优缺点。
2.2.1 Label-only
(1)PLL
PLL[28]算法是 Label-Only 类中较为经典的算法。它的主要思路是根据(din(v)+1)×(dout(v)+1)计算公式对图 G 中的顶点进行降序排序,其中 din(v)表示顶点 v 的入度,dout(v)表示顶点 v 的出度。利用 BFS 预先为图上每个顶点分别构建 Lin(v)和 Lout(v)标签,Lin(v)表示顶点 v 可以到达的其他顶点,Lout(v)表示可以到达点 v 的所有顶点。通过两个标签,将两个顶点之间的可达性查询问题转换为判断两个顶点的出度标签和入度标签是否有交集。如果 u、v 两个顶点 有 公 共 顶 点 , 即 满 足 Lout(u)∩Lin(v)≠ ∅ , 则 说 明 u 可 以 到 达 v ; 若Lout(u)∩Lin(v)=∅,则 结点 u 和 v 之间不可达。此类判断方法也可以应用在其他的可达性查询问题上,例如研究 k 步可达的相关问题时,先初步判断是否可达,如果结果为可达,再进一步去计算路径问题。PLL 方法的索引大小为 O(L×|V|),索引时间为 O(L×|V|×(|V|+|E|)),查询时间为 O(L)(L 表示标签元素个数)。
(2)Path Hop
基于 Hop 标签的索引方法通常利用中间顶点来进行可达性编码。它的具体思想是对于图中的每一个顶点 v,为其构建 v 可以到达的所有顶点的标签Lout(v)和可以到达 v 的所有顶点的标签 Lin(v)。然后,给定源点 u 和终点 v,从u 点出发,对 Lout(u)和 Lin(v)做连接操作,通过这两个标签中是否含有公共交点来回答可达性的查询问题。与传递闭包的压缩方法相比,基于 Hop 标签的索引方法一般在查询处理时间上较慢,但是其索引规模较小[3]。
Cohen 等人[36]提出 2-hop 标签算法解决可达性查询的问题。2-hop 标签方法主要是使可达性信息的存储空间最小化,即∑(|Lout(u)| +|Lin(u)|)。最优 2-hop覆盖的索引大小的近似复杂度为 (nm1/2)(其中 n 是顶点个数,m 是边数)。2-hop 标签索引方法需要迭代地从大量的二分图中寻找稠密子图,所以导致花费昂贵的索引构建代价,并且计算时的时间复杂度高达(n3|TC|),其中 TC 表示完整传递闭包的大小。因此,2-hop 标签算法不适用于处理大规模的图 [56-58]。
....................................
第 3 章 基于生成树的索引算法.................................14
3.1 问题分析.............................................14
3.2 优化策略......................................15
第 4 章 基于中间结点的索引优化算法...................................25
4.1 问题分析.........................................25
4.2 优化策略.....................................26
第 5 章 实验结果与分析...................................35
5.1 环境配置...............................................35
5.2 数据集..................................35
第 5 章 实验结果与分析
5.1 环境配置
本文实验所使用的硬件平台是 Intel Core i5,主频是 2.4GHz 的 CPU,RAM为 8.00 GB 内存;操作系统为 Windows 10,编译运行环境为 Visual Studio Code。实验中用于比较的算法有:(1)原图上基于顶点的度构建 2-hop 索引的方法;(2)基于生成树与顶点的度结合构建 2-hop 索引的方法(Degree Index);(3)优化后基于中间结点构建 2-hop 索引的算法(Median Node Index);(4)现有的 Edge_Index 算法。以上所有算法均采用 C++语言实现。
