第一章 绪论
1.1 研究工作的背景与意义
深度学习(Deep Learning)是一种人工智能技术,它模仿人脑在处理数据和创建用于决策的模式方面的工作。深度学习是人工智能(AI)中机器学习的一个子集,它具有能够从未结构化或未标记的数据中不受监督地学习的网络。也称为深度神经学习或深度神经网络。
深度学习与数字时代同步发展,数字时代带来了来自世界各地的各种形式的数据爆炸式增长。这些数据(简称为大数据)来自社交媒体,互联网搜索引擎,电子商务平台和在线电影院等资源。大量数据易于访问,可以通过云计算等相关科技应用程序共享。
1.1 研究工作的背景与意义
深度学习(Deep Learning)是一种人工智能技术,它模仿人脑在处理数据和创建用于决策的模式方面的工作。深度学习是人工智能(AI)中机器学习的一个子集,它具有能够从未结构化或未标记的数据中不受监督地学习的网络。也称为深度神经学习或深度神经网络。
深度学习与数字时代同步发展,数字时代带来了来自世界各地的各种形式的数据爆炸式增长。这些数据(简称为大数据)来自社交媒体,互联网搜索引擎,电子商务平台和在线电影院等资源。大量数据易于访问,可以通过云计算等相关科技应用程序共享。
但是,通常是非结构化的数据如此庞大,以至于人类可能需要数十年才能理解并提取相关信息。人们意识到,挖掘这些丰富的信息可能会带来令人难以置信的潜力,并且越来越多地采用 AI 系统进行自动化支持,但与此同时,过于庞杂的非结构化数据也导致了深度学习训练的时间成本和硬件成本居高不下。尤其是当需要分析的数据达到 PB 级别时更是如此。
此外,不仅仅是数据成本会导致上述问题,当深度学习涉及的计算维度增大时,过于高昂的学习成本和容错性也会带来不可避免的问题。
此外,不仅仅是数据成本会导致上述问题,当深度学习涉及的计算维度增大时,过于高昂的学习成本和容错性也会带来不可避免的问题。
另一方面,大数据(Big Data)技术则主要关注庞大,快速或复杂的数据,它们往往因其特性而很难或不可能使用传统方法进行处理。访问和存储大量信息以进行分析的行为已经存在了很长时间。但是大数据的概念在 2000 年代初得到了发展,当时行业分析师道格·兰尼(Doug Laney)将当今主流的大数据定义表达为三个 V:
数量:组织从各种来源收集数据,包括商业交易,智能(IoT)设备,工业设备,视频,社交媒体等。在过去,存储它曾经是一个问题–但是在 Hadoop 等平台上更便宜的存储减轻了负担。
速度:随着物联网的发展,数据以前所未有的速度流入企业,必须及时处理。RFID 标签,传感器和智能仪表推动了近实时处理这些数据洪流的需求。
种类繁多:数据有各种格式-从传统数据库中的结构化数字数据到非结构化文本文档,电子邮件,视频,音频,股票行情记录数据和财务交易。
.....................
第三章 并行化 LSTM 算法设计 ......................... 23数量:组织从各种来源收集数据,包括商业交易,智能(IoT)设备,工业设备,视频,社交媒体等。在过去,存储它曾经是一个问题–但是在 Hadoop 等平台上更便宜的存储减轻了负担。
速度:随着物联网的发展,数据以前所未有的速度流入企业,必须及时处理。RFID 标签,传感器和智能仪表推动了近实时处理这些数据洪流的需求。
种类繁多:数据有各种格式-从传统数据库中的结构化数字数据到非结构化文本文档,电子邮件,视频,音频,股票行情记录数据和财务交易。
.....................
