第一章 绪论
1.1 研究工作的背景与意义
金融服务于实体经济,在资源配置中发挥重要作用,金融活动影响着世界各国的经济发展,在现代社会经济中占据重要地位[1]。信息时代,数据是最宝贵的财富。历史行情、金融交易、投资理财、风险控制、个人信息等金融数据随着金融行业的发展不断积累。传统投资方法难以对数量巨大、类型丰富的金融数据进行有效分析辅助投资者决策。
量化投资运用数学、计算机技术制定策略,能够有效利用金融数据。强化学习实现“感知—认知—自主决策—自我学习”的循环,呈现出自我学习的特征。量化投资作为高度数据化、数学化、程序化的行业,是强化学习很好的应用场景。金融行业需要便捷、有效、精确的量化投资丰富投资工具。随着大数据、人工智能的蓬勃发展,量化投资具备较为成熟的发展条件。基于深度强化学习构建的量化投资策略使投资具备智能,可以随时根据金融市场的变化进行学习,提升策略性能,对将强化学习应用于金融领域具有参考价值。
量化投资运用计算机对交易市场的数据进行处理并在适当时机发出买卖指令完成交易[2]。从金融市场提取有效交易信息是量化投资成功的关键,宏观经济数据、经济政策、品种交易数据、公司财务报表以及公开的即时市场消息等数据都可用于提取交易信息。一般通过搭建数学模型分析金融产品收益与风险、判断各种不同走势发生概率完成交易信息提取。量化投资可以运用的投资标的非常广泛,包括外汇、期货、股票等,目前我国可被交易的金融产品也比较丰富。
.......................
1.2 国内外研究历史与现状
Irwin[4](1986)等学者编写自动化交易程序在期货市场进行自动化交易,对期货市场的交易产生了一定变革作用。
Neftci[5](1991)等学者在道琼斯工业指数预测的研究中编写程序对价格均线产生的交易信号进行筛选,提高了收益稳定性。
Ritter[6](1992)等学者在量化投资中引入行为金融学理论,他们发现:在过去一段时间表现不好的股票在接下来的时间很有可能上涨。根据发现他们设计出著名的反转策略:在月末对股票收益率进行排序,买入收益率最低的股票并且持仓一个月后再平仓。
Jegadeesh[7](1993)等人在对投资收益进行研究时发现,过去收益较高的资产在未来一段时间内仍能保持较高收益,因此设计出与反转策略相反的动量策略:对资产的收益率进行排序,然后买入收益率较高的资产,并且持仓时间要超过反转策略的持仓时间。 Moody[8](2001)等人将强化学习算法应用在单一股票和资产投资组合中提出RRL 模型。RRL 模型的输入为收益率,目标函数为微分夏普比率(Sharp ratio),结果显示 RRL 模型在外汇、股票指数、国债等金融资产的模拟交易中获得的收益超过基于 Q-learning 的策略。
Kimk[9](2003)等学者将 SVM 运用于金融时间序列预测中,在研究中将基于SVM 的策略与基于神经网络的策略进行对比,实验结果显示基于 SVM 的策略收益率更稳定。
J. W. Lee[10](2004)基于 Q-Learning 提出 Q-trader 股票交易系统,Q-trader 通过 Q-Learning 矩阵和每个周期的利润决定持有股票的时间,完成股票买入、卖出。
Khan[11](2008)等学者将遗传算法融入基于神经网络的量化投资策略中,实验结果显示,向神经网络构建的策略中加入遗传算法能够提高准确率。
.......................
.......................
