1 绪论
1.1 研究背景与意义
国内三大运营商日益完善的高速网络工程建设,各个运营商在传统的业务方面已经面对着竞争对手与日俱增的压力。在主套餐、流量包等传统业务获得的利润方面也面临着对手运营商不断蚕食。通信行业的业务划分也从早先的产品细分转向客户细分,以用户为核心的精准化营销成为了业务营销的主流[1-3]。家庭用户市场一直以来都是各大运营商发力角逐的市场,是通信行业重点竞争的市场,是各大运营商开拓收入的增长点。运营商存储着用户的各种历史通话记录,运营商急需一种家庭关系识别模型在海量的用户历史通话记录中准确的识别出家庭用户,进而分析家庭用户的业务行为特征,然后根据特征进行针对性的业务营销,从而提高业务营销成功率和降低业务营销成本。随着携号转网政策的实行,基于家庭用户的异网策反和家庭融合套餐也将成为运营商重要的增收切入点。
随着智能手机迅速普及,通话社交网络也日益成为最大的社交网络。通话社交网络作为真实世界关系网络的映射,用户在通话社交网络的社交关系也体现着在真实世界中与其他人的亲密关系。家庭作为一种基本的社交关系,不同的家庭用户间有着相似的家庭特征。所以,在通话社交网络中,同一家庭的用户会按照家庭特征聚合到一起,而不同家庭的用户会彼此疏远,此时的通话社交网络呈现出一定的社区结构。通过发现通话社交网络的这些社区结构,就能实现家庭关系的识别。社区发现算法可以用来解决社交网络中社区结构的发现问题。因此,根据社交网络的社区发现理论在通话社交网络构建家庭关系识别模型,可以从整个社交网络的角度完成家庭关系判断,对提高识别家庭关系的准确率有着非常重要的意义。
.........................
1.2 国内外研究现状
1.2.1 社区发现研究现状
随着互联网技术发展的突飞猛进以及互联网加的提出[7,8],网络数据爆炸式增长,网络结构也日趋复杂,研究网络中的规律已经成为当下的一个热点问题。并且网络中的节点也不局限于人,还可能是论文、网页、物品等[9,10]。早在 18 世纪中期,人们开始对网络进行研究,欧洲数学家欧拉发表《格尼斯堡的七座桥》一文,通过对问题的深入探索与证明,并在解答七座桥问题的同时,开创了图论这一数学领域新的分支。科学家们遵循图论理论对网络不断进行深入研究,对现实网络构建了大量数学模型,发现这些网络模型在网络结构中表现出相似的特征和规律,同时发现网络的一个重要特征——社区结构。对于社区结构,目前还没有给出严格的定义。但是,目前公认的社区结构定义[11,12]是:社区内部连接紧密,社区间连接稀疏。不少研究者的学术成果表明,由实际生活关系构成的现实网络中都存在着社区结构这一重要特征。社区结构在网络的研究中起着非常重要的作用,很多研究者期望在社区结构的发现过程中,能够获取隐藏在网络中的信息,从而对网络的结构、特征和演化提供更加可靠的理论支撑。
社区发现是一个涉及生物学、物理学、化学、计算机科学、心理学、社会学的多个领域的交叉课题[13-17]。自从提出了社区发现问题,很多的研究者提出了大量的挖掘网络社区结构的思想和方法。网络的类型是多种多样的,通常考虑的是无方向、无权重、无重叠的网络类型。这也是研究网络中的最基本的类型,大多数的社区发现方法和思想都是针对这种网络类型的。然而实际中的网络是存在带方向、有权重、或者是有重叠的网络。例如在通话社交网络中,每个节点代表一个用户,节点之间的边则代表着用户的通话关系,边的方向代表着用户间呼叫的方向。
...........................
