第一章 绪论
1.1研究的背景和意义
随着我国经济地飞速发展,小微企业得到了快速发展。据统计,截至 2018 年末,全国全口径小微企业贷款余额 33.49 万亿元,占各项贷款余额的 23.81%。其中,普惠型小微企业贷款较去年初增长 21.79%,较各项贷款增速高 9.2 个百分点[1]。小微企业法人贷款授信 237 万户,增长 30.9%;普惠小微主体授信 1793 万户,增长 35.2%[2]。贷款业务激增的同时,借款主体也出现大规模的违约风险。小微企业作为我国市场经济的重要主体,发挥了不可替代的作用。然而,小微企业的信贷融资约束却成为制约其进一步发展的主要障碍[63]。究其原因,主要因为银行对企业信用等级有严格要求。通过文献梳理和实证研究,发现小微企业信用评估主要面临的挑战可归结为如下三个方面:
(1)贷款用户数据的弱可用问题普遍存在,即数据的真实性无法保证,数据存在一定程度地缺失;
(2)缺乏面向用户信用等级的科学评判分级体系,导致评判结果缺少客观性;
(3)现有的风险预测模型不能较好地将定性信用指标加以利用,无法提升预测结果的准确性。
小微企业对行业原始数据的存储都是采用传统的数据仓库存储,特别是有着大量原始数据的行业,如金融业和教育业。数据规模庞大,已非目前的统计数据处理技术能够实现[64]。因此,如果没有有效的用户信用数据作为基础,就不能准确地对用户信用等级进行评定,从而难以开展信贷业务。
........................
1.2国内外研究现状
目前银行和金融机构采用信用评分表示借款人的信用度,并基于信用评分计算用户违约风险。传统信用评分主要依赖完整的实时有效的财务报表数据。如果采集的用户数据存在弱可用现象,且缺乏对弱可用数据进行去除噪声数据和数据缺失的处理操作,信用评分系统将会得到不精确的信用评分。
1.2.1 弱可用数据分析研究现状
对数据可用性地研究,普遍认为可以从数据的一致性、完整性、精确性、时效性和实体同一性这五个方面进行考察[7]。数据的可用性具备以下性质:数据系统中的各数据信息之间没有冲突和矛盾;包含的数据信息完全满足对各种查询和各种计算的支持,以及其他各项数据操作的需求;每个数据信息都能够对现实事物进行准确描述;并且和现实中的情形始终保持一致,在不同需求场景下都不陈旧过时;每个数据实体在不同的数据源中的描述统一。同时符合以上五个基本性质的数据集合满足可用性。当然,对于一些特殊行业的数据,除了要满足以上五个基本的性质之外,在处理时,还需要满足行业数据本身的特点。比如金融数据,还具有自身的一些特性:广泛性、综合性、可靠性、连续性。由于企业信用评级的数据,包含金融数据特性,因此对这部分数据也需要进行特殊的处理,它的输入审核更严格、存储容量更大、网络传输更广泛、数据维护更频繁[67]。
弱可用数据就是在以上的某一方面或某几方面存在不足,对现实中数据的研究表明,数据普遍存在数据集合不完整和数据精度丢失问题。造成这些问题的主要原因就是数据缺失,目前已经有很多专家以及学者对此进行了深层次地研究[8-12]。对于缺失的数据来说,应针对数据缺失的机制和模式制定有效的数据处理方法。
..........................
第二章 相关背景知识介绍
2.1数据插补
数据插补通常基于统计原理或者机器学习方法,使用特定值对缺失值进行插值以获得完整的数据集[17]。目前在数据处理中几种常用插补方法如下:
(1)人工插补
主要依靠人工根据过去的经验对数据缺失值进行手动插补。数据分析人员在数据处理的早期阶段所做的工作依赖于自己对该类数据的熟悉度和经验来插补数据,因此人工插补方法通常受知识结构差异影响较大,主观性较强,当数据规模增大并且缺失值逐渐增多时,此方法耗时久,人工成本高。
(2)特殊值插补
该方法会对数据缺失值插入一个约定的特殊值,该特殊值不同于任何其他特征值,并且与其他特征值没有任何关联。如果将缺失的数据简单的标记为“null”,则创建出的新数据集可能会有严重的数据倾斜,并不能体现特殊值的优势。
(3)均值插补
可以将数据集中的特征值分为连续特征值和不连续特征值,均值插补就是根据不同的特征值分别计算。如果缺失值是连续的,则根据特征值的平均值对缺失数据进行插补;如果缺失值是不连续的,则根据统计中的众数原理,将使用特征值中最频繁的值(即出现次数最多的值)来插补缺失的数据[36]。条件均值填充方法使用相同的原理,缺失数据的插补值仍是特征值的均值,不同之处在于不是对整个数据集中对象应用此方法,而是针对具有相同决策特征值的对象。缺失值无论是连续的还是不连续的,其原理都是使用出现概率最大的数据值对缺失数据进行插补,不同的地方在于不同类型的数据,使用的插补方法实现细节不同。
.................................
