第一章 绪论
1.1 研究背景与意义
随着人工智能[1]再次兴起,云计算[2]、图像处理[3]、大数据[4]等技术快速的发展,数据量呈现爆炸式增长。Google 和 Facebook 等商业应用能够在一定时间内产生 PB 级(2^50 Byte)甚至 EB 级(2^60 Byte)数据[5],这些技术增长对数据的存储提出了巨大的挑战[6]。
目前,大量数据存储的主要介质仍然是磁盘。随着技术的不断更新迭代,磁盘的存储容量在升级的同时价格也越来越低。鉴于存储海量数据能力的出现,使得成千上万的数据存储得以可能。与此同时,存储能力大幅提升也促使更多数据的产生,相互之间这就形成一个正向反馈。
然而,在具体的程序应用过程中,数据需要不断地从磁盘空间中读取到内存。值得注意的是,在大多数应用中内存访问的指令占总应用指令的 20-40%[7]。这就导致 CPU 与内存之间存在着大量的数据传输。但是,随着计算机处理性能的提升,数据传输带宽制约问题[8]和“内存墙”问题日益明显[9][10]。并且,CPU 的执行速度和内存数据传输速度严重的不匹配[11],导致内存成为计算机整体性能的重要影响因素。然而,传统内存具体存在以下几个问题:
(1)延迟时间久
在冯式体系结构中,内存的处理能力远远不及 CPU。当一些简单的指令操作运行在拥有充足资源的 CPU 时,鉴于 I/O 与 CPU 之间速率相差悬殊,严重的限制了 CPU 的高速性能,降低了计算机运行的效率。当前,CPU 和内存有着各自不同的发展速度,性能都相较于前一代有着显著的提升,但是研究的重点在于提升处理器的频率以及多核并行。这导致两者之间的传输的带宽差距越来越大。二进制使得数据得以数字表示,动态随机存储器(Dynamic RandomAccessMemory,DRAM)[12]是通过电容中电荷的多寡来表示“0”和“1”。由于电荷材质容器存在漏电的弊端,需要周期性的给电容进行刷新防止数据丢失。然而刷新期间不能进行任何的数据读取操作,完成刷新也需要一定的时间,这就给计算机系统增加了额外的时间开销。
.........................
1.2 国内外研究现状
1.2.1 内存行列存储访问研究现状
1956 年磁盘被创造出来,至此之后磁盘一直是存储数据的主要介质,主导着外存。随后,闪存的出现提高了数据的存储容量以及存储速度。伴随着闪存的技术不断的创新和工艺愈发的成熟,支持和使用闪存的设备不断的增加,并且在数据中心下得到有效的使用。由标准性能评估组织(Standard PerformanceEvaluation Corporation,SPEC)的报告结果显示[27],运用在数据中心的闪存设备在 2020 年比例达到了惊人的 47%[28]。大量的数据存储使用闪存,从而提高实现数据的海量存储和高速率的访问。2018 年,Intel 公司创新技术固态硬盘(Solid State Drive,SSD)不仅提高了数据的读写速度,而且增大存储容量的同时降低了生产成本。
然而,尽管固态硬盘的速度得到了有效的提升,在外存的存储空间中给提供了大量的存储能力,但是在应用运行过程中,频繁的数据交换导致数据在移动的过程中,处理单元的大量的是时钟周期都是空转的,不仅浪费了时间还消耗了资源。从外存调用数据应用 I/O 操作,低速度的传输成为短板。因此,内存计算[29]从而破土而出,内存的大容量需求就得以提出,宗旨在于内存能够尽可能多的存储有效数据,减少由外存数据移动带来的 I/O 开销。
随着晶体管的堆放数量越来越多,存储的单元间隙也越来越小,存储的密度也越来大,内存的容量也随之水涨船高。内存的性能的提升使得内存计算更加备受关注,例如淘宝每年的双十一的抢购活动[30]、5G 的直播实时数据新应用、新能源汽车的自动驾驶等应用场景,不仅需要大量的数据传输而且还需要对数据的快速处理分析能力有着较高的要求,这是外存所不能够实现的。内存的大容量存储和高速的传输以及高效与计算单元的交互,使得它满足该需求的应用场景。然而,DRAM 构建的内存存在着延迟久、能耗高、存储空间小、性能不稳定的缺点,并且 DRAM 的在内存的设计中,都是行的方式进行数据的存储访问,特定场景下该内存的访问模式不能有效地满足应用的需求。
............................
