第一章 绪论
1.1 课题背景及研究意义
通信技术的发展为移动终端的应用开发带来新的机遇,人们对手机的依赖不再局限于即时通信服务,各类移动端的应用程序(Application,app)应运而生,以新闻 app 为代表的社会媒体应用广受用户欢迎。
最早一批的新闻应用以“搜狐新闻”、“网易新闻”和“新浪新闻”为主,这一阶段的网站对新闻进行无差别推送,即任何新闻之间无差别对待,均被推送到用户端,任何用户也被无差别对待,所有用户接收相同的新闻内容。无差别的新闻推送,使用户端接收到的新闻内容过于混杂,于是新闻 app 开始对新闻进行分类推送,即首先按照社会、财经、科技、文化、军事以及体育等不同的属性对新闻进行分类,用户端也建立对应的类别模块,然后各类别下推送对应新闻。
通信技术的发展为移动终端的应用开发带来新的机遇,人们对手机的依赖不再局限于即时通信服务,各类移动端的应用程序(Application,app)应运而生,以新闻 app 为代表的社会媒体应用广受用户欢迎。
最早一批的新闻应用以“搜狐新闻”、“网易新闻”和“新浪新闻”为主,这一阶段的网站对新闻进行无差别推送,即任何新闻之间无差别对待,均被推送到用户端,任何用户也被无差别对待,所有用户接收相同的新闻内容。无差别的新闻推送,使用户端接收到的新闻内容过于混杂,于是新闻 app 开始对新闻进行分类推送,即首先按照社会、财经、科技、文化、军事以及体育等不同的属性对新闻进行分类,用户端也建立对应的类别模块,然后各类别下推送对应新闻。
分类推送使用户接收的新闻信息更有条理,用户可以快速选择自己喜欢的类别进行浏览,这也就催生了“华尔街见闻”、“36 氪”、“即刻快讯”等针对单一行业或领域的新闻 app 的出现。这类新闻 app 仅对指定类型的新闻进行推送,从而使新闻内容更加丰富和专业化。与此同时,新闻数量呈现爆炸式增长,每时每刻都有大量新闻事件产生,这导致新闻 app 难以准确为用户推送其喜欢的新闻内容。个性化新闻推荐技术应运而生,它可以根据浏览历史等信息判断用户所感兴趣的新闻事件或新闻主题,从而将对应的新闻推送给用户。
个性化新闻推荐技术[1]的整体架构主要包括三个部分,一是对用户进行建模,即通过用户行为等相关信息分析用户所感兴趣的新闻事件或主题,二是对新闻进行建模,为相同事件、主题或类型的新闻打标签,三是基于推荐算法为用户推送相应的新闻。其中新闻建模尤为关键,传统的新闻建模是对新闻进行社会、财经、科技等大类属性建模,然而用户关注的内容是每个大类下具体事件对应的新闻,因此基于传统新闻主题建模的个性化新闻推荐技术已难以实现精准的新闻推送,而将新闻按照事件建模则可以有效提高推送质量。新闻事件聚类则是实现新闻事件建模的有效方法,除此之外,新闻事件聚类在舆情监控、信息检索[2]等应用领域也具有重要的意义。
............................
1.2 国内外研究现状
在事件层面进行新闻聚类是一种细粒度的聚类,可以有效提高聚类的精度。事件聚类的重点在于事件的表示和对应聚类方法的研究,传统的文本式事件表示因表示粒度过大、噪音过多逐渐被结构化事件表示等技术取代。机器学习、深度学习、网络表示学习等技术促进了结构化数据聚类的发展,为细粒度的事件聚类带来新的突破,成为国内外高校、研究机构和科技公司的研究热点,并在事件表示和图聚类等方面取得了一定的成果。
1.2.1 事件表示的研究现状
新闻常以标题加正文的半结构化文本形式表示,其内容以文字为主,部分新闻辅以图片、图标、视频等形式增强表现力。事件表示就是要从标题与正文中提取出新闻事件的主要内容并以合适的形式表示,减少原始数据中的冗余信息,且保留与事件本身相关的相对完整的信息,目前关于事件表示的方法主要有:文本式表示、结构化表示和半监督式表示。
(1)文本式事件表示
文本式事件表示法以传统文本表示为基础,是一种将文本表示成矢量的方法。在事件聚类、文本聚类和信息抽取等研究领域具有重要意义。
早期方法以向量空间模型(Vector Space Model, VSM)[13]为理论基础,也称词袋(Bag of Words, BOW)模型[14],将文本内容转化到向量空间中,从而用向量表示文本信息,空间中向量的相似度反映文本的相似度。一种典型的方法是独热表示(One-Hot Representation),将文本中无重复词项(对于中文需要首先进行分词)作为有序字典,以字典长度作为文本向量的长度,其中每一维对应字典中一个词项,如果某个词项在所表示的文本中出现则对应维度为1,否则为 0。
个性化新闻推荐技术[1]的整体架构主要包括三个部分,一是对用户进行建模,即通过用户行为等相关信息分析用户所感兴趣的新闻事件或主题,二是对新闻进行建模,为相同事件、主题或类型的新闻打标签,三是基于推荐算法为用户推送相应的新闻。其中新闻建模尤为关键,传统的新闻建模是对新闻进行社会、财经、科技等大类属性建模,然而用户关注的内容是每个大类下具体事件对应的新闻,因此基于传统新闻主题建模的个性化新闻推荐技术已难以实现精准的新闻推送,而将新闻按照事件建模则可以有效提高推送质量。新闻事件聚类则是实现新闻事件建模的有效方法,除此之外,新闻事件聚类在舆情监控、信息检索[2]等应用领域也具有重要的意义。
............................
