1 绪论
1.1 论文研究背景
目前,网络科技的高速发展以及各类电子产品的普及,随之而来的是多种多样的电子信息,我们已然进入了一个信息化的时代。在这个信息化的时代,各国竞相争夺的除了类似石油这种不可再生的能源外,还有就是人才的争夺,而后者,被誉为是全球最稀缺资源的争夺战。各个国家和企业也采取各种的手段留住人才,因为不管是国家还是企业,高质量的人才都是它们在发展和创新过程中不可或缺的一部分。人才的引进关系到一个企业能否在激烈竞争中脱颖而出,所以许多企业对人才的苛求近乎偏执,如何为企业招募并且留住人才就成为各个企业是否能够蓬勃发展的重中之重。一个企业从创业到上市这个漫长的企业经营过程中,各个阶段都需要专业的人才去支撑。因此,招聘工作也已经成为企业发展过程中的重要一环。
对于大多数企业来说,传统的招聘方式始终无法解决当前人才招聘的问题。其原因主要有以下几点:
(1)传统招聘方式成本的问题。传统的招聘方式,由于信息传播存在一定的局限性,所以企业想要招聘人才需要很高的成本。这对于大公司也许不算什么,但是对于一些中小企业来说,这种成本高但是效率低的招聘方式显然不适合他们。
(2)信息不对称的问题。企业找不到合适的人才,而求职者也不知道去哪里找适合自己的企业,传统招聘方式很难快速的解决这样的问题。
(3)传统招聘方式效率比较低。企业招聘的时候一般都是用人比较着急,而传统招聘方式往往时效跟不上。
(4)传统招聘方式招聘渠道的限制。企业想要招聘人才会受到地域的限制。在过去如果一个地区的企业想要招聘其它地区一些重点大学的学生,那么就必须要依靠人力去一些重点大学或者人才市场组织招聘。
......................
1.2 研究目的和意义
在这个网络科技高速发展的时代,传统的招聘方式已经不能满足企业对人才招聘的需求。网络招聘因为具有时效性强、针对性强、招聘效果好以及覆盖面广的特点而受到企业的欢迎,已经成为当前的主流招聘形式。目前网络招聘主要有两种方式:一是注册成为相关网站的会员,在网站上发布相关的职位信息,然后收集求职者的资料,并从中选择合适的人才;二是通过在自己企业的官方网站上发布职位信息,吸引人才。前者这种注册成为网站会员的方式更为普遍,并且互联网上也存在很多这样的招聘网站,例如Boss 直聘、猎聘网、智联招聘、拉勾网以及前程无忧等等。
在当前这个网络招聘为主流形式的时代,各大招聘网站招聘者和求职者的数量逐年增加,各种各样的岗位需求层出不穷,在这个求职应聘的过程中无疑是一个数据产生的过程,数据可挖掘的价值毋庸置疑。
随着经济和科技的高速发展,社会对于人才的需求也趋向于多元化,虽然各级高校都开始进入了扩招期,但也因此导致了各级高校所开设的专业与当前社会的人才供求不能够完全匹配。况且我国每年成几何性爆炸增长的应往届毕业生所构成的求职大军以及教育质量的下滑性,引来了当今大学生的就业压力,使得他们在这个供大于求的招聘市场中感到很迷茫。而本文的研究目的就在于利用数据挖掘技术挖掘当前存在于招聘市场产生的数据中的潜在信息,通过对网络招聘数据的深入分析,从而得到互联网行业对于人才的需求现状,不同岗位的需求量、经验要求、薪资水平分布、所处公司规模、类别等现状以及现阶段各职位的技能要求,然后利用关联规则算法挖掘其中的关联关系,并将其进行可视化展示,以便清晰明了的展示当前社会的人才需求情况。
..............................