第二章 量化投资和深度强化学习
2.1 量化投资
2.1.1 有效市场假说
有效市场假说[38](Efficient Market Hypothesis,EMH)是传统金融理论的基础,认为金融市场是健全和有效的。传统金融理论围绕资产定价和投资组合对个体的投资行为进行研究,在 20 世纪 80 年代的金融研究领域占据主导地位。20 世纪初,法国数学家 Louis Bachelier 应用统计分析方法分析证券收益率,从随机过程角度对布朗运动以及股价变化的随机性进行研究,发现市场在信息方面的有效性,有效市场假说开始萌芽。1970 年,Eugene Fama 在总结前人的理论和实证的基础上正式提出有效市场假说。
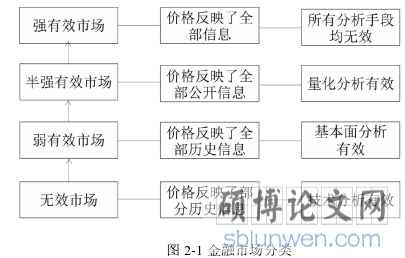
有效市场假说认为金融市场是健全和有效的,资产的价格完全反映所有可获得信息,在有效市场,金融资产的信息能够及时、充分的反映在价格中,每当出现新的重大信息,市场都能快速反应使得资产的价格与内在价值相等。在有效市场中,模式分析和相关信息不能帮助投资者获取超额利润,投资者只能获得与投资标的风险相当的收益。按照有效性由弱到强,金融市场依次可以分为三类:
2.1 量化投资
2.1.1 有效市场假说
有效市场假说[38](Efficient Market Hypothesis,EMH)是传统金融理论的基础,认为金融市场是健全和有效的。传统金融理论围绕资产定价和投资组合对个体的投资行为进行研究,在 20 世纪 80 年代的金融研究领域占据主导地位。20 世纪初,法国数学家 Louis Bachelier 应用统计分析方法分析证券收益率,从随机过程角度对布朗运动以及股价变化的随机性进行研究,发现市场在信息方面的有效性,有效市场假说开始萌芽。1970 年,Eugene Fama 在总结前人的理论和实证的基础上正式提出有效市场假说。
有效市场假说认为金融市场是健全和有效的,资产的价格完全反映所有可获得信息,在有效市场,金融资产的信息能够及时、充分的反映在价格中,每当出现新的重大信息,市场都能快速反应使得资产的价格与内在价值相等。在有效市场中,模式分析和相关信息不能帮助投资者获取超额利润,投资者只能获得与投资标的风险相当的收益。按照有效性由弱到强,金融市场依次可以分为三类:
(一)弱式有效市场。市场价格充分反映了所有能从历史交易数据中获得的信息。历史交易数据包括成交价格、成交量、融资金额、未成交订单等。在弱式有效市场中,所有的历史信息已经反应在市场价格中,依靠历史信息的技术分析方法不能帮助投资者获得超额收益,技术分析方法无效,投资者使用基本分析方法有可能获得超额收益。
(二)半强式有效市场。所有已公开的财报、公司管理信息、资产、负债、盈利数据、盈利预测及其它披露的各类有关公司营运前景的信息都已经全部充分反映在市场价格中。基本分析方法主要对公司的基本属性进行研究,因此在半强式有效市场中技术分析和基本分析都失去作用,投资者根据内幕消息有可能获得超额收益。
(三)强式有效市场。市场价格充分反映所有已公开、未公开信息。在强式有效市场中,如果存在内幕消息,相关证券价格会立刻恢复到应有的合理水平。在该类市场中,没有任何方法能帮助投资者获得超额收益。
..........................
2.2 强化学习环境构建
强化学习算法分类标准之一是 agent 能否完全访问(或学习)环境的模型,环境的模型包含 MDP 过程中的状态转移函数和奖励函数。使用模型的算法为基于模型学习(Model-Based),没有基于模型的算法为免模型学习(Model-Free)。有模型学习最大的优势在于 agent 能够根据模型提前考虑进行规划,每往前一步,都可以提前尝试未来所有可能的选择,然后再从中择优选择,智能体可以把预先规划的结果提取为学习策略,这其中最著名的是 AlphaZero。基于模型的算法可以大幅度提升采样效率,虽然基于模型的算法可以应用模型提前进行规划并提升采样效率,但最大的缺点是在很多任务学习中 agent 往往不能获得环境的真实模型,如果想在不存在真实环境模型的任务中使用基于模型的算法,那么 agent 必须完全从轨迹中学习一个模型,这会带来很多挑战。最大的挑战是:agent 探索出来的模型和真实模型之间存在误差,而这种误差会导致 agent 在学习到的模型中表现很好,但在真实的环境中表现得不好甚至很差。学习环境模型从根本上讲是非常困难的,即使花费大量的时间和计算资源,最终的结果也可能达不到预期的效果。
在算法交易问题中,不存在环境的真实模型,若 agent 想学习一个金融市场的环境模型,在某种程度上意味着对市场进行预测,由于市场预测可行性很低(甚至不可预测),因此,本文使用无模型的强化学习算法来解决量化投资问题。虽然无模型的强化学习算法放弃了有模型学习在样本效率方面的优势,但是更加易于实现和调整。
............................