2.2多任务学习
2.2.1 多任务学习原理
多任务学习就是将多个相关的任务联合训练来增强模型表示和泛化能力的一种方法,其目标是利用多个学习任务中所包含的有用信息来帮助每个任务学习得到更为准确的学习器。任务的相似性是通过限制不同的任务功能在某个距离度量中彼此接近来捕获得到[37]。多任务学习本质上是一种归纳迁移机制,主要目标是利用隐藏在多个相关目标任务的训练信号中的特定领域信息来提高泛化能力[38],并降低模型过度拟合的风险,多任务学习通过提取共享特征表示并行训练多个任务来达成这一目标。归纳迁移[39]是一种将解决问题的知识应用到相关问题的方法,可以提高学习效率。假设所有的目标任务(或其中一部分目标任务)是相关的,在此基础上,与传统的单任务学习相比,发现联合学习多个任务能比单独学习它们得到更好的性能[40]。
目前多任务学习大都通过参数共享来实现,常用的方法分为参数硬共享、参数软共享以及参数分层共享。参数硬共享是当前应用最广泛的共享机制,它将多个任务的属性嵌入到同一个语义空间中,并为每个任务使用特定提取层表示目标任务。硬共享实现非常简单,且能够大大降低过度拟合的风险,适合处理具有较强相关性的任务,但是在处理具有弱相关性的任务时往往表现不佳。参数软共享会为每个目标任务都建立一个模型,并且每个目标任务的模型都可以访问其他目标任务对应模型中的信息。软共享具有很强的灵活性,并且不需要为任务相关性做任何假设,但是每个任务都需要分配一个模型,常常需要增加很多参数。参数分层共享是在模型的低层做较简单的任务,在高层做较困难的任务。分层共享比硬共享要更加灵活,同时又比软共享需要更少的参数。图 2.1 和 2.2 展现了多任务学习与传统的单任务学习的不同之处。本文构建了基于共享矩阵的多任务分类预测模型,通过任务之间的信息共享,实现任务分类。
图 2.1 单任务学习
第三章 面向弱可用数据的多任务用户基本信用评级........................... 19
3.1客户属性缺失数据处理................................... 19
3.1.1 缺失值常用处理方法 .......................... 19
3.1.2 混合插补法................................. 21
第四章 基于模糊 Logistic 回归的贷款风险预测................................ 34
4.1问题分析.................................. 34
4.2信用数据模糊化............................... 34
第五章 小微贷原型系统实现和性能分析.................................... 44
5.1实验数据介绍....................... 44
5.2系统综述........................ 45
第五章 小微贷原型系统实现和性能分析
5.1实验数据介绍
该数据集包含 2015 年 1 月 1 日至 2017 年 1 月 27 日期间拍拍贷 292540 条小微企业的信用数据。下图 5.1 绘制了 2015 年到 2017 年每个季度小微贷用户数据分布图。
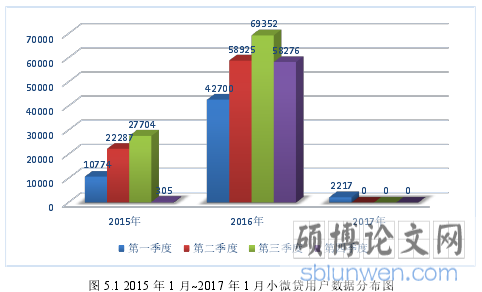
图 5.1 2015 年 1 月~2017 年 1 月小微贷用户数据分布图
第六章 总结与展望
6.1全文总结
在小微贷信用评估技术中,现有的信用等级评估方法仅仅考虑用户信用好或不好,没有详细划分用户的信用等级,信用违约风险地预测也没有充分利用定性信用指标。本文主要利用用户弱可用数据建立信用评级模型计算用户信用等级,并利用定量和定性分析预测用户贷款风险,从而完成面向弱可用数据的小微贷原型系统。
本文以拍拍贷信用数据为基础,设计了基于弱可用数据的多任务用户信用评级算法和基于模糊 Logistic 回归的用户信用风险预测算法。基于弱可用数据的多任务用户信用评级算法的重点在于,需要对信用数据缺失问题进行处理,利用属性的不同缺失率采用不同的方法对缺失数据进行插补。对处理后的用户信用数据采用基于共享矩阵的多任务学习算法,并基于该算法构建信用等级评估模型。该方法有效地解决了标签缺失的问题,提高了用户信用等级预测的准确性,同时也提高了模型的计算能力。
在提出的基于模糊 Logistic 回归的风险预测算法中,通过李克特量表将定性信用指标进行量化,即对信用指标给予一组语言评价,再由相应的评价得到对应的得分;使用三角模糊数对用户信用指标和信用等级结果进行模糊化处理;将经过处理后的信用数据构建基于模糊Logistic 回归方法的用户违约风险预测模型,最终实现对用户的贷款行为进行风险预测。
参考文献(略)