第一章 绪论
1.1研究背景及意义
新兴技术其实已经颠覆了人们的传统生活形式,特别是在购物领域变化特点显著,最早的集市到随后的大型商店、大型超市,更进一步演变成现在巨大规模的电子商务,商品数量也从几百种迅速增加到了万种以上,而现在更多达几亿种,因为传统的购物环境发了巨变,一般的人们不会有足够的精力和时间再在传统购物中货比三家。早在上个世纪,互联网技术就迅速在全世界得到发展,而个人电脑、手机这些终端通信设备的大量普及更是彻底变革了人们传统的处理和收集大量信息的形式,不管你位于何处,只要有网络并且随身拥有这些互联网的终端设备,就可以在世界人民共享的网络中找到大量有价值的自己感兴趣的资源。
中国互联网络信息中心发布的第 44 期报告中指出移动互联网用户数量为 8.54 亿[1],进行网购的用户数量是 6.39 亿,占比超过%75。上述的统计指出,人们花费在网上的时间越来越长,在网络上产生的活动越来越多。根据国际金融数据中心(IDC)的统计,全球的数据规模到2025 年预计会达到 120ZB,中国数据量会增到 15ZB[2]。网民的规模数据如下图 1.1 所示:
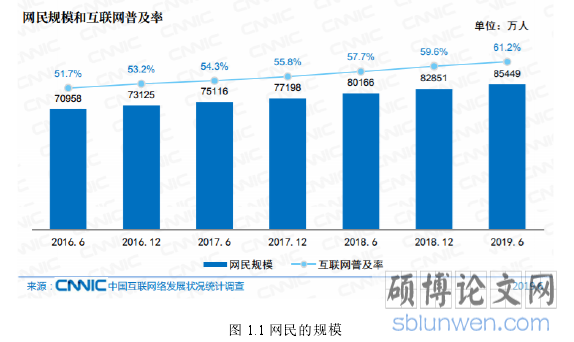
图 1.1 网民的规模
1.2本文的组织结构
本文章节安排:
第一章介绍了本课题的研究背景及意义,然后对本课题文本组织进行了说明。
第二章是相关技术研究,主要对推荐系统中的基础技术以及个性化推荐算法的国内外研究现状做了简单阐述, 通过分析这些技术的优势与不足,找到目前技术所存在的问题,为后续章节做铺垫。本章节还对推荐算法的常用测评指标进行了阐述,后续本文提出的两种推荐算法的实验环节都用到了这些指标对推荐结果进行测评。
第三章提出了一种基于标签权值的改进推荐算法,构造用户-商品-标签矩阵,对标签进行量化,构建新的用户喜好模型,引入标签权值的概念,引入TF IDF算法计算不同用户的标签权重,根据标签权重建立新的相似度计算方法。并且与其他算法进行实验对比,最终得出本章提出的算法的推荐结果更准确。
第四章针对用户评分矩阵中的矩阵分解算法进行研究,提出一种基于社交好友关系的奇异值分解模型。将 Fu nk-SVD算法与用户的社交信息相结合,引入好友的喜好信息结合用户自身的喜好信息优化 Fu nk-SVD模型,用随机梯度下降法分解矩阵,最后进行仿真实验。实验结果表明,本章节提出的一种社交好友关系的奇异值分解模型一方面能够在一定程度上改善数据稀疏性问题,同时相比传统的SVD算法推荐的精度有所提高。
第五章设计了一种电商平台个性化推荐系统,为用户提供立体化,全方位的推荐。主要包括对系统的环境配置,推荐系统的架构与处理流程,以及原型系统的功能的设计与实现,给出了相应的技术架构图和产品推荐流程图,此原型系统证明了本文提出的推荐算法的实用性和可行性。
第六章总结了本文的研究内容,并分析了其中的不足,展望了将来能改进的研究方向。
......................
