第一章 绪论
1.1 课题背景和意义
为适应当今科技的发展,人工智能已经成为现在研究的一个热门课题。早在 2011 年,美国IBM 公司的 watson 参加了 Jeopardy 电视智能问答大赛,连续击败数名顶级人类高手,2016 年,轰动一时的人机围棋大战中 AlphaGo 以 4:1 战胜世界围棋冠军李世石,Microsoft 的智能聊天机器人“小冰”,开始掀起一股人工智能的热潮。得益于人工智能的飞速发展,计算机视觉慢慢的出现在人们的视野里,并广泛的应用在生活与工作中。
计算机视觉系统是人工智能系统里一个重要的研究分支。图像语义分割任务是计算机视觉领域最重要也是最具有挑战性的研究方向,也是理解图像信息的重要一环。图像语义分割是对输入图像的每个像素所属的类别进行识别和分类。它融合了图像分割和目标识别两种任务,不像图像分类那样判断一张图像是什么,除了要判断出图像中有些什么物体,还要判断出图像中每个物体的位置在哪,让图像变得更有意义,在人脸识别、无人驾驶汽车、智能家居机器人等很多领域具有广泛的应用价值。
当前,图像语义分割技术是应用到无人驾驶领域的一个重要研究内容。针对无人驾驶而言,近年来,国内的汽车数量不断增长,驾驶员出现酒驾、疲劳驾驶等问题越来越频繁,因此对无人驾驶技术的需求变得更加迫切。随着深度学习技术的日益不断成熟,可以使用视觉传感器来感知周围环境,整体流程是将车载摄像头或者其它传感器能够实时的捕获周边的街道场景,将获取的图像输入到训练好的模型当中,后台计算机对输入的信息进行识别和分析,自动对整幅图片进行分类,汽车根据分类结果进行自动避障。基于深度学习的图像语义分割算法兴起于 2015 年,是一个较新和发展极快的研究内容,其效果相比较于传统的算法已经有了很大的提升,但是,想将其广泛应用到工业层面,仍会存在很多问题,例如分割精度、运算时间、模型大小等都是目前图像语义分割技术研究所需解决的巨大挑战。
..........................
1.2 国内外研究现状
1.2.1 传统的图像语义分割
传统的语义分割方法主要采用机器学习算法,主要包含基于阈值的分割方法、基于边缘检测的分割方法、基于区域的分割方法和结合特定理论的分割方法。
(1)基于阈值的分割方法
阈值分割方法是以像素集合作为划分的标准。确定一个阈值 T,将大于阈值 T 和小于 T 的像素分开。它主要包括全局阈值、局部阈值和最佳阈值这几大类方法。全局阈值法通过设定一个固定的阈值。局部阈值法是在不同区域选择不同的阈值。最佳阈值是根据具体问题来确定最佳阈值。阈值的选择包括最大相关性原理[1]、基于图像拓扑稳定状态[2]、基于模糊测度[3]、基于最大类间方差法[4]。
(2)基于边缘检测的分割方法
边缘检测是指多个不同区域之间交界处像素点的集合,在不同区域的边界上,像素的灰度值变化比较剧烈,这是图像局部区域不连续的体现。比较常用的边缘检测法包括以下两种方法:第一种是以 Robert 算子和 Sobel 算子[5]为代表的一阶微分算子,此方法是把灰度的变化作为寻找梯度的比周年,再通过梯度方向找到一阶导数的最大值;第二种是以 Laplacian 算子和 Canny 算子[6]为代表的二阶微分算子,通过计算图像灰度二阶导数的过零点来确定边界。
(3)基于区域分割的分割方法
1.2 国内外研究现状
1.2.1 传统的图像语义分割
传统的语义分割方法主要采用机器学习算法,主要包含基于阈值的分割方法、基于边缘检测的分割方法、基于区域的分割方法和结合特定理论的分割方法。
(1)基于阈值的分割方法
阈值分割方法是以像素集合作为划分的标准。确定一个阈值 T,将大于阈值 T 和小于 T 的像素分开。它主要包括全局阈值、局部阈值和最佳阈值这几大类方法。全局阈值法通过设定一个固定的阈值。局部阈值法是在不同区域选择不同的阈值。最佳阈值是根据具体问题来确定最佳阈值。阈值的选择包括最大相关性原理[1]、基于图像拓扑稳定状态[2]、基于模糊测度[3]、基于最大类间方差法[4]。
(2)基于边缘检测的分割方法
边缘检测是指多个不同区域之间交界处像素点的集合,在不同区域的边界上,像素的灰度值变化比较剧烈,这是图像局部区域不连续的体现。比较常用的边缘检测法包括以下两种方法:第一种是以 Robert 算子和 Sobel 算子[5]为代表的一阶微分算子,此方法是把灰度的变化作为寻找梯度的比周年,再通过梯度方向找到一阶导数的最大值;第二种是以 Laplacian 算子和 Canny 算子[6]为代表的二阶微分算子,通过计算图像灰度二阶导数的过零点来确定边界。
(3)基于区域分割的分割方法
区域分割是把某一块具有相似性像素的区域分割成一块。它主要有两种基本分割方法:第一种是区域生长法[7],从单个像素出发,逐步合并以形成所需的分割区域;第二种是分裂合并法[8],它跟区域生长相反,是先将整张图片不断分裂得到各个子区域,然后再把前景区域合并。
...........................

