本文是一篇计算机论文,本课题针对交通事故致因因素多样性的问题,从人、车、路、环境四个角度出发,利用改进的关联规则Apriori算法实现多值属性数据挖掘,对交通事故数据进行分析研究。
第1章绪论
1.1研究背景与意义
现如今,道路交通安全成为了全球社会的一项公共难题,尽管世界各地都在积极地采取措施以防止交通事故的出现,但是道路安全的问题依旧形势严峻。据联合国世界卫生组织于2015年公布的文件内容显示,若不采取相应地预防措施,道路安全危害可能成为仅次于心脏病、心脑血管疾病、慢性阻塞性肺部疾病和下呼吸道感染疾病的世界上第五大死亡原因[1]。
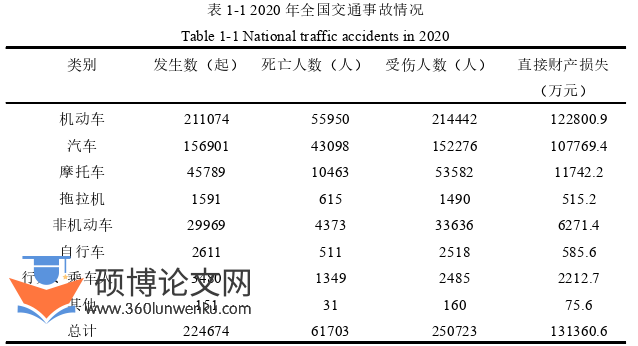
自1985年以来,随着我国制造业和生产业的快速发展,我国机动车的市场需求量逐年上升,尤其是私家汽车,根据国家统计局统计显示,截至2020年,我国私人汽车保有量为242910.19万辆,其中包括载客汽车22333.81万辆;载货汽车1907.28万辆;其他类型汽车50.10万辆,相比较1985年的28.49万辆来说增加了超8877倍。伴随着机动车与非机动车需求量的增加,道路交通事故的发生率也在逐渐上升。据统计,在2020年,我国发生了超24.5万起交通事故,大约有25.1万人受伤,6.2万人死亡,超13.1亿元的财产受到损失。2020年全国发生交通事故的具体情况如表1-1所示。
计算机论文怎么写
.........................
1.2国内外研究现状
1.2.1国外研究现状
国外对道路安全的探索最早起始于19世纪的伦敦,当时伦敦人使用两个煤气灯分别代表了现代道路交通信号灯的红灯和绿灯,装置在伦敦会议大楼前面的马路上,红灯代表停车,而绿灯代表行驶,之后我国学生胡汝鼎建议在两盏信号灯之间添加黄灯作为警示,从而形成了现代所采用的道路交通信号灯的原型[3]。
近年来,道路安全问题受到了各国学者的广泛关注,各国将道路安全问题视为重点及难点。各国学者逐渐将交通事故致因分析从统计分析转变为算法分析。为了减少事故发生的频率,各国学者都致力于研究交通事故背后潜在的规律,以此来抑制交通事故的发生。就道路交通安全而言,国外研究起步早于国内。
Richard等[4]专门了解了停车标志处发生的交通事故,并确定潜在的预防对策。他们详细查阅了1996-2000四年间美国的四个城市共包括1788份关于双向停车标志交叉口的交通事故报告,结果表明违反停车标志的这些碰撞通常是角度碰撞,约占所有车祸的70%。而在不涉及停车违规的事故中,追尾事故最常见,大约占所事故的12%。
Ariana等[5]研究分析了1999年至2000年克罗地亚萨格勒布市的城市道路交通事故风险,目的是减少不断增加的伤害发生率。方法:使用χ2、优势比和95%置信区间进行简单和双变量分析,以确定死亡、严重和轻度损伤三个结果组的风险。
Huanmei Wu等[6]重点是分析交通事故数据库,对1997年至2005年的通用估计系统(GES)碰撞数据库进行了探索,研究了不同场景下的照明环境、天气条件和路面状况等影响因素。
...............................
第2章关联规则挖掘的相关理论
2.1关联规则相关理论
2.1.1关联规则的概念
关联规则是数据挖掘技术中当下研究的热门话题之一,其意义是挖掘事务数据库中各个数据项之间所具有的联系。关联规则挖掘的概念最先是由A.grawal等人根据购物篮应用而提出的,购物篮应用是通过分析顾客购买商品的习惯,设计出有效地营销策略,以此帮助商家获取营销利润。
关联规则挖掘算法的实现主要分为两个阶段:
(1)第一个阶段是需要从原始数据库中找出最大频繁项集。频繁项集是指某一个项集的事务支持度必须达到客户所给出的最小阈值。我们以项集{x,y}为例,遍历数据库,如果数据库中项集{x,y}的事务支持度大于等于最小支持度(Minimum Support)阈值,项集{x,y}则称为频繁项集,频繁k-项集所在的集合通常表示为Lk。然后,由Lk中的频繁项集进行连接操作生成k+1阶候选项集,并对生成的k+1阶候选项集进行提前预剪枝,直到找到最大的频繁项集为止。
(2)第二阶段就是要通过第一阶段获得的最大频繁项集来产生关联规则(Association Rules),并通过用户指定的最小置信度阈值来找到关联性较强的规则。如果某一个规则在满足用户指定的最小事务支持度阈值的前提下也满足用户指定的最小置信度阈值,则这个规则被视为关联性较强的规则。
.........................
