一、文本和数据挖掘(TDM)的原理及其著作权法律关系分析
(一) 文本和数据挖掘(TDM)的概念和特征
1.概念
(1)“数据挖掘”(Date Mining)
对“数据”的传统理解是计算或者实验得出的结果,实际上数字、文字、符号、图片、声音等都属于数据。将这些数据以二进制的形式转化存储在计算机介质中时就成为计算机语言中的“数据”,而数据库就是将庞大的、具有一定共性的数据存储在计算机内的集合体。大数据时代背景下被热议的“数据”更多是转化后具有计算机结构特点的符号。这个时代,数据是爆炸式增长的,而对数据的利用无论在分析技术上还是商业价值发现上都存在滞后。为了应对“数据雄厚信息匮乏”的现状,许多大数据处理架构方案被提出来。有学者将数据形象地比喻为丰富的矿床,而对数据的整理、分析利用好比对矿床的挖掘作业,因此,数据挖掘一词便被普遍使用为一种新型的数据处理技术。
简言之,数据挖掘又叫数据库中的知识发现(Knowledge Discovery Database),泛指从大量数据中挖掘出隐含的、先前未知但潜在的有用的信息和模式的一个工程化和系统化的过程。①具体而言,数据挖掘是一种决策支持过程,它主要基于人工智能、机器学习、模式识别、统计学、数据库等,高度自动化地分析数据,挖掘出隐含在其中的、人们事先不知道的、但又是有用的、新颖的、有效的信息和知识的过程,帮助决策者做出正确的决策。②可见,数据挖掘是一项复杂的又极其专业的计算机技术,它将数据从最基础的查询应用上升到知识的提取,提供决策的支持,开拓出数据最大的价值。
..........................
(二)文本和数据挖掘(TDM)的主要流程
全套的文本和数据挖掘是一个复杂且专业性高的操作,本文将简化涉及的众多计算机领域的专业技术和分析手段,将整个过程大致分为以下步骤:
第一环节为文本与数据源获取阶段。数据源的获取是整个流程的基础,也是开启整个过程的准备工作。该阶段的主要任务为收集与研究主题相关的文本和数据,这些内容可能从外部获取也可能是研究者内部资源,可能是受到著作权保护的作品或享有一定权利的数据库亦或是没有任何权利限制的公有领域内容。研究者往往会将收集到的对象内容存储在自己的服务器或者本地计算机中,这一过程势必会涉及对相关内容的复制。特别是将文集作为挖掘对象时,不可避免的会将文章内容部分甚至全文拷贝在本地服务器中,该步骤可能会涉及著作权中复制权侵权问题,后文会进一步讨论。
第二环节是样本处理阶段,包括前期预处理和后期的挖掘操作。样本的筛选、归类、规约①以及将数据转换成统一的结构化数据都是预处理阶段着重解决的问题。数据挖掘技术归根结底是一种计算机分析技术,因此技术的顺利开展需要建立在将筛选整理完的数据转化为计算机语言,即统一的结构化符号之上。特别是文本数据大多都是半结构或者无结构化的文本,首先就需要用自然语言处理系统对其进行预处理。后期的挖掘操作是整个过程的核心,主要是利用数据挖掘算法来进行分析,主要有分类算法、聚类算法、关联规则挖掘算法、估计概率模型参数算法等。②专业技术人员根据用户的需求,选择适当的算法对数据进行分析,从而得出隐藏在背后的信息。这中间复杂的技术过程并不是非专业人士所能理解,也不是本文讨论的范畴,因此简单带过。该阶段文本与数据的结构性转换可能会涉及著作权改编权问题,是本文研究的内容。
............................
