第一章 绪论
1.1 研究工作的背景和意义
随着“互联网+”时代的到来以及计算机技术的不断发展,互联网已经成为了人们生活中的必需品,同时便捷的移动设备的普及也使得人们获得信息变得更加的方便。在这个全民上网的时代,人们正被各种各样的数据以及信息所包围,在这些数据中,以社交媒体为载体的短文本数据显得尤为突出,例如 Twitter、Facebook、微博等著名的社交媒体的用户已经达到数十亿的规模,活跃用户的日常评论以及博文分享导致短文本的数量爆炸式增长,与此同时大量无用或杂乱无章的文本数据也充斥于其中。因此,如何对这些文本数据进行正确有效的知识提取成为了社会发展的焦点之一,也将推动文本相关技术的发展。
早期大多文本挖掘[1-3]方面的工作都是通过人工手段进行信息的提取,这样的做法不仅耗时耗力而且由于人员的知识水平参差不一导致效果往往不能令人满意。因此,迫切需要自动语言理解技术来处理和分析这些文本[4],在这些技术中,文本分类被证明是一种基本的,关键的,在各种场景中都很有用的自然语言处理任务方法,例如在社交情感分析[5]、产品的评论分类[6]、推荐[7]等众多场景中。文本分类又可以具体的被分为长文本分类和短文本分类(Short Text Classification,STC),据有关部门的统计,互联网中的全体文本信息里有 80%以上的文本信息都属于内容较少的短文本信息。
....................
1.2 国内外研究现状
文本分类是自然语言处理中普遍且具有挑战性的任务,其主要因为文字的符号性不能像图片和语音一样进行量化的比较,例如可以把一张图片看成一个矩阵,使用一些距离度量手段便可以比较俩个图片的相似性。文本分类主要可以分为俩个重要的技术:文本表示和分类模型。
文本表示:由 Z.Harris[8]提出的词袋模型(Bag-Of-Words,BOW)是最传统以及常见的文本表示方式,即文本中的词语可被看作为一个无序的集合,就像“用一个袋子来装着这些词语”一样,BOW 的文本表示方式体现了词语间的共现关系却会忽略词语的顺序以及之间的语序关系[9],如果语料的数量过大还会出现维度灾难的问题。BOW 文本表示方式也出现了诸多的变种,例如 One-Hot 和 TF-IDF 等。在 BOW 的基础上,Salton[10]等人提出了向量空间模型(Vector Space Model,VSM),VSM 把文档当做为一个向量,其中每个分量对应着语料中的一个词的词频,值采用 TF-IDF 来计算,当某个词不在语料中,该位置为 0,VSM 主要用于文本检索领域。
文本分类是自然语言处理中普遍且具有挑战性的任务,其主要因为文字的符号性不能像图片和语音一样进行量化的比较,例如可以把一张图片看成一个矩阵,使用一些距离度量手段便可以比较俩个图片的相似性。文本分类主要可以分为俩个重要的技术:文本表示和分类模型。
文本表示:由 Z.Harris[8]提出的词袋模型(Bag-Of-Words,BOW)是最传统以及常见的文本表示方式,即文本中的词语可被看作为一个无序的集合,就像“用一个袋子来装着这些词语”一样,BOW 的文本表示方式体现了词语间的共现关系却会忽略词语的顺序以及之间的语序关系[9],如果语料的数量过大还会出现维度灾难的问题。BOW 文本表示方式也出现了诸多的变种,例如 One-Hot 和 TF-IDF 等。在 BOW 的基础上,Salton[10]等人提出了向量空间模型(Vector Space Model,VSM),VSM 把文档当做为一个向量,其中每个分量对应着语料中的一个词的词频,值采用 TF-IDF 来计算,当某个词不在语料中,该位置为 0,VSM 主要用于文本检索领域。
随着时代的发展,计算机硬件和深度学习技术的进步,为了解决 BOW 和 VSM 文本表示方式稀疏性以及词语间语义无关联的问题,