2.2关联规则算法选择
Apriori算法和FP-growth算法是关联规则挖掘算法中最常见的两种算法,两者都是基于频繁项集来进行数据挖掘以此来查找项集之间的联系。Apriori算法使用迭代的方式来查找最大频繁项集,再利用获取到的最大频繁项集进行强关联规则挖掘;FP-growth算法则是采用构造频繁模式树的方式来对数据库进行压缩,使得整个算法只需对数据库扫描两次即可,并且也不生成候选项集,相较于Apriori算法该算法的执行效率有了很大的提高。为了更直观的了解两种算法,下面给出了两种算法的优缺点,如表2-1所示:

计算机论文怎么写
本文所用的交通事故数据集具有数据庞大、多维多值、复杂多样等特点。在关联规则算法选择上,考虑到FP-growth算法在生成FP-Tree时,如果数据集中含有很多拥有大项集的记录,就会造成FP-Tree的分支很多,如果FP-Tree的分支很多,构造的条件FP-Tree就会越多,尽管该算法只要扫描两次数据库即可,但是如果FP-Tree的分支过多就会造成算法挖掘最大频繁项集的效率下降;而Apriori算法虽然是产生的候选项集越多扫描数据库的次数也会越多,但是该算法拥有思想简单,代码易实现的特点,因此本课题决定采用Apriori算法用于挖掘交通事故关联规则的建模,并将其进行优化。
.................................
第3章Apriori算法与改进算法...................17
3.1 Apripri算法.....................17
3.1.1 Apripri算法的相关定义与性质............................17
3.1.2 Apripri算法的流程...................................18
第4章多值属性交通事故关联规则挖掘..........................28
4.1数据预处理..................................28
4.1.1数据清理................................28
4.1.2数据准备....................................29
结论......................................37
第4章多值属性交通事故关联规则挖掘
4.1数据预处理
近年来,交管部门积存了大量的交通事故数据,目前为止这些积累的数据并没有得到合理的利用,因此本文将某市交管部门中的历年交通事故数据作为主要数据集,利用改进的关联规则Apriori算法对数据集进行数据挖掘。
4.1.1数据清理
首先要对得到的样本数据集进行筛查,检查数据中是否带有脏数据,脏数据是指不适合直接进行挖掘的交通数据,例如样本数据中含有缺失值、异常值,或者数据集中含有重复的数据等等。其次,为了更加有效的进行数据挖掘,要确定好挖掘的数据属性,删除掉不需要的数据属性以此来降低维度,例如车辆的车牌号、驾驶员目的地、交通事故编号等。除去部分属性在数据中已经具备了之外,个别属性是需要从数据中进一步提炼的,例如根据驾驶员身份证号码获取驾驶员的年龄、根据驾驶员的驾照获得驾驶员的驾龄等。
部分数据存在缺失、异常等问题,需要进行妥善的处理。缺失值,本文将相同属性数据的平均值插入到缺少的数据中。异常值,是指在数据中,数据值有明显的错误,例如驾驶员的年龄超过了100岁,在本文中,异常值被视为缺失值。重复数据,是指在数据集中重复出现的数据,因为在交通事故数据中不可能有重复的数据,所以将重复数据进行删除处理。
计算机论文参考
............................
结论
本课题针对交通事故致因因素多样性的问题,从人、车、路、环境四个角度出发,利用改进的关联规则Apriori算法实现多值属性数据挖掘,对交通事故数据进行分析研究,主要得出如下结论:
(1)提出了一种改进的关联规则Aprioir算法。针对关联规则挖掘Apriori算法在生成最大频繁项集的过程中需要反复扫描数据库并且容易累积大量的候选项集,使得算法执行效率不高的问题,结合已有的优化算法提出了一个新的优化算法。通过对比实验证明,优化的算法解决了需要反复扫描数据库和由自接连操作生成候选项集过多的问题,提高了算法的运行效率。
(2)交通事故数据的挖掘并不是单维的数据挖掘,而是多值属性的数据挖掘。针对算法容易在查找最大频繁项集时产生同一个属性不同值的连接的问题,本课题通过对交通事故数据中的每个属性进行编码并在算法中添加了检验相同属性的方式,解决了算法容易产生同一个属性不同值的连接的问题,提高了算法查找最大频繁项集的效率。
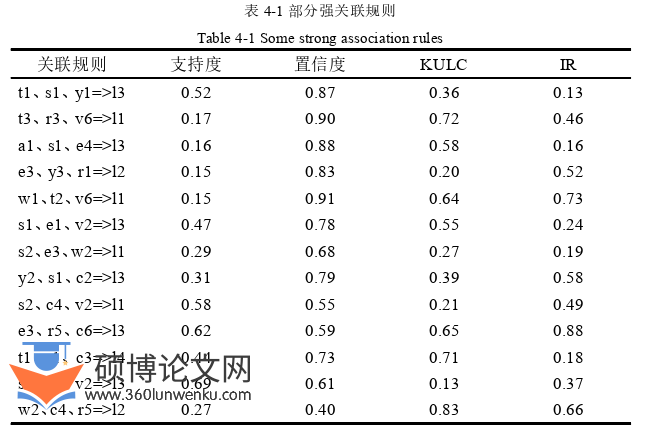
(3)在交通事故致因因素的关联规则挖掘中,可能会存在一些对交通事故致因分析没有意义的关联规则。针对这个问题,本文通过增加主观约束的方法对生成的关联规则进行筛选,为找出有意义的关联规则提供了捷径。
(4)交通事故数据挖掘仅使用支持度和置信度这两个度量挖掘到的规则可能是无效的。针对这个问题,本课题加入了KULC度量与不平衡比(IR)来确定关联规则的可靠性。
参考文献(略)