1.2 国内外研究历史与现状
在文献[9]中,作者提出了一种并发多维的“金字塔”式的 LSTM 算法——PyraMiD-LSTM。该算法主要针对图像识别,识别在生物医学中扫描大脑切片的图片并进行快速分割分类的操作。
论文首先比较了传统 CNN 算法的缺点,认为对于视频中的每一帧或者图像中的每个像素点来说,CNN 算法只接受严格的时间前后序数据作为输入。相比之下,多维 RNN(MD-RNNs)尤其是多维 LSTM(MD-LSTM),对于每个时间点,均可接受时间和空间上的前序数据作为输入。
其次,论文提出了自己的 PyraMiD-LSTM 的特点,新模型里放弃了逐像素正方形式(Cuboid)运算的方式,改为逐像素金字塔式(Pyramidal)运算。这使得PyraMiD-LSTM 的并行运算性能大大提高,增强了 GPU 对 3D 数据例如脑切片图(Brain Slice Images)的处理能力。
标准的多维 LSTM 由 4 个 LSTM 组成,每个 LSTM 沿着 x,y 坐标轴方向传输数据,以东北->西南方向 LSTM 为例,每个像素点接收邻近的左,上 2 个方位的数据。二维 LSTM 从东北->西南,东南->西北,西南->东北,西北->东南四个方向传输数据,每个像素点要接收 4 个 LSTM 的输出数据。将其旋转 45°,其间产生了许多空隙,填充额外的连接,这样每个像素接收到了西,西北,西南 3 个方位的数据,加上本身一共 4 个格子,构成了金字塔式连接(PyraMiD LSTM),因此算上四个方向,每个像素可以接收邻近 8 个方位的数据,比二维 LSTM 提升了一倍。
这一点微小的改变,使得对于每个 PyraMiD-LSTM,像素收到的数据一定是从北,西北,东北方向传来,每次可以处理一横行的像素,逐行像素处理相比于逐个像素处理,大大提高了在 GPU 上并行运算的效率。
.............................
在文献[9]中,作者提出了一种并发多维的“金字塔”式的 LSTM 算法——PyraMiD-LSTM。该算法主要针对图像识别,识别在生物医学中扫描大脑切片的图片并进行快速分割分类的操作。
论文首先比较了传统 CNN 算法的缺点,认为对于视频中的每一帧或者图像中的每个像素点来说,CNN 算法只接受严格的时间前后序数据作为输入。相比之下,多维 RNN(MD-RNNs)尤其是多维 LSTM(MD-LSTM),对于每个时间点,均可接受时间和空间上的前序数据作为输入。
其次,论文提出了自己的 PyraMiD-LSTM 的特点,新模型里放弃了逐像素正方形式(Cuboid)运算的方式,改为逐像素金字塔式(Pyramidal)运算。这使得PyraMiD-LSTM 的并行运算性能大大提高,增强了 GPU 对 3D 数据例如脑切片图(Brain Slice Images)的处理能力。
标准的多维 LSTM 由 4 个 LSTM 组成,每个 LSTM 沿着 x,y 坐标轴方向传输数据,以东北->西南方向 LSTM 为例,每个像素点接收邻近的左,上 2 个方位的数据。二维 LSTM 从东北->西南,东南->西北,西南->东北,西北->东南四个方向传输数据,每个像素点要接收 4 个 LSTM 的输出数据。将其旋转 45°,其间产生了许多空隙,填充额外的连接,这样每个像素接收到了西,西北,西南 3 个方位的数据,加上本身一共 4 个格子,构成了金字塔式连接(PyraMiD LSTM),因此算上四个方向,每个像素可以接收邻近 8 个方位的数据,比二维 LSTM 提升了一倍。
这一点微小的改变,使得对于每个 PyraMiD-LSTM,像素收到的数据一定是从北,西北,东北方向传来,每次可以处理一横行的像素,逐行像素处理相比于逐个像素处理,大大提高了在 GPU 上并行运算的效率。
.............................