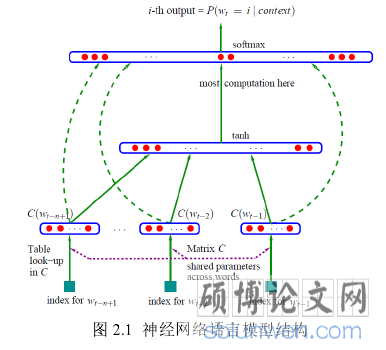
Bengio[11]等人在 2003 年基于分布式假设和神经网络技术提出了神经网络语言模型(Neural Network Language Model,
NNLM),NNLM 是一种无监督的模型可以根据上下文来得到当前词语出现的概率,词语在 NNLM 模型训练的过程在隐藏层的权重即为该词的词向量,这种词向量是低纬度且含有语义信息[12]。基于 NNLM的启发,Mikolov[13]等人提出了 Word2Vec 模型,Word2Vec 模型是一中从原始语料中得到词语分布式表示的无监督模型,其中包含 Skip-Gram 模型和 Continuous Bag-of-Words(CBOW)模型。由于 Word2Vec 模型只是基于词的维度进行语义分析,而并不具有更具单词的排列顺序进行语义分析的能力,Mikolov[14]等人又提出了包含 Distributed Memory(DM)和 Distributed Bag of Words(DBOW)的 Doc2Vec 模型,Doc2Vec 模型,在 Word2Vec 方法的基础上添加了一个段落向量,来记忆词语的排列顺序。
............................
第二章 相关背景知识介绍
2.1 文本数据预处理
无论在社交网络还是在日常生活的短文本语料中,由于每个人的表达方式不同以及乱码或者存在无用的数字、符号以及链接等,需要在进行文本分类任务之前,进行文本的预处理从而去除文本中的噪音和无效的信息,对于不同的任务一般也会有不同的预处理方式,例如在情感分类领域,文中的数字以及特殊符号往往没有很多有用的含义。下面将介绍几种常用的文本预处理方式:
1. 分词。一般来说,对于直接处理一整个句子,往往会选择把句子处理成词汇的集合,这样做可以产生更多的信息,有利于下面任务的进行,所以基本所有的自然语言任务都需要进行分词。对于英文,可以直接按照俩个词之间天然的空格进行分隔。但是由于中文的词语之间没有空格,一般采用 jieba[26]和 pyltp[27]等中文分词工具进行分词。
2.1 文本数据预处理
无论在社交网络还是在日常生活的短文本语料中,由于每个人的表达方式不同以及乱码或者存在无用的数字、符号以及链接等,需要在进行文本分类任务之前,进行文本的预处理从而去除文本中的噪音和无效的信息,对于不同的任务一般也会有不同的预处理方式,例如在情感分类领域,文中的数字以及特殊符号往往没有很多有用的含义。下面将介绍几种常用的文本预处理方式:
1. 分词。一般来说,对于直接处理一整个句子,往往会选择把句子处理成词汇的集合,这样做可以产生更多的信息,有利于下面任务的进行,所以基本所有的自然语言任务都需要进行分词。对于英文,可以直接按照俩个词之间天然的空格进行分隔。但是由于中文的词语之间没有空格,一般采用 jieba[26]和 pyltp[27]等中文分词工具进行分词。
2. 去停用词。对于大多数的文本来说,其中会包含一些无意义的词语,这些词语不仅不会对文本任务的效果带来提升反而会降低分类的准确度,例如英文中的“the”、“he”和“go”等;中文中的“再”、“是”和“又”等。在文本分类的后面步骤之前,一般会去除这些停用词。
3. 删除无用信息。这里的无用信息一般包括,链接、乱码的文字、符号、数字,这些对于任务来说可以看作为噪音需要删除。
4. 词性归一化。词的归一化,有利于规范化语料。在英文中,一个词的复数可以被归一化为单数形式,过去式、进行时可以规划化为现在时。例如“done”和“doing”都会被归一化为“do”。
................................