实验中所使用的数据集由 13 个数据集组成,它们基于原数据转换成符合本文要求的无向加权图,这些数据集也被广泛地应用在相关的算法研究[1-60]中,包括:Twitter1、Email-EuAll2、Web-Google2、Soc-LiveJournal2、10cit-patent3、Uniprot22m3、WikiTalk2、Dbpedia4、Go-uniprot3、Govwild 、 Uniprot100m3、Web-uk 和 Uniprot150m3。其中,数据集 Twitter 描述的是 Twitter 上的大规模社交网络;数据集 Email-EuAll 描述的是 Email 网络;数据集 Web-Google 描述的是 Google 的 web 网络;数据集 Soc-LiveJournal 描述的是在线社交网络;数据集10cit-patent 来自于引用网络;数据集 Uniprot22m、Uniprot100m 和 Uniprot150m描述的是基于 Uniprot22m 的 RDF 网络,通过转换变成无向有权图;数据集WikiTalk 描述的维基百科会话网络;数据集 Dbpedia 描述的是知识图谱;数据集 Go-uniprot 描述的是基因上 的专业逻 辑术语构成的联合网络;数 据集Govwild 描述的是一个大规模的 RDF 图;数据集 Web-uk 描述的是用于特定网络垃圾研究的网络数据。这些数据集的顶点与边数量各不相同,且数量级都在20 万以上,并依次呈递增趋势。此外,本文还基于上述原始数据集,保持其顶点个数和边的数目不变,改变它的权值集范围,由原来的|∑|=10 增加至|∑|=100,例如 Twitter_100 是 Twitter 改变权值集之后的数据集,同理,Email-EuAll_100 、 Web-Google_100 、 Soc-LiveJournal_100 、 10cit-patent_100 、Uniprot22m_100、WikiTalk_100、Dbpedia_100、Go-uniprot_100、Govwild_100、Uniprot100m_100、Web-uk_100 和 Uniprot150m_100 分别是基于原数据集改变权值集范围后对应生成的新数据集,将用于下文的实验中,通过改变|∑|参数的权值范围,用来测试当权值范围改变时对本文提出算法的影响。具体信息如表5-1 所示,其中|V|表示无向图中顶点的个数,|E|表示图中边的数目。

表 2-2 先序遍历索引树得到的序列 L
第 6 章 总结与展望
6.1 总结
本文研究的是加权图上的权值约束可达查询处理问题。针对现有方法索引规模大、扩展性差的问题,提出了三种优化的 2-hop 索引方法,以便降低索引规模,增强算法的扩展性。主要研究成果如下:
(1)首先针对权值约束的可达性问题,提出了一种基于加权图的 2-hop 索引构建算法,它按照图上顶点的度进行排序,以确定顶点的处理顺序。该方法的基本思路是将加权图上的权值约束可达性查询问题转换为顶点标签的集合交集操作。但是考虑到其构建 2-hop 索引的时间和空间代价过高,进一步提出基于最小和最大生成树的 2-hop 索引方法。该方法通过构建最小和最大生成树,按照顶点的度从大到小的顺序构建索引。实验结果表明,与现有的算法相比,基于生成树的索引方法构建的索引大小平均减少 2.4 倍,在 uniprot100m 数据集上更是降低了 7.2 倍;与基于原图的方法相比,索引大小与查询时间基本保持不变,而索引构建时间快 23.7 倍。
(2)其次,考虑到顶点的处理顺序会极大影响 2-hop 索引的规模和构建时间,提出优化的 2-hop 索引构建策略。和以上提出的 2-hop 索引方法不同的是,该方法在构建索引的过程中,根据顶点划分子图的变化情况来动态地确定下一个最合适处理的顶点。具体来说,该方法在生成树的基础上,通过找树的中间结点作为 hop 点来构建 2-hop 索引。之后删除该点,可得到若干子树,对每棵子树重复以上操作。实验结果表明,优化后的 2-hop 索引方法比现有的算法平均减少 2.9 倍,甚至在数据集 uniprot100m 上降低了 8.1 倍,回答查询效率相差不大;与上文其他两种方法相比,在索引构建时间、索引空间大小和查询效率上均有较大的改进。
综上所述,本文提出的三种构建 2-hop 索引的方法用于回答权值约束的可达性查询,通过实验表明在索引规模大小、索引创建时间和查询响应时间三个方面上都具有一定的有效性,并且能在有限内存的环境下高效处理大规模数据图。
参考文献(略)