二、域外将文本和数据挖掘(TDM)视为著作权合理使用的实践
(一)美国:无条件例外模式——典型案例为线索
1.“谷歌图书馆案”确认 TDM 应用属于合理使用
(1)案件简介
谷歌图书项目(Google Books Library project)是谷歌和世界主流图书馆间达成协议,对馆藏的纸质书籍扫描使之数字化,形成可机读的文本并制作相应的索引。通过扫描大量的受版权保护的作品和处于公有领域的作品得到数据集,谷歌公司基于此建立“谷歌图书”搜索引擎。相关用户可以输入自己感兴趣的关键词,通过文本和数据挖掘应用,搜索结果就会呈现该数据库里所有包含该关键词的书籍,以及出现的频率都可获悉。此外,还提供了这些书籍的基本书目信息,用户甚至可以直接阅读包含关键词的一些片段。谷歌公司正是通过类似卡片目录的方式向公众提供书籍信息,确保用户高效又准确的获取自己寻求的作品。然而这个做法遭到了大量作者的不满,美国作家协会、多名作家①先后提起诉讼,认为谷歌公司在未获得他们许可的情况下扫描作品并供用户在谷歌图书馆上搜索浏览片段的行为侵犯了他们的著作权。该案自 2005 年首次提起诉讼,2013 年法院依据美国版权法第 107 条作出不侵权判决, 2015 年美国第二巡回法院认定谷歌图书馆计划构成合理使用,2016 年上诉到联邦最高法院,最终维持原判。至此,10 年的纠纷得以平息,美国也通过判例的方式确认 TDM 行为的合法性。
1.“谷歌图书馆案”确认 TDM 应用属于合理使用
(1)案件简介
谷歌图书项目(Google Books Library project)是谷歌和世界主流图书馆间达成协议,对馆藏的纸质书籍扫描使之数字化,形成可机读的文本并制作相应的索引。通过扫描大量的受版权保护的作品和处于公有领域的作品得到数据集,谷歌公司基于此建立“谷歌图书”搜索引擎。相关用户可以输入自己感兴趣的关键词,通过文本和数据挖掘应用,搜索结果就会呈现该数据库里所有包含该关键词的书籍,以及出现的频率都可获悉。此外,还提供了这些书籍的基本书目信息,用户甚至可以直接阅读包含关键词的一些片段。谷歌公司正是通过类似卡片目录的方式向公众提供书籍信息,确保用户高效又准确的获取自己寻求的作品。然而这个做法遭到了大量作者的不满,美国作家协会、多名作家①先后提起诉讼,认为谷歌公司在未获得他们许可的情况下扫描作品并供用户在谷歌图书馆上搜索浏览片段的行为侵犯了他们的著作权。该案自 2005 年首次提起诉讼,2013 年法院依据美国版权法第 107 条作出不侵权判决, 2015 年美国第二巡回法院认定谷歌图书馆计划构成合理使用,2016 年上诉到联邦最高法院,最终维持原判。至此,10 年的纠纷得以平息,美国也通过判例的方式确认 TDM 行为的合法性。
(2)“四因素”分析
1841 年 Joseph Story 法官在 Folsom v.Marsh 一案中首次提出了合理使用概念,历经长时间司法实践的检验与总结最终在 1976 年形成合理使用四要素并记入到《美国著作权法》第 107 条。谷歌图书馆案判决中法官通过援引 Campbell案②对争议焦点通过四个法定要素进行一一分析。
........................
(二)英国:非商业性目的例外模式
最早出台版权法的英国一直被视为是版权制度的诞生地,而且它与时俱进的版权制度成为诸多国家学习和借鉴的模板。在新技术“文本和数据挖掘”的合法性这个问题上,也是欧洲国家中最早以立法的方式进行明确。2011 年英国学者Hargreaves 在他的研究报告②中就提到因文本和数据挖掘这类新技术在法律设置之出并未被想象到以至于现在的法律在阻碍这些技术的应用。英国法律目前的非商业性研究的版权例外是排除数据库文本挖掘技术的,因此在出现新机会时,法律需要进行适当的调整,政府应引入非商业性研究的文本和数据挖掘行为的例外并建议欧盟层面推广支持文本和数据挖掘的例外情况用于商业用途的分析。