第二章 相关技术研究
2.1推荐系统研究
2.1.1 基于内容的推荐方法
基于内容的推荐技术是依据商品内容的属性,找到商品的内在联系,通过抽取商品的特征值计算相似度。然后根据用户过去的行为记录,推荐类似的商品给用户。比如一个商品,有用户评论、热卖、商品风格、用户标签等等,都可以算是商品特征。我们可以从这些标签中提取出商品的特征向量。
以内容为核心的推荐算法(Content basedRecommendations )是以相似度来衡量物品和用户行为数据的,将最能吸引用户兴趣的物品集呈现给用户[19]。系统分析用户购买过、浏览过的产品的属性[20],再为其推荐与其有最高相似度的产品。
下图 2.1 是该推荐系统具体案例。首先对数据进行建模,之后通过电影的属性值求解电影之间的相似度,因为电影 A、C 的标签都是“爱情、浪漫”,则认为 A、C 相似[21];最后生成推荐结果,用户 A 喜爱电影 A,因此推荐电影 C 给用户 A。
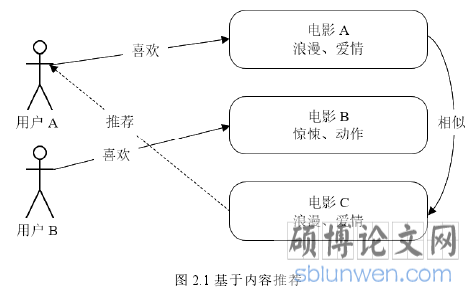
图 2.1 基于内容推荐
2.2国内外研究现状
Xerox Palo Alto 研究机构的 Goldberg 等人在上个世纪九十年代初就提出过个性化推荐思想,借助协作过滤[27]的方法,按照客户之间的注释与评分的相同点搭建出能够进行文章的查找和推荐的 Tapestry 原型系统。该研究内容推出激起了学者和专家对于该方面的探讨。在1997 年 Resnick Varian[28]等经过深入的分析和研究,对于电子商务推荐系统(RecommendationSystem)的内容进行阐述,他们提出:该系统依托电商网站,依据用户的需求,提供个性化的推荐,用户选择最适合自己的商品,并且通过系统指导进行支付,最终完成交易 个性化推荐系统为了更好的适应用户需求、了解用户需要,在建模[29-31]的过程中融入了用户评价矩阵,向量空间模型,机器学习技术等建模方法 在个性化推荐中,将用户进行相似性分类,然后进行个性化推荐的方法是最常使用的方法。该方法又被称之为协同过滤算法 文献[32]创作出一种新的用户模型构建方法,该模型主要借助博客空间中用户的活动推断用户的喜好,给予客户推荐。在实时性研宄方面,文献[33]为了降低分类的所用的时间,提出了奇异值分解的方式,使个性化推荐的效率和准确度更高。文献[34]提出在实际操作过程中只单纯依靠用户显式评价信息无法形成真正适用于用户的推荐,而特征加权与实例选择的方式能解决此问题,通过数据挖掘技术,根据用户的操作找到更隐形的信息,在此基础上形成推荐。
文献[35]借助自适应共振理论对于 web 访问路径做进一步研究,引入 K-means 聚类算法更清楚地筛选出用户经常性的浏览记录 在近几年,数据挖掘技术得到了较快的发展,这大大增强了推荐系统的运行效率,推荐内容也更加符合人们的喜好 为了能够更好地适应人们的喜好形成有效的推荐,许多学者展开了相关方面的研究,并研发出了一些推荐原型系统:在文档中可以选择 ACF 原型系统进行推荐;TYPESTRY 原型系统以及 GroupLens 原型系统适合进行邮件和新闻类的推荐和筛选;MovieLens 原型系统能够生成更准确的电影推荐;Ringo 原型系统在音乐软件中能够发挥作用,诸如此类的原型系统还用很多,它们有着各自的优势,适用不同的软件和系统。通过对文献[36]阅读,得到了基于动态主题模型与矩阵分级的推荐方法,通过DTM 的模型对客户的位置等隐含的信息进行了获取。除此以外,利用数据集的方法对显式信息进行了提取,然后对客户的相似度以及位置相似度进行了计算,然后利用矩阵分解的方式将两个正则化项表示出来。经过一系列的实验,结果显示该推荐方法在旅行上面应用更加合适。
.....................