第二章 YARN-TensorFlow 复合系统设计
2.1 复合系统与 LSTM 结合的可行性分析
从第一章的讨论中可以看出,使用包括 LSTM 算法在内的深度学习算法进行时序序列预测时,当算法面临着越来越庞杂的数据需求,或者面临要在多节点集群上进行训练分析时,其所承担的效率压力将会越来越大。
而另一方面,并行化和大数据技术,则恰好是解决数据压力和效率压力的一个较好的突破口。
一方面,YARN 作为一个成熟的大数据框架,具有良好的分布式资源调度能力和优秀的大数据处理能力。另一方面,TensorFlow 作为一个广泛使用的深度学习框架,其有较为良好的对 GPU 运算能力的支撑和可行的对分布式架构的支持。如果能够解决深度学习框架和大数据技术的结合难题,并且针对深度学习算法本身进行进一步的并行化改造,将三者的优点和长处结合在一起,将有可能极大地缓解LSTM 算法在处理大批量数据和协调多节点集群时所面临的巨大的效率压力和数据压力。
2.1 复合系统与 LSTM 结合的可行性分析
从第一章的讨论中可以看出,使用包括 LSTM 算法在内的深度学习算法进行时序序列预测时,当算法面临着越来越庞杂的数据需求,或者面临要在多节点集群上进行训练分析时,其所承担的效率压力将会越来越大。
而另一方面,并行化和大数据技术,则恰好是解决数据压力和效率压力的一个较好的突破口。
一方面,YARN 作为一个成熟的大数据框架,具有良好的分布式资源调度能力和优秀的大数据处理能力。另一方面,TensorFlow 作为一个广泛使用的深度学习框架,其有较为良好的对 GPU 运算能力的支撑和可行的对分布式架构的支持。如果能够解决深度学习框架和大数据技术的结合难题,并且针对深度学习算法本身进行进一步的并行化改造,将三者的优点和长处结合在一起,将有可能极大地缓解LSTM 算法在处理大批量数据和协调多节点集群时所面临的巨大的效率压力和数据压力。
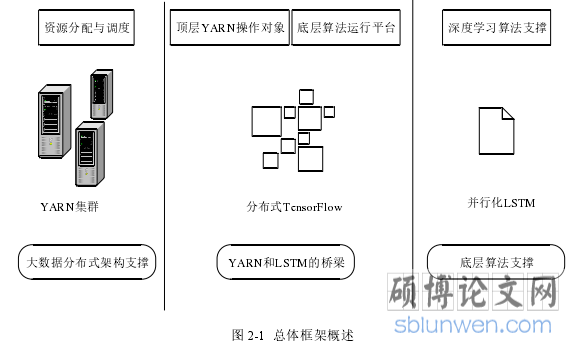
因此,本文计划设计这样一个复合系统:
以 LSTM 算法作为项目底层算法支撑,提供有效的针对时序序列预测的深度学习算法;以 YARN 作为项目顶层分布式架构支撑,利用 YARN 本身的特性,有效的进行资源调度预分配,为分布式并行化计算提供可靠的性能支撑。
而 TensorFlow,作为一个跨平台、有分布式相关支持的开源 ML 软件库,可以有效的起到类似中间件的效果,连接顶层的 YARN 和底层的 LSTM,为两者搭起桥梁。
需要注意的是,尽管 TensorFlow 本身提供了一定的分布式部署的相关功能支撑,但是其本身功能仍然较为简陋,因此,仅仅依靠 TensorFlow 自身来搭建分布式架构仍然欠妥,因此这里仍然需要结合 YARN 来搭建。
............................
以 LSTM 算法作为项目底层算法支撑,提供有效的针对时序序列预测的深度学习算法;以 YARN 作为项目顶层分布式架构支撑,利用 YARN 本身的特性,有效的进行资源调度预分配,为分布式并行化计算提供可靠的性能支撑。
而 TensorFlow,作为一个跨平台、有分布式相关支持的开源 ML 软件库,可以有效的起到类似中间件的效果,连接顶层的 YARN 和底层的 LSTM,为两者搭起桥梁。
需要注意的是,尽管 TensorFlow 本身提供了一定的分布式部署的相关功能支撑,但是其本身功能仍然较为简陋,因此,仅仅依靠 TensorFlow 自身来搭建分布式架构仍然欠妥,因此这里仍然需要结合 YARN 来搭建。
............................