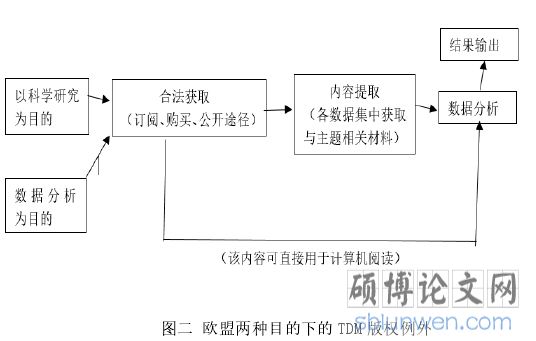
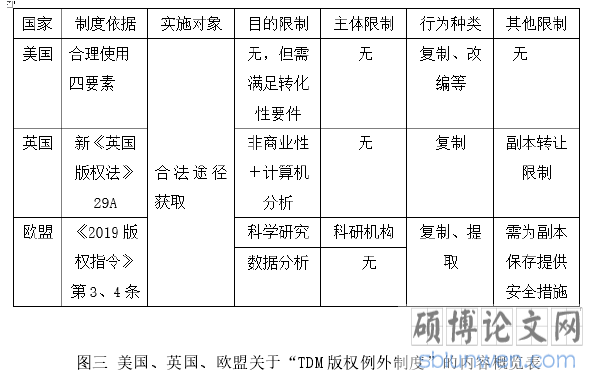
之后英国慢慢开启了修改著作权法的道路,于 2014 年新增了第 29 款“TDM版权例外的条款”,以立法的形式明确了以非商业性研究为目的的文本和数据挖掘属于合理使用。条款概述为:允许研究人员为了非商业性研究的文本和数据挖掘的目的,采用计算机分析技术对已经获得合法访问的任何版权材料制作副本的行为。①从该规定可见,虽英国已经从立法层面赋予了 TDM 技术的合法性,但要获得 TDM 版权侵权的豁免需要同时满足很多限制条件,对适用的主体、使用的目的、豁免的行为以及其他形式要件作出了详细地规定。首先是主体,该条并没有限制主体的种类,涵盖了所有可实施 TDM 的自然人或法人,但他们必须具备合法访问数据库或作品集的资格,包括订阅了期刊、购买了数据库或符合知识共享协议等;在使用的目的上需要满足用于计算机分析和非商业性研究目的两个要件,此限制排除了不以计算机处理数据的行为和具有盈利性质的商业性研究;复杂的TDM 应用过程可能会侵犯多种著作权权利,但 29 条只豁免实现该技术过程不可避免的“复制”行为,对于汇编、翻译等行为并未提及。
1841 年 Joseph Story 法官在 Folsom v.Marsh 一案中首次提出了合理使用概念,历经长时间司法实践的检验与总结最终在 1976 年形成合理使用四要素并记入到《美国著作权法》第 107 条。谷歌图书馆案判决中法官通过援引 Campbell案②对争议焦点通过四个法定要素进行一一分析。
........................
(二)英国:非商业性目的例外模式
最早出台版权法的英国一直被视为是版权制度的诞生地,而且它与时俱进的版权制度成为诸多国家学习和借鉴的模板。在新技术“文本和数据挖掘”的合法性这个问题上,也是欧洲国家中最早以立法的方式进行明确。2011 年英国学者Hargreaves 在他的研究报告②中就提到因文本和数据挖掘这类新技术在法律设置之出并未被想象到以至于现在的法律在阻碍这些技术的应用。英国法律目前的非商业性研究的版权例外是排除数据库文本挖掘技术的,因此在出现新机会时,法律需要进行适当的调整,政府应引入非商业性研究的文本和数据挖掘行为的例外并建议欧盟层面推广支持文本和数据挖掘的例外情况用于商业用途的分析。
之后英国慢慢开启了修改著作权法的道路,于 2014 年新增了第 29 款“TDM版权例外的条款”,以立法的形式明确了以非商业性研究为目的的文本和数据挖掘属于合理使用。条款概述为:允许研究人员为了非商业性研究的文本和数据挖掘的目的,采用计算机分析技术对已经获得合法访问的任何版权材料制作副本的行为。①从该规定可见,虽英国已经从立法层面赋予了 TDM 技术的合法性,但要获得 TDM 版权侵权的豁免需要同时满足很多限制条件,对适用的主体、使用的目的、豁免的行为以及其他形式要件作出了详细地规定。首先是主体,该条并没有限制主体的种类,涵盖了所有可实施 TDM 的自然人或法人,但他们必须具备合法访问数据库或作品集的资格,包括订阅了期刊、购买了数据库或符合知识共享协议等;在使用的目的上需要满足用于计算机分析和非商业性研究目的两个要件,此限制排除了不以计算机处理数据的行为和具有盈利性质的商业性研究;复杂的TDM 应用过程可能会侵犯多种著作权权利,但 29 条只豁免实现该技术过程不可避免的“复制”行为,对于汇编、翻译等行为并未提及。
............................
