第1章 绪论
1.1 课题背景
随着创业板的开通和证券交易所对企业上市审批的常态化,中国 A 股的上市企业迅速增加。将要实施的注册制将给公司上市创造了极为便捷的条件。因此,在给投资者提供众多优秀企业获取收益的同时,也给非专业投资者选择合适的上市公司进行投资带来一定的难度。中国证监会《上市公司信息披露管理办法》第十九条规定上市公司应当披露的定期报告包括年度报告、中期报告和季度报告。并且上市公司也会明文规定:凡是对投资作出投资决策有重大影响的信息,均应当披露。许多学者基于发布的财务报告和披露的信息,对上市公司进行绩效评价与分类研究。但用传统的统计或者财务报表的方法,来处理整个行业领域日益海量增加的相关数据时,难以挖掘财务数据或财务属性之间的客观内在联系。随着信息技术的发展,其中的一个很重要的发展热点就是针对证券行业所产生海量信息的数据挖掘方法的研究[1]。目前,基于互联网技术数据挖掘是解决该问题的有效方法。它能够挖掘财务数据之间隐藏的、难以发现的关系,克服传统财务统计报表分析的依赖性和局限性。
在众多财务报告中,季度报告和年度报告尤其有着其重要的参考价值。这些报告的基本组成内容有:公司资产的总负债表、公司现金流、公司利润表等。对于这些财务数据及其附注的分析将有助于分析者对于公司的会计计划、资产组成情况、负债数额、盈利数额以及公司经营者本身的能力都有一个整体而客观的评价。
我国的证券市场 A 股包括上海主板和深圳中小板和创业板,一共有几千家上市公司的股票。每天数千亿交易额,最大交易额超过万亿,这些上市公司产生海量财务数据信息,这些海量的财务数据信息的背后都有着无法估量的巨大价值。但是,要从这些以 TB 为单位的海量财务数据中发现其背后的有用信息,仅仅运用原先的手工记录和简单计算分析方法肯定是不合适的。因此,我们也需要利用新的分析方法,从而从这些数据背后发现其隐含的有用信息。
............................
1.2 研究内容与意义
本论文通过上市公司的财务指标数据,通过数据挖掘的方法,根据财务指标数据进行数据挖掘:(1)通过聚类算法挖掘上市公司财务指标的内在联系与不同,将上市公司进行划分类别,对不同类型的公司针对性研究和分析。本文提出一种基于改进后 K-Means 聚类的上市公司财务报表数据分析和经营状况评价方法。该方法首先基于改进后的 K-Means 逐步二分分裂的方式选择初始聚类中心,而在最开始选择此方法的二分过程初始质心的过程中,可以选择已知的初始极大值的样本点作为二分方法的质心,而后续的带入样本集的模拟结果表明该种处理方式相对于此类算法聚类效果更优,能更好地帮助基金公司决策层和投资者选择哪些上市公司投资作出参考。(2)同时我们通过上市公司的聚类划分结果,我们进行了分类研究,尽可能通过分类算法,将后续的其他上市公司按不同年份的财务指标数据尽可能准确的划分到上述类别划分结果中,所以最后通过基本分类算法随机森林以及神经网络分别验证了上述类别划分数据的分类准确率,并进行了参数的优化,力争分类准确率尽可能的高。
上述的过程利用聚类将不同的上市公司依据他们的财务指标进行划分,聚类算法将依据财务指标数据之间的内在联系,比人工类别划分更具科学性,并且聚类算法可以应用到人工看不到的数据之间的联系。
.............................
第 2 章 研究现状
2.1 相关问题研究现状
针对数据的分析与基于已有数据的新数据挖掘是一个近年来发展十分迅猛的新兴研究方向,这个研究方向最早开始于上世纪 90 年代的中期[5]。数据的分析和挖掘是一种相对比较新的数据处理技术。而数据的分析和挖掘技术最早运用于商业领域中是从一份由美国会计师职业技术协会发布的报告标志开始的,这份报告最早报道了人工智能和专家系统运用于商业数据分析的可行性。首次将利用信息技术和人工智能相关技术处理相关财务数据的思路的引入了财务管理和会计事物的领域。从此以后,世界上发达国家中的财经界和研究界都开始对人工智能和专家系统解决财务数据分析这一课题做出了深入的研究探索。相应的,很多的计算模型和智能系统被开发出来用来解决复杂的财务数据分析问题。
通过计算模型分析财务数据,可以找出原有财务数据中未被表达出的潜在有用信息和隐藏关系,接下来财务分析人员利用自身之前学习到的财务分析理论和价值规则可以对此公司在之后的财务运作和收支情况能有一个合理的预测。欧美发达国家已经出现了诸如 Fidelity Stock Selector 和 LBS Capital Management 等财务数据分析和挖掘系统。前者先后使用了神经网络理论、基因算法、和专家系统的结合来帮不同的理财人士管理超过 6 亿美金的证券账户[7]。后者则是一些先进的机器学习算法进行投资分析以供不同的投资人士进行参考[8]。财务数据的分析和挖掘技术已经成为了证券市场中一种新兴且行之有效的投资决策手段。这些年来,有很多的财务数据研究者也把财务数据的分析和挖掘技术尝试运用于股票证券市场[9],提出了很多性质有效的计算模型和专家系统来解决数据的分析和预测问题[10],甚至可以解决很多股票走势预测问题[11]。
.........................