第三章 一种基于 LW-UB-CF 的推荐算法......................... 16
3.1传统的商品标签算法................................. 16
3.2基于 TF-IDF 标签推荐算法........................... 17
第四章 一种基于 SAL-SVD 的推荐算法.................................... 31
4.1传统的 SVD 分解算法....................... 31
4.2Funk-SVD 与 SVD++算法.............................. 32
第五章 基于电商平台的个性化推荐系统 ........................... 44
5.1系统的环境配置.............................. 44
5.1.1 Spark 框架 ................................ 44
5.1.2 系统环境部署 ................................. 46
第五章 基于电商平台的个性化推荐系统
5.1系统的环境配置
5.1.1 Spark 框架
通过对 Hadoop 和 Spark 框架的深入分析,最终本文的推荐系统使用是 Spark 框架,下面对本推荐系统中使用到的 Spark 框架技术进行简单的介绍。
Spark 的起源是伯克利大学的 AMPLab 在 2009 年做的一个研究性的项目,相比于 Hadoop ,Spark 用于大数据分析上有更大的优势。Spark 的计算速度是 MapReduce 的 100 倍,是基于内存的计算;Spark 使用更便捷,其提供的操作接口有 80 多个,支持并行应用以及多语言(Python ,Java, Scala);Spark 框架有众多强大的支撑组件,比如涵盖机器学习库,支持SQL,图计算以及实时计算等;Spark 框架比 Hadoop 框架更通用,其提供的操作数据集的方式更多,而 Hadoop 的数据操作方式只有 Map 和 Reduce 两种;Spark 框架不仅能独立运行,还兼容 Hadoop,可以在 Hadoop 上运行。目前 Spark 己经发展成了分布式的计算平台,包含许多实用的处理大数据的工具。Spark 的架构图如图 5.1 所示。
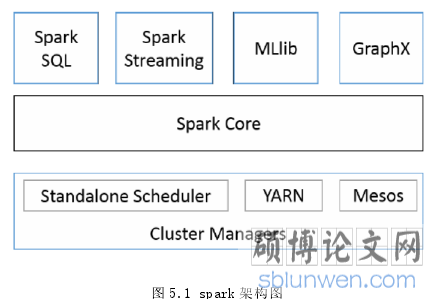
图 5.1 spark 架构图
.........................
第六章 总结与展望
近年来,电子商务的飞快发展、网购环境的改善使得网购用户的数量日益增加,这促使了越来越多的学者纷纷投入到对电商平台的推荐系统研究中,尽管取得了一定的成果,但基于电商平台的用户推荐技术仍有可提高的空间,仍存在一些问题需要解决,如新用户冷启动、数据稀疏性、推荐精度低等问题。在对此领域的相关文献深入研究后,该文完成了以下几项工作:
(1)本文首先对推荐系统的研究意义及国内外目前的研究现状进行分析,并介绍了推荐系统的概念及其应用,接着阐述了常用的推荐算法的算法流程,并分析其优缺点,总结目前技术存在的缺陷,同时还阐述了推荐算法的常用评测指标。
(2)针对上面的文献综述,本文提出一种基于标签权值的改进推荐算法。建立用户-商品-标签矩阵,对标签进行量化,构建新的用户喜好模型,引入标签权重的概念,引入TF IDF算法计算不同用户的标签权重,根据标签权重建立新的相似度计算方法。对相似度计算公式里的调节因子和用户近邻集合 k 的不同取值进行实验分析,最终得到最优推荐结果的最佳取值;并且与其他算法进行实验对比,得出本文提出的算法能得到更好的近邻集合,从而得出本文提出的算法的推荐结果更准确。
(3)针对用户评分矩阵中的矩阵分解算法进行研究,提出一种基于社交好友关系的奇异值分解模型。将 Fu nk-SVD算法与用户的社交信息相结合,引入好友的喜好信息结合用户自身的喜好信息优化 Fu nk-SVD模型,用随机梯度下降法分解矩阵,最后进行仿真实验。由实验结果可知,本文提出的一种社交好友关系的奇异值分解模型一方面能够在一定程度上改善数据稀疏性问题,同时相比传统的SVD算法推荐得精度有所提高。
(4)最后,本文融合 LW-UB-CF 推荐算法与 SAL-SVD 推荐算法构建了一个电商平台的个性化推荐系统。根据系统的功能需求进行了主要功能模块的详细设计,随后采用模块化设计方法,分别介绍了推荐系统各个功能模块的详细功能和实现。 该推荐系统证明了本文提出两种推荐算法的实用性。
参考文献(略)