(二)半强式有效市场。所有已公开的财报、公司管理信息、资产、负债、盈利数据、盈利预测及其它披露的各类有关公司营运前景的信息都已经全部充分反映在市场价格中。基本分析方法主要对公司的基本属性进行研究,因此在半强式有效市场中技术分析和基本分析都失去作用,投资者根据内幕消息有可能获得超额收益。
(三)强式有效市场。市场价格充分反映所有已公开、未公开信息。在强式有效市场中,如果存在内幕消息,相关证券价格会立刻恢复到应有的合理水平。在该类市场中,没有任何方法能帮助投资者获得超额收益。
..........................
2.2 强化学习环境构建
强化学习算法分类标准之一是 agent 能否完全访问(或学习)环境的模型,环境的模型包含 MDP 过程中的状态转移函数和奖励函数。使用模型的算法为基于模型学习(Model-Based),没有基于模型的算法为免模型学习(Model-Free)。有模型学习最大的优势在于 agent 能够根据模型提前考虑进行规划,每往前一步,都可以提前尝试未来所有可能的选择,然后再从中择优选择,智能体可以把预先规划的结果提取为学习策略,这其中最著名的是 AlphaZero。基于模型的算法可以大幅度提升采样效率,虽然基于模型的算法可以应用模型提前进行规划并提升采样效率,但最大的缺点是在很多任务学习中 agent 往往不能获得环境的真实模型,如果想在不存在真实环境模型的任务中使用基于模型的算法,那么 agent 必须完全从轨迹中学习一个模型,这会带来很多挑战。最大的挑战是:agent 探索出来的模型和真实模型之间存在误差,而这种误差会导致 agent 在学习到的模型中表现很好,但在真实的环境中表现得不好甚至很差。学习环境模型从根本上讲是非常困难的,即使花费大量的时间和计算资源,最终的结果也可能达不到预期的效果。
在算法交易问题中,不存在环境的真实模型,若 agent 想学习一个金融市场的环境模型,在某种程度上意味着对市场进行预测,由于市场预测可行性很低(甚至不可预测),因此,本文使用无模型的强化学习算法来解决量化投资问题。虽然无模型的强化学习算法放弃了有模型学习在样本效率方面的优势,但是更加易于实现和调整。
............................
第三章 基于深度强化学习的量化投资策略设计 .................20
3.1 问题定义 ....................... 19
3.2 强化学习环境构建 .............................. 20
第四章 基于深度强化学习的量化投资策略改进 ........................ 31
4.1 动作塑造 ................................ 31
4.2 优势塑造 ................................ 31
第五章 基于深度强化学习的量化投资策略实证 ............................. 44
5.1 算法改进验证 ............................. 44
5.1.1 裁剪 PPO 改进验证 ................................. 46
5.1.2 动作塑造改进验证 ..................................... 47
第五章 基于深度强化学习的量化投资策略实证
5.1 算法改进验证
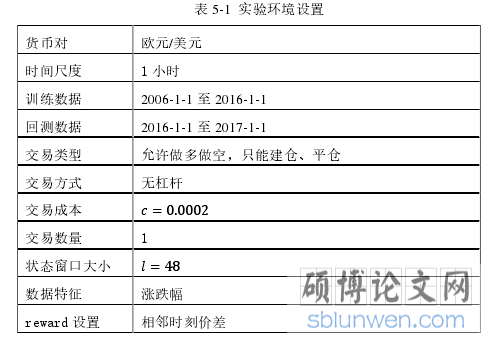
本文中策略的训练、回测在外汇市场进行,外汇交易市场是最具流动性的金融市场,在全球所有期货交易中占据着最大的交易量。外汇交易允许交易动作以近乎实时的方式执行,并允许做多、做空,当价格上升(下降)时,做多(做空)获利。
5.1 算法改进验证
本文中策略的训练、回测在外汇市场进行,外汇交易市场是最具流动性的金融市场,在全球所有期货交易中占据着最大的交易量。外汇交易允许交易动作以近乎实时的方式执行,并允许做多、做空,当价格上升(下降)时,做多(做空)获利。
...........................