三、文本和数据挖掘(TDM)的版权例外纳入我国著作权合理使用的必要性及正当性分析 ...............................34
(一)文本和数据挖掘在我国应用中面临多重困境 ....................... 34
1.现行著作权合理使用制度无法为其提供制度支撑 ....................... 34
(1)不符合“为个人学习” .......................................... 34
(2)不符合“教学、科研使用” ...................................... 35
四、文本和数据挖掘(TDM)的版权例外纳入我国著作权合理使用的可行性分析 ...........................44
(一)文本与数据挖掘纳入我国著作权合理使用的路径选择 ............... 44
1.纳入《著作权法(修订草案送审稿)》第 43 条“其他情形” ............. 44
2.单独设置有条件的 TDM 版权例外规则 ................................. 46
四、文本和数据挖掘(TDM)的版权例外纳入我国著作权合理使用的可行性分析
(一)文本与数据挖掘纳入我国著作权合理使用的路径选择
1.纳入《著作权法(修订草案送审稿)》第 43 条“其他情形”
2012 年我国开启了《著作权法》第三次修正的工作,此次修正共形成了三个修正草案的版本,于 2014 年 6 月国务院公布了最终《著作权法(修订草案送审稿)》,向社会广泛征求意见,但该修正到目前为止仍未最终通过。但从送审稿中依旧可以看出我国未来对著作权保护的发展和趋势,在合理使用制度上,第一、二修正版本并没有重大的修改而在第三与送审稿中,第一款增加了第十三项“其他情形”以及将现行《著作权法实施条例》21 条关于“合理使用”一般要件作为第二款的内容。可见此次修订在“合理使用制度”上突破了我国一直以来采用的封闭式列举的模式,增加“其他情形”以及一般判定条件,采纳“列举+一般”方式扩大了“合理使用”的范围。这一修改无疑是一种突破,是立法对技术发展和社会多样性的一种应对,但这样的修改是否符合我国合理使用理论基础以及是否有利于司法实践有待商榷。对于“合理使用一般条款”的设置上送审稿仅仅是吸收了实施条例中原先的规定,即依旧是采用《伯尔尼公约》“三步检验法”来对是否符合“合理使用”进行判定,照搬“不得影响作品的正常使用”以及“不得不合理损害著作权人的利益”再加上“其他情形”,事实上这种方式革命性地将我国原本封闭式的模式转变为完全开放的形式,具有美国判断“合理使用四要素”的影子。本文认为送审稿中这种借鉴美国式合理使用制度的模式并在我国突破使用并不是良好的路径。
........................
结语
文本和数据挖掘技术作为 21 世纪重要的研究工具,在数字化时代科学研究和各个领域中发挥着重要的工具价值。然而在现行著作权框架下,未经许可的文本和数据挖掘的应用的确构成著作权的侵权,也正是如此,现有法律的规定成为该新型技术顺利发展的阻碍。在各国纷纷作出立法调整的当下,将 TDM 纳入我国合理使用制度范畴也具有必要性和正当性,但技术的推广不能以损害权利人的利益为代价,新型合理使用制度适用的主体、目的、行为要素成为构建具体条款考虑的关键,通过这些要素的界定,构建公平、公正且稳定的 TDM 版权例外规则,在不损害权利人正当利益的同时也能促进 TDM 应用的创新和发展。
在我国《著作权法》第三次修正的契机下,早日实现我国对 TDM 合法性的确认具有可行性。本文在借鉴域外典型国家立法实践的基础上并结合时代的要求对我国设立 TDM 版权例外规则采取的模式和限制要素作出界定。明确对作品、数据资源的合法获取是构成“TDM 版权例外”的前提,承认授权许可、期刊订阅、知识共享等多种途径;使用主体上不支持“研究机构”作为唯一主体条件,用取消主体的限制条件来取代,从而保障公民和其他组织、个人的研究自由,让更多主体享受 TDM 技术带来的便利;采用目的限制来避免豁免范围过大的情形,吸收欧盟建立的“以科学研究为目的”的版权例外制度同时承认符合其他合理公益目的行为展开的 TDM。
参考文献(略)