2 相关工作和技术
2.1 社交网络及社区发现理论
2.1.1 社交网络
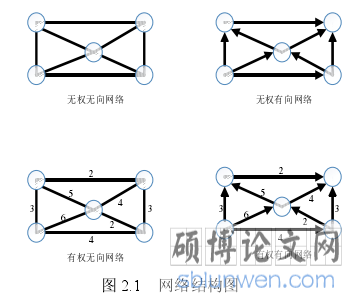
节点间存在着丰富的连接关系,所有的节点与节点间的这些连接关系组成了一张巨大的社交网络,图是表达这种网络关系最直观的数据结构,因此社交网络通过图拓扑数据结构反映网络中节点复杂的内在连接关系。在社交网络中,用户使用节点表示,用户之间如果存在某种关系则在代表用户的节点之间产生一条边。根据网络中的边是否存在权值将网络分为有权网络或无权网络,此时社交网络抽象为图论中的有权图和无权图。根据网络中的节点之间是否存在指向关系将网络分为有向网络和无向网络,此时社交网络抽象为图论中的有向图和无向图。因此根据边是否存在指向关系和是否存在权值将社交网络划分成四种类型的网络,如图 2.1 所示。
..........................
2.2 Spark 分布式计算平台
Spark 是大数据领域中数据处理与数据挖掘的有力工具。由于其开源、基于内存的高性能的分布式计算,现在逐渐取代 Hadoop 成为大数据领域中数据分析与挖掘的优选方案。Spark 是基于内存计算的分布式并行高性能计算平台,把大量数据放在内存中计算,可以减少磁盘读写,因此在处理大量数据时拥有出色的性能。通过采用“血统”容错的机制,保证计算平台的高容错性和可靠性。Spark 可以部署在大量廉价的计算机集群上,获得更高性能的计算能力。Spark 支持交互式查询与流式处理等多种计算机模式,广泛应用于实时流处理、交互查询、机器学习等应用领域。
Spark 是大数据领域中数据处理与数据挖掘的有力工具。由于其开源、基于内存的高性能的分布式计算,现在逐渐取代 Hadoop 成为大数据领域中数据分析与挖掘的优选方案。Spark 是基于内存计算的分布式并行高性能计算平台,把大量数据放在内存中计算,可以减少磁盘读写,因此在处理大量数据时拥有出色的性能。通过采用“血统”容错的机制,保证计算平台的高容错性和可靠性。Spark 可以部署在大量廉价的计算机集群上,获得更高性能的计算能力。Spark 支持交互式查询与流式处理等多种计算机模式,广泛应用于实时流处理、交互查询、机器学习等应用领域。
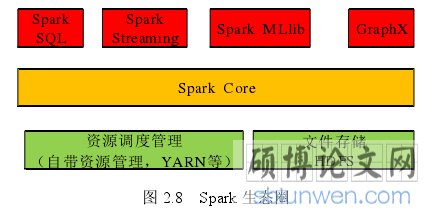
Spark 自诞生之初就广受关注,目前成为大数据领域中发展最迅速的一种技术方案。目前已经有很多互联网公司构建自己的 Spark 平台作为数据挖掘的平台支撑。经过多年的发展,Spark 形成了较为完整的 Spark 生态圈,如图 2.8 所示,Spark 生态圈主要包括三个部分:第一部分是 Spark Core,是 Spark 最基本的也是最核心的部分,该部分提供了 Spark 的各种并行操作算子。第二部分是 Spark SQL、Spark Streaming、Spark MLlib以及 GraphX 等各种组件。Spark SQL 是 Spark 用于处理结构化数据的组件,内嵌了查询优化框架,把 SQL 解析成逻辑执行计划之后,最后变成 RDD 的计算。Spark Streaming是构建在 Spark 的实时计算组件,用于高吞吐量的,高容错机制的实时流数据处理领域。Spark MLlib 是 Spark 中的扩展的机器学习库,它包含分类、回归、聚类、协同过滤等一系列的机器学习算法和工具,还包含一些底层的优化原语和高层的管道 API。GraphX 是Spark 中用于图分析的组件,它提供了用于图计算的函数接口,解决了分布式图处理中的图计算问题。第三部分是资源管理和数据访问层。通过 Spark 自带的资源管理框架或者 YARN 等第三方资源管理框架进行集群的资源分配和任务调度。通过读写 HDFS 等分布式存储系统完成数据的存储与访问功能。
 ..........................
..........................