第六章 全文总结与展望
6.1 全文总结
本文以深度强化学习为基础对量化投资策略进行了研究。金融活动促进货币流动,在经济发展中发挥着资源配置作用,在现代社会经济中占据重要地位。金融市场复杂多变,包含着不同的参与者,如对冲基金、券商、散户等,众多参与者的投资行为促进了金融市场的流动,使得金融市场成为复杂的、多变、非线性的动态系统。在大数据和人工智能时代,传统的投资方法不能适应社会需求。量化投资融合统计、计算机、人工智能和金融,基于历史数据建立合适的投资策略,通过计算机自动化交易获取利润,具有准确性、及时性、分散化、系统性和纪律性等优点,是前沿的投资方法。深度学习具备强大的拟合函数能力,强化学习通过 agent 与环境交互进行学习的方式使 agent 具备完全自主学习解决任务的能力,基于深度强化学习构建的量化投资策略可以随时根据金融市场的变化进行自我调整,实现感知市场变化并进行决策,使量化投资实现智能化。
6.1 全文总结
本文以深度强化学习为基础对量化投资策略进行了研究。金融活动促进货币流动,在经济发展中发挥着资源配置作用,在现代社会经济中占据重要地位。金融市场复杂多变,包含着不同的参与者,如对冲基金、券商、散户等,众多参与者的投资行为促进了金融市场的流动,使得金融市场成为复杂的、多变、非线性的动态系统。在大数据和人工智能时代,传统的投资方法不能适应社会需求。量化投资融合统计、计算机、人工智能和金融,基于历史数据建立合适的投资策略,通过计算机自动化交易获取利润,具有准确性、及时性、分散化、系统性和纪律性等优点,是前沿的投资方法。深度学习具备强大的拟合函数能力,强化学习通过 agent 与环境交互进行学习的方式使 agent 具备完全自主学习解决任务的能力,基于深度强化学习构建的量化投资策略可以随时根据金融市场的变化进行自我调整,实现感知市场变化并进行决策,使量化投资实现智能化。
本文主要完成了以下工作:
(1)针对策略输出动作的有效性与持仓状态有关的问题提出动作塑造改进。动作塑造从根本上保证策略输出有效动作,确保 agent 输出动作都能真实反映在交易环境中。通过实验验证发现动作塑造使得 agent 与环境交互的轨迹更加真实,使得策略优化更加稳定,提升了策略获利能力。
(2)针对将策略获得的收益分配给不同交易动作的难题提出了优势塑造技巧。通过塑造不同优势函数实现将收益分配给交易中的建仓、持仓、平仓等动作,实现对不同动作优化的平衡,调节策略交易频率,通过实验验证不同优势塑造的改进效果,进一步提升策略的收益。
(3)针对策略优化不稳定、训练效率低、性能不理想等问题提出裁剪 PPO 和路径引导技巧。传统策略梯度对轨迹的利用率低,标准 PPO 算法的值网络训练不收敛,通过实验验证裁剪 PPO 的确能够提高策略训练效率。路径引导提高 agent 探索环境的效率,使得收集的轨迹质量更高,通过实验验证发现路径引导极大提升训练效率,显著提升策略性能。
参考文献(略)
(1)针对策略输出动作的有效性与持仓状态有关的问题提出动作塑造改进。动作塑造从根本上保证策略输出有效动作,确保 agent 输出动作都能真实反映在交易环境中。通过实验验证发现动作塑造使得 agent 与环境交互的轨迹更加真实,使得策略优化更加稳定,提升了策略获利能力。
(2)针对将策略获得的收益分配给不同交易动作的难题提出了优势塑造技巧。通过塑造不同优势函数实现将收益分配给交易中的建仓、持仓、平仓等动作,实现对不同动作优化的平衡,调节策略交易频率,通过实验验证不同优势塑造的改进效果,进一步提升策略的收益。
(3)针对策略优化不稳定、训练效率低、性能不理想等问题提出裁剪 PPO 和路径引导技巧。传统策略梯度对轨迹的利用率低,标准 PPO 算法的值网络训练不收敛,通过实验验证裁剪 PPO 的确能够提高策略训练效率。路径引导提高 agent 探索环境的效率,使得收集的轨迹质量更高,通过实验验证发现路径引导极大提升训练效率,显著提升策略性能。
参考文献(略)