第二章 相关知识
2.1 内存的行存储结构
2.1.1 DRAM 存储
在 DRAM 的存储结构设计中,如图 2.1 所示存储单元是一个 1T1C 结构[56],其中 T 代表晶体管,C 代表电容器,通过电容中电荷量区分不同的状态。例如控制晶体管T打开导通字线电荷从电容器流出经过感知放大器(Sense Amplifier,SA)来进行判断,若是电容器当为状态 1 电容器电荷不是满的状态下则判断为状态 2,这样通过两种不同的状态并结合二进制 0 和 1 来表示存放的数据。

图 2.1 1T1C 结构示意图
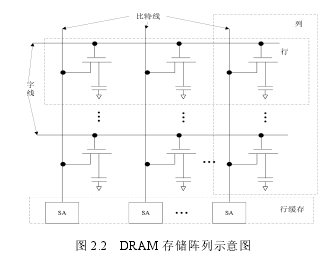
图 2.2 DRAM 存储阵列示意图
2.2 内存的双端存储结构
2.2.1 DRAM 双端存储
DRAM 通过晶体管来控制存储单元中数据的访问情况。然而,想要实现列向的存储就需要在已有的基础结构上添加一个用于控制列向访问的晶体管。2T1C 结构如图 2.5 所示,行晶体管控制行向的访问,列晶体管控制列向的访问,两者获取的数据都是来自于共用电容器。这样存储结构可以从两个不同的方向进行存储访问,最后构成双端存储单元。
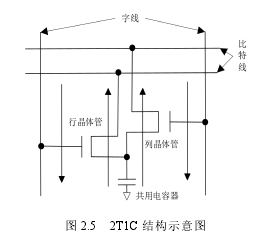
图 2.5 2T1C 结构示意图
第三章 行列访问计算模型......................19
3.1 引言................................19
3.2 计算模型..............................20
第四章 SQL 语句的判别算法...................................32
4.1 引言..............................32
4.2 算法设计............................34
第五章 模糊搜索应用...................................41
5.1 引言...................................41
5.2 底层实现原理.............................41
第五章 模糊搜索应用
5.1 引言
当使用关系数据库存储数据时,存在某些较长字段存储的内容需要进行模糊查询的情况。在该情况下,数据需要进行全局的扫描,内容的逐一匹配。然而当数据量比较大的时候,全局扫描是非常影响查询性能的。以关系型数据库 Mysql为例,使用 like 关键字进行模糊查询。例如查询之前爬取商品表中“华为手机”的信息,那么在 Mysql 中使用 like 关键字构建的 SQL 语句为 select * from skuwhere name like %华为手机%。然而查询到的数据结果中,只有 51 条是与“华为手机”相关的数据,但是查询操作却需要对近 100 万条数据进行扫描,一一匹配,这无疑是非常耗时的。
然而,类似于百度,google 等搜索应用数据库中数据量都是比较庞大的,使用全局扫描肯定是不能够满足查询性能的。由此,通过文档或者记录构建关键字和记录的索引表,可以有效地避免全局扫描的问题。Lucene[69]是 DougCutting 开发的全文检索引擎,核心的实现方式是创建倒排索引表,通过查询倒排索引表中关键字所对应的记录,将相关的数据进行查询得到从而不用查询表中全部的数据。其次是实现准确的分词算法,由于不同的分词算法得到的分词结果不同,因此需要构建合适的分词算法。
另外,Elasticsearch 是最受欢迎的企业搜索引擎,它是底层基于 Lucene 的一个分布式、高扩展、高实时、基于 RESTful web 接口的全文搜索引擎[70]。因此,ElasticSearch 对存储的数据可以进行高效地全局检索。尤其是在数据量比较大的情况下,不用考虑数据与数据之间的关联性,只需要考虑数据是否满足一定的匹配条件,满足检索要求即可。
.........................
第六章 总结与展望
6.1 总结
本文针对数据的存储访问进行研究。在计算机的发展趋势下,计算机的内存的研究得到了极大的关注,内存的存储访问应用能够有效降低计算机体系的存储层次。数据不用频繁与磁盘交互,直接通过内存来进行操作,提高了数据的获取效率。此外,内存不同的访问方式针对不同的应用场景有着不同的性能,在数据密集的应用场景下,列向的内存访问有着巨大的性能优势。本文就内存列向的存储访问进行重点研究,具体内容如下:
1 、针对不同的内存访问方式,分析了内存的行向与列向的差异,以及如何实现列向内存的物理组成结构。
2、设计了不同数据访问计算模型。通过不同的访问方式,得到不同的计算模型。并且考虑了行列两种方式在获取所有数据、部分数据(少量数据和大量数据)的情况。此外,发现了列向访问与行向访问的比值与表中字段的数量成正比关系,同时和列向访问宽度成反比关系。最后,通过实验数据表明,混合模式是最好的访问方式。但是,在行列混合访问的模式下当满足条件的记录数远小于总记录数的时候,混合模式就成了类似列的模式;当满足条件的记录数接近总记录数的时候,混合模式就成了类似行的模式。
3、对应内存的行列访问模式的物理结构和数据库行列不同的逻辑存储结构。在数据库中列向的存储结构更加适合 OLAP 应用,行向存储结构更加适合OLTP 应用。所以结合内存的行列访问模式和数据库的行列应用,能获得更好的性能,因此,设计了 SQL 语句的行列判别算法。通过划分不同行列关键字,筛选 SQL 语句与关键字的匹配程度来进行判断应用类型,从而提前判别数据的应用类型。最后根据实验结果表明,判别算法能够有效减少数据的访问量,缩短数据的平均访问时间。
4、针对数据的模糊查询、全局扫描耗时时间长的问题,分析了全局扫描和数据存储的方式对数据的访问的不同影响,设计了基于 ElasticSearch 引擎的模糊搜索应用。基于爬取京东商城的数据,对比分析了数据在 Mysql 和 ElasticSearch中所占的数据空间以及查询的记录条数。实验证明,ElasticSearch 比 Mysql 更加适合列向数据存储的模糊查询应用。
参考文献(略)