2.2 财务指标数据基础
随着近年来在财务数据分析领域中的计算模型和信息技术的广泛运用,研究者针对不同公司的财务数据的研究过程中建立了诸多存储不同公司财务数据指标相关信息的数据库,下文中介绍了几个在分析财务指标数据过程中所广泛被使用的数据库供大家查询和参考。同时为了方便大家能及时查询相关数据库中的信息,表 2.1中整理了在本节中介绍的这几个经典数据库的名称和对应的访问网站。

Wind数据库中文也称万得数据库[23],是由wind信息技术有限公司开发的,wind公司是一家中国大陆范围中领先的金融财经数据分析和软件服务的公司,wind 总部位于中国上海的陆家嘴。Wind 数据库主要服务于国内市场,它所收集的财经指标数据主要包括了中国证券市场上的绝大多数来源于基金管理上市公司、证券上市公司、银行投资上市公司和保险上市公司等不同金融领域上市公司的财经数据。除了在大陆范围内,Wind 也是被中国证监会批准的少数几家合格的可以和境外投资机构合作(QFII)的数据库之一。Wind 数据库中大量的数据来源于中英文媒体的对于不同财经新闻的报道、研究者的研究报告、科研论文等。在财经指标数据的研究领域中,Wind 数据库也针对来源于财经界的不同需要的客户例如研究机构、金融监管机构、投资机构等开发了一系列可以实施关键信息检索、财经指标数据的提取、投资组合的指导、财务运作的分析等领域的专业分析模型和专家系统。使得数据库用户可以利用这些终端工具在任何时间从数据库中准确的获取来源于财经金融市场的最新财经指标数据的报表和分析处理结果。
............................
第 3 章 上市公司绩效评价的改进 K-Means 算法...................13
3.1 引言................................13
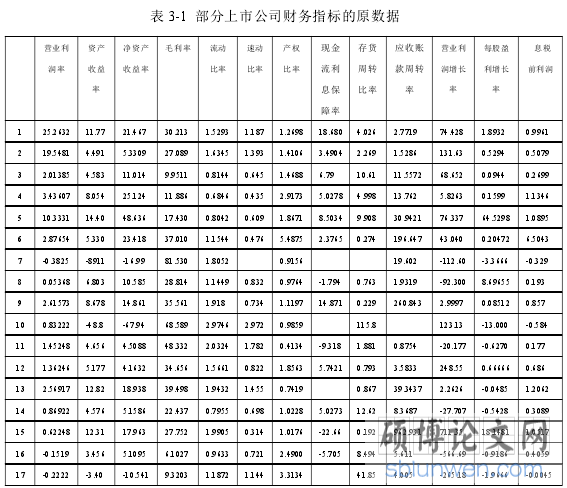
3.2 数据预处理..............................13
第 4 章 上市公司类别划分的 PSO-RF 方法.........................22
4.1 引言................................22
4.2 粒子群与随机森林协同优化方法....................22
第 5 章 总结与展望.....................32
5.1 本文总结.........................32
5.2 研究展望......................32
第 4 章 上市公司类别划分的 PSO-RF 方法
4.1 引言
本文第 3 章所提出的改进的 K-Means 算法,能对上市公司进行了财务分析,获得上市公司分类标签。而为了更加科学、准确地划分上市公司的类别,我们需要把财务指标数据根据类别划分标签进行分类研究。这样能使投资者在面对众多的投资上市公司时,筛选出这潜在投资对象和可能会存在潜在风险投资对象。在分类研究中,我们知道分类算法有基本分类算法,集成分类算法,以及神经网络分类。分类算法的复杂程度依次递增,在这里我们选取集成分类算法最常用的代表算法随机森林以及 BP 神经网络进行分类。为了避免决策树投票机制带来的弊端,本文采用粒子群算法优化参数来提升分类效果,通过实验结果验证,选择分类效果更优的PSO-RF 算法来对后续上市公司进行更为精准的类别划分。
对于组合配置与优化的问题求解,粒子群优化是常用的优化方法之一[49]。它是将粒子群类比为鸟群,单个粒子在计算过程中看作可行域中的一个可行解,但一般不是最优解。每个粒子在迭代过程中,通过将自身与其他粒子加权迭代得到新的结果,以实现自身调整和达到最优解。而本章利用粒子群优化来得到随机森林算法的三个参数,它们分别是随机森林算法的决策树的数量 l、随机属性的个数 m,决策树的剪枝阈值σ。
.........................
第 5 章 总结与展望
5.1 本文总结
针对不同概念上市公司的财务指标数据,本文把财务知识运用到数据挖掘中解决了上市公司绩效评价的问题。分别运用聚类分析、随机森林分类、BP 神经网络等数据挖掘的方法,发掘出财务数据或财务属性之间的内在联系。打破了传统财务统计报表分析的依赖性和局限性,能够帮助相关分析人员、投资者和决策者更加客观、理性深入了解到公司的经营状态。
其具体工作和结论描述如下:
1. 通过聚类算法挖掘上市公司财务指标的内在联系与不同,将上市公司进行初步类别划分之后来进行绩效评价。本文提出的改进的 K-Means 算法,通过逐步二分分裂并且一次选择极大值点的方式来选择初始聚类中心,有效地改进了 K-Means算法存在的依赖于初始条件易陷入局部最优的缺陷。使得在市场上运作表现和盈利能力更为相似的上市公司被聚在一起以供参考,更准确地获取公司类别划分的类别标签,从而能够更好地进行上市公司财务报表数据分析和经营状况评价。
2. 通过分类算法对不同上市公司的财务分析结果,进行更加准确的投资类别划分。本文运用粒子群算法对随机森林单个决策树数量、剪枝阈值以及随机属性个数,这三个参数进行了优化,有效避免了决策树投票机制带来的弊端,加强了分类器的性能。在未来进行投资时,能为投资者更加科学、准确地选取具有更好发展前景、能更大可能获取资金收益的投资对象。
参考文献(略)