2.2 文本表示
在经过处理干净的语料后,需要把符号化的文字转换成计算机能看得懂的数字数据,常见的文本表示方式有传统的词袋表示方式以及深度学习中火热的分布式表示方式。下面本文将从这俩方面进行介绍:
2.2.1 词袋表示方式
(1)传统词袋
词袋模型是个广泛应用于自然语言处理以及信息检索的模型,在此模型下,句子或者文件的文字可以用像“一个袋子装着这些词”来表现,词袋模型统计了次出现的频率以及共现性,这些特征可以用来训练分类模型,但是词袋模型并没有考虑词的语义、文法以及出现的顺序,只能被看做成一个简单的词语的集合。
对于如下的俩个文本:
1)Tom plays soccer,Jerry plays soccer too.
2)Tom also watch soccer games.
根据上面俩个文本的单词语料,可以构建如下语料的列表:
[“Tom”,“plays”,“soccer”,“Jerry”,“too”,“also”,“watch”,“games”]
此处的列表长度为 8,即上面的俩个文本都会被长度为 8 的向量所表示,向量的索引位置上的数字代表此句话中该词语在预料对应位置出现的次数:
1)[1,2,2,1,1,0,0,0]
2)[1,0,1,0,0,1,1,1]
..................................
3. 删除无用信息。这里的无用信息一般包括,链接、乱码的文字、符号、数字,这些对于任务来说可以看作为噪音需要删除。
4. 词性归一化。词的归一化,有利于规范化语料。在英文中,一个词的复数可以被归一化为单数形式,过去式、进行时可以规划化为现在时。例如“done”和“doing”都会被归一化为“do”。
................................
2.2 文本表示
在经过处理干净的语料后,需要把符号化的文字转换成计算机能看得懂的数字数据,常见的文本表示方式有传统的词袋表示方式以及深度学习中火热的分布式表示方式。下面本文将从这俩方面进行介绍:
2.2.1 词袋表示方式
(1)传统词袋
词袋模型是个广泛应用于自然语言处理以及信息检索的模型,在此模型下,句子或者文件的文字可以用像“一个袋子装着这些词”来表现,词袋模型统计了次出现的频率以及共现性,这些特征可以用来训练分类模型,但是词袋模型并没有考虑词的语义、文法以及出现的顺序,只能被看做成一个简单的词语的集合。
对于如下的俩个文本:
1)Tom plays soccer,Jerry plays soccer too.
2)Tom also watch soccer games.
根据上面俩个文本的单词语料,可以构建如下语料的列表:
[“Tom”,“plays”,“soccer”,“Jerry”,“too”,“also”,“watch”,“games”]
此处的列表长度为 8,即上面的俩个文本都会被长度为 8 的向量所表示,向量的索引位置上的数字代表此句话中该词语在预料对应位置出现的次数:
1)[1,2,2,1,1,0,0,0]
2)[1,0,1,0,0,1,1,1]
从以上的例子不难发现,词袋模型只是简单的统计了词频和共现信息,是个简单的模型,只适合语料较少的传统的机器学习任务。
..................................
第三章 基于记忆信息和泛化信息的短文本分类方法 ....................................... 24
3.1 引言 ................................ 24
3.2 记忆信息和泛化信息 ................................... 24
第四章 GM-CNN 模型优化技术 .................................. 28
4.1 引言 ........................................ 28
4.2 批标准化 ......................................... 28
第五章 实验与结果分析 ........................................ 35
5.1 引言 ............................. 35
5.2 实验数据 .............................. 35
第五章 实验与结果分析
5.1 引言
通过对第三章和第四章的阐述,本文通过对记忆信息和泛化信息的融合使用提出了GM-CNN 模型架构,然后针对 M-CNN 模型架构中存在的问题提出了 IGM-CNN 模型架构。在本章内,本文将通过具体搭建深度学习环节在三个不同的短文本数据集上进行实验,实验的目的主要是为了解决如下几个问题。
1. 与现阶段以及传统的短文本分类基准模型比较,
5.1 引言
通过对第三章和第四章的阐述,本文通过对记忆信息和泛化信息的融合使用提出了GM-CNN 模型架构,然后针对 M-CNN 模型架构中存在的问题提出了 IGM-CNN 模型架构。在本章内,本文将通过具体搭建深度学习环节在三个不同的短文本数据集上进行实验,实验的目的主要是为了解决如下几个问题。
1. 与现阶段以及传统的短文本分类基准模型比较,
GM-CNN 的短文本分类效果是否有提高。
2. 与 GM-CNN 的短文本分类效果相比,改进过的 IGM-CNN 模型短文本分类效果是否有提高。
3. Chunk-Max Pooling 的分段数(Chunk)取多少的时候,可以保证既降低了 MInput 的稀疏性,同时又还能保证模型文本分类效果的良好。

.....................