2 相关技术与理论基础
2.1 基础理论
2.1.1 数据挖掘
数据挖掘就是运用合适的算法分析数据,将数据中的一些信息挖掘出来[8],这些信息往往隐藏在已有的数据中,不能够直接得到,但是又具有一定的潜在价值。可以是从数据仓库中获得,或者是利用技术手段获取互联网中的数据,目前已经成为相关领域研究的热点问题。数据挖掘主要分为数据准备、规律寻找和规律表示[9]。数据准备是通过一定的渠道或者技术手段得到想要的数据,并将这些数据进行预处理整理成合适的数据集;规律寻找是运用相应的分析方法将数据中隐藏的规律挖掘出来;规律表示则是将这些规律用直观化或者用户可以接受的方式进行展示。
数据挖掘的任务有关联分析、聚类分析、分类分析、异常分析、特异群组分析和演变分析等。主要基于人工智能、机器学习、模式识别、统计学、数据库和可视化等相关的技术和理论[10],自动地将数据集中的每一条数据进行分析推理,然后从中找到潜在的规则,有助于企业调整策略,作出正确的决策。
2.1.2 关联规则
关联分析是发现事物之间关联关系的分析过程[13],是反映两个事物之间的内在联系,是数据挖掘领域常用的一类算法,主要用于从大量数据中挖掘出有价值的数据项之间的相关关系,产生清晰有用的结果并支持间接数据挖掘。
关联规则是形如 X→Y 的蕴含表达式,其中 X 和 Y 是不相交的项集,关联规则的强度可以用它的支持度和置信度来度量。支持度是用来确定关联规则中频繁项集的最小阈值,就是在所有的项集中同时包含 X 和 Y 的项集数和所有项集数之比。也即同时包含 X 和 Y 的项集出现的概率,支持度大于或等于指定的最小支持度的项集就是频繁项集。置信度是确定包含 Y 的项集在包含 X 的项集中出现的频繁程度,即所有同时包含 X 和 Y 的项集数与所有包含 X 的项集数之比。在挖掘关联规则时,关联规则必须要满足最小支持度和最小置信度这两种阈值,如果关联规则既满足大于等于最小置信度,还大于等于最小支持度则称之为强关联规则,反之则不是,通常我们所说的都是强关联规则。
关联分析是发现事物之间关联关系的分析过程[13],是反映两个事物之间的内在联系,是数据挖掘领域常用的一类算法,主要用于从大量数据中挖掘出有价值的数据项之间的相关关系,产生清晰有用的结果并支持间接数据挖掘。
关联规则是形如 X→Y 的蕴含表达式,其中 X 和 Y 是不相交的项集,关联规则的强度可以用它的支持度和置信度来度量。支持度是用来确定关联规则中频繁项集的最小阈值,就是在所有的项集中同时包含 X 和 Y 的项集数和所有项集数之比。也即同时包含 X 和 Y 的项集出现的概率,支持度大于或等于指定的最小支持度的项集就是频繁项集。置信度是确定包含 Y 的项集在包含 X 的项集中出现的频繁程度,即所有同时包含 X 和 Y 的项集数与所有包含 X 的项集数之比。在挖掘关联规则时,关联规则必须要满足最小支持度和最小置信度这两种阈值,如果关联规则既满足大于等于最小置信度,还大于等于最小支持度则称之为强关联规则,反之则不是,通常我们所说的都是强关联规则。
.............................
2.2 相关技术
2.2.1 Python 及其开发平台
Python 不仅是一种高级的程序设计语言,也是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言,所以 Python 也包含了脚本语言所有的特点。同时它还是一种成熟稳定的计算机通用性开发语言[24]。
相比低级语言来说,设计具有很强的可读性,清晰的语法结构,编写 Python 程序耗时更少、程序更短,更容易保证程序的正确性,因此也被称为可执行的伪代码。作为高级语言,Python 简单易学、易于阅读、易于维护、可扩展、可嵌入、可移植,同样的程序可以在不同类型的系统上运行,无需修改即可在在 Linux、Windows、FreeBSD 等20 多个系统上运行,也可以将 Python 程序嵌入到 C/C++程序中去。
2.2 相关技术
2.2.1 Python 及其开发平台
Python 不仅是一种高级的程序设计语言,也是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言,所以 Python 也包含了脚本语言所有的特点。同时它还是一种成熟稳定的计算机通用性开发语言[24]。
相比低级语言来说,设计具有很强的可读性,清晰的语法结构,编写 Python 程序耗时更少、程序更短,更容易保证程序的正确性,因此也被称为可执行的伪代码。作为高级语言,Python 简单易学、易于阅读、易于维护、可扩展、可嵌入、可移植,同样的程序可以在不同类型的系统上运行,无需修改即可在在 Linux、Windows、FreeBSD 等20 多个系统上运行,也可以将 Python 程序嵌入到 C/C++程序中去。
Python 不仅拥有丰富的类库,还包含了诸如列表、集合等许多高级的数据结构[24],我们可以花费较少的时间、用很少的代码来实现想要的功能,从而可以将更多的时间用于系统的功能设计以及数据处理等问题上。使用 Python 语言开发的程序在运行时不如Java 和 C 语言的运行效率高[25],但是在一些对效率要求比较高的系统中,可以通过Python 调用 C 编译的代码以解决自身性能不足的问题。本文在选择开发语言时最看重的也是 Python 语言丰富的类库,相对成熟的框架,在数据分析和数据挖掘方面有比较专业和全面的模块。
Python 语言中丰富的类库使得 Python 在数据挖掘和数据分析方面具有很大的优势,在本系统中选用 Python 开发语言主要也是因为 Python 强大的第三方库,其中主要使用以下几个类库。
...................................