3 Louvain 算法并行化及改进研究 ......................................... 243.1 Louvain 算法并行化研究 .................................. 24
3.1.1 GraphX 编程概念 ........................................ 24
3.1.2 Louvain 算法并行化实现 ............................. 25
4 CGL 算法改进及社区并行分解研究 ........................................ 41
4.1 CGL 算法改进研究 ......................................... 41
4.1.1 CGL 算法改进基本思想 ................................. 41
4.1.2 CGL 算法改进关键步骤 ............................ 42
5 ICGL 算法在家庭关系识别的应用 .......................................... 51
5.1 家庭关系识别 ......................................... 51
5.1.1 通话社交网络 .................................... 51
5.1.2 家庭识别问题的提出 ............................. 52
5 ICGL 算法在家庭关系识别的应用
5.1 家庭关系识别
5.1.1 通话社交网络
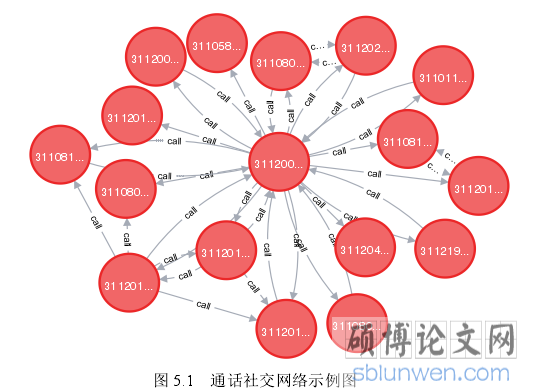
智能手机的普及,使得手机通讯成为当今社交网络中最普遍的联系方式。运营商保存着用户的历史通讯记录,因此,可以利用通讯记录构建通话社交有向网络。
.........................
6 总结与展望
6.1 总结
随着通讯网络的蓬勃发展,运营商在传统的业务上面对着竞争对手与日俱增的压力。在主套餐、流量包等传统业务获得的利润方面遭受着对手运营商的不断蚕食。家庭用户市场是通信行业重点竞争的市场,是各大运营商开拓收入的增长点。运营商急需一种家庭关系识别模型,能够在海量的用户历史通话记录中准确地识别出家庭用户。随着智能手机迅速普及,通话社交网络也日益成为最大的社交网络。通话社交网络作为现实世界关系网络的映射,用户在通话社交网络的社交关系也体现着现实世界的亲密关系。同一家庭的用户会按照家庭特征聚合到一起,而不同家庭的用户会彼此疏远,此时的通话社交网络呈现出一定的社区结构。针对这一特征,本文提出通过社交网络的社区发现算法构建通话社交网络上的家庭关系识别模型。通过对现有的社区发现算法进行对比,本文选择 Louvain 算法作为家庭关系识别模型的社区发现算法。目前,真实世界的社交网络规模早已达到亿级别,海量的数据为社区发现以及家庭关系识别模型构建带来了严峻的挑战。分布式并行计算平台是大数据处理、分析、价值挖掘的利器,通过对比分析多种分布式计算平台,本文采用 Spark 并行计算平台作为家庭关系识别模型应用环境。Spark提供了用于图分析和图计算的 GraphX 组件,所以本文重点研究基于 GraphX 的 Louvain算法并行化以及在 Spark 平台上构建家庭关系识别模型。主要工作总结为以下几点:
1.为了满足大规模网络社区发现的时间需求,完成 Spark 大数据分布式计算平台环境的搭建,本文深入研究了分布式计算平台的数据加载与预处理、Spark RDD、GraphX并行化编程机制。
2.基于 GraphX 实现 Louvain 算法并行化。Louvain 算法是社区发现算法中效率、识别结果较为优秀的算法。本文分析 Louvain 算法的基本原理,通过 GraphX 的发送、聚合消息机制完成 Louvain 算法的核心计算步骤,在 GraphX 上实现 Louvain 算法的并行化,针对并行化后出现的消息滞后问题进行解决,实现了基于进程锁思想的 PLL 算法和基于连通图思想的 CGL 算法。通过对实验结果分析,综合考虑大规模网络社区发现的运行时间和结果精度,最终选择基于连通图思想的改进思想,即 CGL 算法。
参考文献(略)