2.2 深度卷积神经网络
早期,用传统神经网络解决计算机视觉任务时,由于其结构的缺陷,不能构建较深层的网络。因此提出了卷积神经网络,其精度也远超传统算法和传统神经网络。卷积神经网络和传统神经网络的区别如图 2-2 所示。
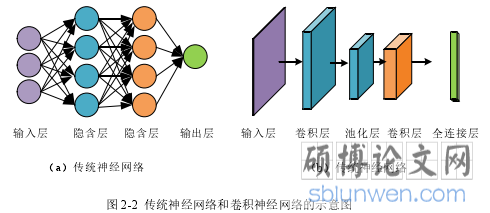
图 2-2 中(a)是传统的神经网络,由输入层、激活函数、全连接等部分组成。图 2-2 中(b)是卷积神经网络,由输入层、卷积层、激活函数、池化层、全连接等部分组成。卷积神经网络凭借强大的特征提取能力,能学习到很多之前传统神经网络学不到的抽象特征。卷积神经网络的成功源于局部连接和权值共享。下面先讲卷积神经网络的基本概念,然后再将卷积神经网络的基本机构组建。
..............................
第二章 相关理论与技术框架
2.1 图像语义分割
2.1.1 问题描述
图像是由许多像素组成的,图像语义分割顾名思义就是将像素按照图像中所表达语义含义的不同进行分割。如图 2-1 所示
2.1 图像语义分割
2.1.1 问题描述
图像是由许多像素组成的,图像语义分割顾名思义就是将像素按照图像中所表达语义含义的不同进行分割。如图 2-1 所示
例如图 2-1 中(a3)是 PASCAL VOC 数据集中一个人骑自行车的图片,计算机经过判断后应该能够生成图 b3,红色是人,绿色是自行车,黑色是背景色。
..................................
2.2 深度卷积神经网络
早期,用传统神经网络解决计算机视觉任务时,由于其结构的缺陷,不能构建较深层的网络。因此提出了卷积神经网络,其精度也远超传统算法和传统神经网络。卷积神经网络和传统神经网络的区别如图 2-2 所示。
图 2-2 中(a)是传统的神经网络,由输入层、激活函数、全连接等部分组成。图 2-2 中(b)是卷积神经网络,由输入层、卷积层、激活函数、池化层、全连接等部分组成。卷积神经网络凭借强大的特征提取能力,能学习到很多之前传统神经网络学不到的抽象特征。卷积神经网络的成功源于局部连接和权值共享。下面先讲卷积神经网络的基本概念,然后再将卷积神经网络的基本机构组建。
..............................
3.1 DeepLabv3+ ............................ 22
3.2 网络总体结构 .........................24
3.3 编码器 .................................25
第四章 实验系统设计与实现 ......................... 45
4.1 系统功能需求 ..............................45
4.2 系统总体架构设计 .........................................46
4.3 系统功能模块设计与实现.............................46
第五章 总结与展望 .............................. 5
5.1 工作总结 ...............................51
5.2 未来展望 ................52
第四章 实验系统设计与实现
4.1 系统功能需求
伴随着深度学习的发展,图像语义分割技术应用到无人驾驶领域日趋成熟。相比于传统的图像语义分割效率低、精度差等缺点,基于深度学习的图像语义分割在分割精度、分割效率、内存占用等方面得到了很大的提升。
本系统的实现目的就是结合本文全新设计的图像语义分割网络结构,实现一个深度卷积神经网络的图像语义分割系统。为满足用户需求,实现以下几个系统功能:
(1)加载模型功能:保存和加载已有模型可以为用户节省大量时间,用户只需点击上传图片,就可直接进行对图片的分割。
(2)分割结果可视化功能:图像语义分割系统对用户上传的图片进行分割,并对分割结果的展示。
.........................
第五章 总结与展望
5.1 工作总结
图像语义分割任务是计算机视觉研究中的重要分支,在深度学习兴起后得到巨大的发展,基于深度学习的图像语义分割的精度得到了很大的提升。本文基于 DeepLabv3+算法,提出了基于编解码结构的 DeepLab-IRNet 图像语义分割改进算法。主要研究内容包括:
(1)通过对基于编解码的图像语义分割算法进行研究,本文在 Deeplabv3+模型的基础上提出了基于编解码结构的 DeepLab-IRNet 图像语义分割改进算法。在 1/16 分辨率下的特征图引入特征图切分模块,提高模型对小目标物体的关注。使用 CamVid 数据集,验证了本文方法的有效性。
(2)本文对训练数据集采取数据增广技巧,该方法增强了训练模型的泛化能力。
(3)在编码器阶段,主要由深度残差网络、特征图切分模块、特征提取网络、空洞空间金字塔池化模块组成。深度残差网络使得模型能够训练得更深同时还能保证良好的性能,它由普通卷积层和多个倒置残差模块串联组成,倒置残差模块中使用深度可分离卷积代替普通卷积,能大大减少模型的参数量,并当特征图的分辨率下降到输入图片的 1/16 大小时,在最后个倒置残差模块中引入空洞卷积,空洞卷积能提高卷积核对特征图的感受野。在 1/16 分辨率下的特征图中引入特征图切分模块,提高模型对小目标物体的关注。多尺度特征提取网络能够提高模型对放大后的目标物特征的提取能力,将输出的特征图与解码阶段放大到相同尺寸的特征图进行融合,提升最终的分割精度。在空间金字塔池化模块引入了深度可分离卷积,大大减少了模型的参数量,提高了网络的训练速度。
(4)解码器阶段,本文采用双线性插值法进行上采样,将编码器中所提取的特征恢复到输入图片尺寸的大小,输出最终图像语义分割图。
(5)针对无人驾驶领域,本文设计了一个图像语义分割系统,使用 CamVid 数据集来验证本文算法的有效性。
参考文献(略)