3 系统需求分析...........................................15
3.1 功能性需求分析....................................15
3.2 非功能性需求....................................17
3.3 本章小结.........................................18
4 系统设计..............................................20
4.1 开发环境介绍......................................20
4.2 系统架构设计......................................20
5 系统实现与测试.....................................29
5.1 数据获取模块实现......................................29
5.2 数据导入模块实现.........................................32
5 系统实现与测试
5.1 数据获取模块实现
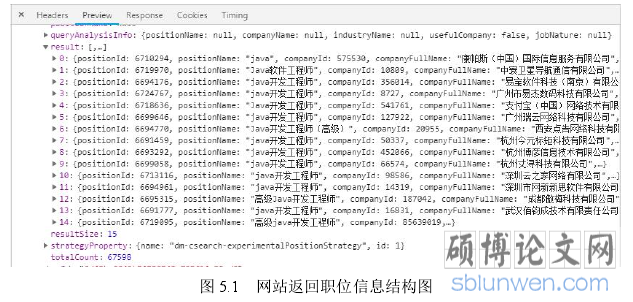
数据获取模块主要是从拉勾网职位信息页以及职位详情页面获取相关的招聘数据。首先观察网站,点击翻页发现页面的 url 没有发生变化,然后点击 F12 进入开发者工具的 Network 选项,点击翻页观察页面的 url 发生变化,得到访问页面的 url(https://www.lagou.com/jobs/positionAjax.jsonhy=%E7%A7%BB%E5%8A%A8%E4%BA%92%E8%81%94%E7%BD%91&px=default&needAddtionalResult=false)以及所需参数 first: true、pn,pn 即为页数,由此可以在程序中以变量的形式定义页数,动态构造页面访问的 url抓取信息。通过观察还可以得到,请求职位信息的 url 是以 json 串的形式返回结果信息的,在返回信息中的 totalCount 字段表示信息的总条数,pageSize 字段表示每页有多少条信息,由此可以用 totalCount/pageSize 来作为爬虫程序的终止条件。在返回的页面信息中,result 字段代表当前页面的所有职位信息,包括职位 id:positionId、职位名称:positionName、学历:education、工作经验:workYear、薪资水平:salary、公司规模:companySize、工作城市:city 等信息。如下图 5.1 所示:
数据获取模块主要是从拉勾网职位信息页以及职位详情页面获取相关的招聘数据。首先观察网站,点击翻页发现页面的 url 没有发生变化,然后点击 F12 进入开发者工具的 Network 选项,点击翻页观察页面的 url 发生变化,得到访问页面的 url(https://www.lagou.com/jobs/positionAjax.jsonhy=%E7%A7%BB%E5%8A%A8%E4%BA%92%E8%81%94%E7%BD%91&px=default&needAddtionalResult=false)以及所需参数 first: true、pn,pn 即为页数,由此可以在程序中以变量的形式定义页数,动态构造页面访问的 url抓取信息。通过观察还可以得到,请求职位信息的 url 是以 json 串的形式返回结果信息的,在返回信息中的 totalCount 字段表示信息的总条数,pageSize 字段表示每页有多少条信息,由此可以用 totalCount/pageSize 来作为爬虫程序的终止条件。在返回的页面信息中,result 字段代表当前页面的所有职位信息,包括职位 id:positionId、职位名称:positionName、学历:education、工作经验:workYear、薪资水平:salary、公司规模:companySize、工作城市:city 等信息。如下图 5.1 所示:
..............................