2.2 复合系统基本框架设计
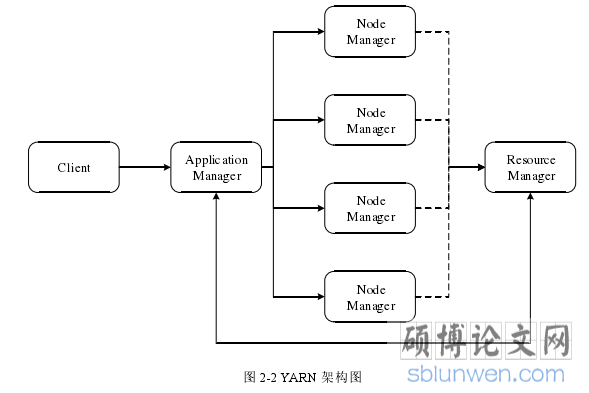
一个常规的 YARN 框架应当包含三个主要组件[13]:ResourceManager(以下简称 RM),ApplicationManager(以下简称 AM)和 NodeManager(以下简称 NM),分别负责资源调度,应用任务分配和节点管理,用户提交一个 Application 给 YARN系统,则系统由 AM 接收,拆分出多个 Task,并通过向 RM 申请的方式,分配给多个 NM,NM 本身维持一个与 RM 的心跳连接,汇报自身情况,作为 RM 进行资源调度的参考。
一个常规的 YARN 框架应当包含三个主要组件[13]:ResourceManager(以下简称 RM),ApplicationManager(以下简称 AM)和 NodeManager(以下简称 NM),分别负责资源调度,应用任务分配和节点管理,用户提交一个 Application 给 YARN系统,则系统由 AM 接收,拆分出多个 Task,并通过向 RM 申请的方式,分配给多个 NM,NM 本身维持一个与 RM 的心跳连接,汇报自身情况,作为 RM 进行资源调度的参考。
具体 YARN 架构如图 2-2 所示。
而一个常规的分布式 TensorFlow 架构目前而言仍然较为简陋。以常见的 PS 架构(Parameter Server)为例,一个分布式 TensorFlow 集群(cluster)由一个或多个TensorFlow 服务器(Server)组成[14],Server 在逻辑上被划分成两类:用于存放模型参数的 Parameter Server 和负责计算参数梯度的 Worker。每个 Server 都有与之对应的一个 Task,而分布式 TensorFlow 本身最大的问题就是,所有 Task 与 server 的绑定关系是需要用户手动配置的,其容错性、调度能力均非常有限。
..........................
而一个常规的分布式 TensorFlow 架构目前而言仍然较为简陋。以常见的 PS 架构(Parameter Server)为例,一个分布式 TensorFlow 集群(cluster)由一个或多个TensorFlow 服务器(Server)组成[14],Server 在逻辑上被划分成两类:用于存放模型参数的 Parameter Server 和负责计算参数梯度的 Worker。每个 Server 都有与之对应的一个 Task,而分布式 TensorFlow 本身最大的问题就是,所有 Task 与 server 的绑定关系是需要用户手动配置的,其容错性、调度能力均非常有限。
..........................
3.1 并行化 LSTM 算法设计 ..................... 23
3.2 算法实现 ............................... 24
第四章 仿真实验结果分析 ............................................ 55
4.1 实验运行环境 .............................. 55
4.2 YARN-TensorFlow 复合系统性能实验 ....................... 55
第五章 全文总结与展望 .......................... 79
5.1 全文总结 .............................. 79
5.2 后续工作展望 .......................... 81
第四章 仿真实验结果分析
4.1 实验运行环境
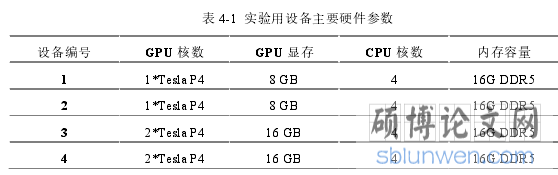
本实验需要用到多台设备用以搭建集群,设备众多性能中,会对运行速率产生较大影响的因素包括:GPU 显存、GPU 核数、CPU 核数、内存容量等。本次实验前后共计使用到了 4 台设备,它们具体的关于上述参数的配置信息如表(2-16)所示。
实验数据采用了一组开源的电池数据,由于涉及到 LSTM 算法改进实现的相关描述,具体数据格式与数据内容会在 3.2 节进行介绍,在此不做赘述。
实验中深度学习算法训练内容为给出截至目前为止的电池充放电状态记录,预测出未来一段时间的电池状态情况。
实验中深度学习算法训练内容为给出截至目前为止的电池充放电状态记录,预测出未来一段时间的电池状态情况。
实验主要目的为通过设置对比实验,判断比较 YARN+TensorFlow 的组合方案,相较于仅采用分布式 TensorFlow 解决方案而言,在运算效率和运算速度上,是否有改进。
.........................