2. 与 GM-CNN 的短文本分类效果相比,改进过的 IGM-CNN 模型短文本分类效果是否有提高。
3. Chunk-Max Pooling 的分段数(Chunk)取多少的时候,可以保证既降低了 MInput 的稀疏性,同时又还能保证模型文本分类效果的良好。
.....................
第六章 总结与展望
6.1 总结
本文主要是对基于泛化信息和记忆信息的短文本分类方法的研究。其主要的研究工作如下所示:
1. 说明了研究工作的背景和意义,因为随着网联网的普及,文本数据与日俱增,对文本的进行自动化分类有着重大的意义。对国内外文本分类发展的现状进行了调研,经调研发现,文本分类从早期的词袋表示加特征选择和机器学习的模式转换成分布式表示加深度学习的模式,但是其中对短文本信息利用的不足从而引出了本文使用泛化信息和记忆信息进行短文本分类研究的工作。
6.1 总结
本文主要是对基于泛化信息和记忆信息的短文本分类方法的研究。其主要的研究工作如下所示:
1. 说明了研究工作的背景和意义,因为随着网联网的普及,文本数据与日俱增,对文本的进行自动化分类有着重大的意义。对国内外文本分类发展的现状进行了调研,经调研发现,文本分类从早期的词袋表示加特征选择和机器学习的模式转换成分布式表示加深度学习的模式,但是其中对短文本信息利用的不足从而引出了本文使用泛化信息和记忆信息进行短文本分类研究的工作。
2. 对文本分类相关的技术进行了简要的介绍,包括文本的预处理、词袋表示法和分布式表示方法、传统和当前的一些分类器模型以及分类任务效果常见的评价指标。
3. 说明了泛化信息和记忆信息的出现的初衷以及其为何可以用在文本分类上,即泛化信息整体信息的优点和泛化信息局部而相关性的优点。对泛化信息和记忆信息的具体文本表述进行了介绍和具体实现,然后在对 TextCNN 模型上进行优化从而使得可以集成泛化信息和记忆信息,提出本文的 GM-CNN 模型。
4. 分析 GM-CNN 的 ICS 和记忆信息高纬稀疏的问题,通过引进批正则技术和 Chunk-Max Pooling 技术解决了这俩个问题,并基于这俩个改进提出了 IGM-CNN 模型.
5. 通过实验具体比较了 GM-CNN 和基准模型的效果,以及 IGM-CNN 模型和 GM-CNN模型是否有提升,最后对 Chunk-Max Pooling 的 Chunk 尺寸进行了实验,从而可以在保证分类效果的前提下降低模型的复杂度。
参考文献(略)
3. 说明了泛化信息和记忆信息的出现的初衷以及其为何可以用在文本分类上,即泛化信息整体信息的优点和泛化信息局部而相关性的优点。对泛化信息和记忆信息的具体文本表述进行了介绍和具体实现,然后在对 TextCNN 模型上进行优化从而使得可以集成泛化信息和记忆信息,提出本文的 GM-CNN 模型。
4. 分析 GM-CNN 的 ICS 和记忆信息高纬稀疏的问题,通过引进批正则技术和 Chunk-Max Pooling 技术解决了这俩个问题,并基于这俩个改进提出了 IGM-CNN 模型.
5. 通过实验具体比较了 GM-CNN 和基准模型的效果,以及 IGM-CNN 模型和 GM-CNN模型是否有提升,最后对 Chunk-Max Pooling 的 Chunk 尺寸进行了实验,从而可以在保证分类效果的前提下降低模型的复杂度。
参考文献(略)