6 总结与展望
6.1 总结
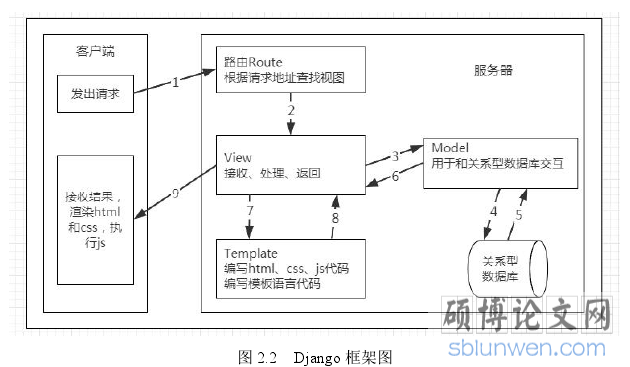
随着网络招聘方式的兴起以及互联网技术的成熟,网络招聘平台已经是人们在求职就业时的主要选择方式。况且现在是一个大数据的时代,数据分析的目的就是把隐藏在一大批看起来杂乱无章的数据中找出所研究对象的内在规律。本文的主要工作就是针对拉勾网获取其招聘过程中产生的大量的数据,设计并实现一个网络招聘数据的可视化分析系统,为众多的求职者以及每年的就业大军提供一个清晰、明了的招聘现状。本网络招聘数据分析系统主要使用 Python 开发语言,以及 Python 的开发平台 Pycharm,并使用 Python 的 Web 开发框架 Django,采用其 MTV 的开发模式完成了系统的各模块的功能实现。本文主要完成的具体工作如下:
(1)本文首先详细阐述了论文的研究背景、目的及意义,查阅了大量相关的文献,了解了目前网络招聘及数据分析的国内外研究现状,并介绍了本文的主要研究内容及组织架构。
6.1 总结
随着网络招聘方式的兴起以及互联网技术的成熟,网络招聘平台已经是人们在求职就业时的主要选择方式。况且现在是一个大数据的时代,数据分析的目的就是把隐藏在一大批看起来杂乱无章的数据中找出所研究对象的内在规律。本文的主要工作就是针对拉勾网获取其招聘过程中产生的大量的数据,设计并实现一个网络招聘数据的可视化分析系统,为众多的求职者以及每年的就业大军提供一个清晰、明了的招聘现状。本网络招聘数据分析系统主要使用 Python 开发语言,以及 Python 的开发平台 Pycharm,并使用 Python 的 Web 开发框架 Django,采用其 MTV 的开发模式完成了系统的各模块的功能实现。本文主要完成的具体工作如下:
(1)本文首先详细阐述了论文的研究背景、目的及意义,查阅了大量相关的文献,了解了目前网络招聘及数据分析的国内外研究现状,并介绍了本文的主要研究内容及组织架构。
(2)研究并学习了完成本系统所需要的相关的理论知识以及完成开发工作所需要的相关技术,像数据挖掘、关联分析、中文分词以及网络爬虫、Python 语言和 Django框架等等,并对这些基础理论知识和技术做了相关的介绍。
(3)在研究了相关理论基础之后,从实际出发,对系统进行了详细的需求分析,包括系统的功能性需求以及非功能性需求。最终确定系统主要包括数据获取、数据导入、数据处理、数据分析以及数据可视化展示五大功能模块,并对每个模块的具体功能进行了详细的描述。
(3)在研究了相关理论基础之后,从实际出发,对系统进行了详细的需求分析,包括系统的功能性需求以及非功能性需求。最终确定系统主要包括数据获取、数据导入、数据处理、数据分析以及数据可视化展示五大功能模块,并对每个模块的具体功能进行了详细的描述。
(4)对系统进行详细的设计,包括系统的架构设计以及各个功能模块的详细设计,并绘制了系统各个功能模块详细的流程图。
(5)结合当前系统的应用场景,研究并学习 k-means 聚类算法、TextRank 算法以及 Apriori 算法的原理和实现,为下一步系统的功能实现打下基础.
参考文献(略)
参考文献(略)