第五章 全文总结与展望
5.1 全文总结
本课题主要探讨的内容是:基于 LSTM 的时间序列预测算法的并行化研究,主要针对的问题是,当 LSTM 算法面对规模过于庞大的数据集,或者应对多节点分布式集群时,处理能力不够高效的问题。
为了解决上述问题,本文在第一章第 1.1 节分析了工作背景后得出了一个可行的解决思路:
首先,引入大数据平台 YARN,其无论是应对分布式集群资源管理,还是面对大批量的数据处理,都有较为成熟的技术支撑,可以作为一个较好的顶层资源管理调度和任务分配框架。
其次,引入支持一定分布式架构功能的 TensorFlow 框架,配合上 TensorFlow框架对 GPU 利用和深度学习算法的良好支撑,作为衔接底层 LSTM 算法和顶层YARN 框架之间的桥梁。
5.1 全文总结
本课题主要探讨的内容是:基于 LSTM 的时间序列预测算法的并行化研究,主要针对的问题是,当 LSTM 算法面对规模过于庞大的数据集,或者应对多节点分布式集群时,处理能力不够高效的问题。
为了解决上述问题,本文在第一章第 1.1 节分析了工作背景后得出了一个可行的解决思路:
首先,引入大数据平台 YARN,其无论是应对分布式集群资源管理,还是面对大批量的数据处理,都有较为成熟的技术支撑,可以作为一个较好的顶层资源管理调度和任务分配框架。
其次,引入支持一定分布式架构功能的 TensorFlow 框架,配合上 TensorFlow框架对 GPU 利用和深度学习算法的良好支撑,作为衔接底层 LSTM 算法和顶层YARN 框架之间的桥梁。
最后,将 LSTM 算法并行化处理,在并行化过程中,尤其注意 LSTM 算法与上层分布式框架的适配性,选取合适的并行化方法。
在基本思路定性之后,文章在第二章至第四章,采用自顶向下的顺序,针对上述思路的基本实现方式进行了讨论。
在第二章,文章重点讨论了 YARN 框架的改进以及与下层 TensorFlow 的适配问题。
在 YARN 端,通过对原有 YARN 的任务分配代码进行自定义,使得 YARN 在保留原有的 ApplicationManager 的应用管理机制和 ResourceManager 中的资源管理机制的前提下,作为资源管理和任务协调者,向下层被封装在容器内的分布式TensoFlow 发送任务和分配资源。
同时,在 TensorFlow 端,系统通过多工镜像策略(MultiWorkerMirroredStrategy)来作为 TensorFlow 端的镜像部署策略,同时,针对多工镜像策略中的资源分配方式进行自定义,以满足底层 LSTM 算法的并行化需求。 最后,顶层 YARN 向底层 TensorFlow 端的交互,主要依靠由 Jython 提供的跨语言调用机制,通过自定义公共接口模块来实现。
参考文献(略)
在基本思路定性之后,文章在第二章至第四章,采用自顶向下的顺序,针对上述思路的基本实现方式进行了讨论。
在第二章,文章重点讨论了 YARN 框架的改进以及与下层 TensorFlow 的适配问题。
在 YARN 端,通过对原有 YARN 的任务分配代码进行自定义,使得 YARN 在保留原有的 ApplicationManager 的应用管理机制和 ResourceManager 中的资源管理机制的前提下,作为资源管理和任务协调者,向下层被封装在容器内的分布式TensoFlow 发送任务和分配资源。
同时,在 TensorFlow 端,系统通过多工镜像策略(MultiWorkerMirroredStrategy)来作为 TensorFlow 端的镜像部署策略,同时,针对多工镜像策略中的资源分配方式进行自定义,以满足底层 LSTM 算法的并行化需求。 最后,顶层 YARN 向底层 TensorFlow 端的交互,主要依靠由 Jython 提供的跨语言调用机制,通过自定义公共接口模块来实现。
参考文献(略)