1.2 国内外研究现状
在事件层面进行新闻聚类是一种细粒度的聚类,可以有效提高聚类的精度。事件聚类的重点在于事件的表示和对应聚类方法的研究,传统的文本式事件表示因表示粒度过大、噪音过多逐渐被结构化事件表示等技术取代。机器学习、深度学习、网络表示学习等技术促进了结构化数据聚类的发展,为细粒度的事件聚类带来新的突破,成为国内外高校、研究机构和科技公司的研究热点,并在事件表示和图聚类等方面取得了一定的成果。
1.2.1 事件表示的研究现状
新闻常以标题加正文的半结构化文本形式表示,其内容以文字为主,部分新闻辅以图片、图标、视频等形式增强表现力。事件表示就是要从标题与正文中提取出新闻事件的主要内容并以合适的形式表示,减少原始数据中的冗余信息,且保留与事件本身相关的相对完整的信息,目前关于事件表示的方法主要有:文本式表示、结构化表示和半监督式表示。
(1)文本式事件表示
文本式事件表示法以传统文本表示为基础,是一种将文本表示成矢量的方法。在事件聚类、文本聚类和信息抽取等研究领域具有重要意义。
早期方法以向量空间模型(Vector Space Model, VSM)[13]为理论基础,也称词袋(Bag of Words, BOW)模型[14],将文本内容转化到向量空间中,从而用向量表示文本信息,空间中向量的相似度反映文本的相似度。一种典型的方法是独热表示(One-Hot Representation),将文本中无重复词项(对于中文需要首先进行分词)作为有序字典,以字典长度作为文本向量的长度,其中每一维对应字典中一个词项,如果某个词项在所表示的文本中出现则对应维度为1,否则为 0。
独热表示虽然充分保留了文本数据,但是不可避免的丢失了词序、语义和句法等信息,为区别不同词项对文本表示的贡献度需对各维度添加权重。词频-逆文本频率指数(Term Frequency-Inverse Document Frequency, TF-IDF)算法[15]是一种评估词项对语料库中指定文档重要程度的统计方法,其计算包括词频和逆文档频率两部分,词频即词项在指定文档中出现的频率,逆文档频率指包含该词项的文档的数量的倒数,所以如果一个词项在指定文档中出现的频率高,而在其他文档中未出现或很少出现,则 TF-IDF 值就大,表明该词项在对应文本中重要性较高。基于词共现的文档向量表示模型(Co-occurrence Term Based Vector Space Model,CTVSM)[16]从语料库中提取满足一定阈值的共现词项,以共现词项表示的组合语义来提高向量空间模型中语义的关联性,并将共现词项作为词典来得到组合语义在各文本中的分布,即把文本表示为组合词项空间中的向量。
.............................
第二章 新闻事件聚类相关技术
2.1 新闻聚类概述
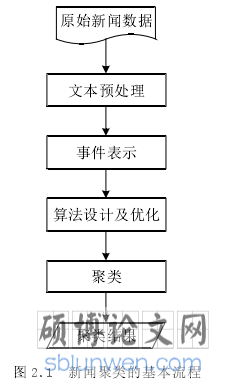
新闻事件聚类是从半结构化或无结构的新闻文本中挖掘相似新闻簇的问题,其中聚类的对象可以是不同的粒度,例如文档、段落、句子或术语,以及本文研究的事件。根据对象所属的簇关系可将聚类分为硬聚类和软聚类,其中硬聚类是指每个新闻对象只能被划分到一个簇中,而软聚类中新闻对象可以被划分到多个簇中,本文中的新闻事件聚类均指硬聚类,即每条新闻只能被划分到一个事件簇中。新闻事件聚类的本质是文本聚类,聚类的目标是将相同的新闻事件划分到相同的簇中。文本聚类作为一项基本的文本分析技术,根据其算法设计的不同,在信息检索、舆情监控、文档摘要等领域具有不同的意义,本文研究的新闻事件聚类算法旨在提高个性化推荐系统的准确率以及用户浏览新闻的效率。由于新闻文本数据的特殊性,其聚类也就比传统文本聚类更加复杂,其基本流程如图 2.1 所示。
...........................
.............................
第二章 新闻事件聚类相关技术
2.1 新闻聚类概述
新闻事件聚类是从半结构化或无结构的新闻文本中挖掘相似新闻簇的问题,其中聚类的对象可以是不同的粒度,例如文档、段落、句子或术语,以及本文研究的事件。根据对象所属的簇关系可将聚类分为硬聚类和软聚类,其中硬聚类是指每个新闻对象只能被划分到一个簇中,而软聚类中新闻对象可以被划分到多个簇中,本文中的新闻事件聚类均指硬聚类,即每条新闻只能被划分到一个事件簇中。新闻事件聚类的本质是文本聚类,聚类的目标是将相同的新闻事件划分到相同的簇中。文本聚类作为一项基本的文本分析技术,根据其算法设计的不同,在信息检索、舆情监控、文档摘要等领域具有不同的意义,本文研究的新闻事件聚类算法旨在提高个性化推荐系统的准确率以及用户浏览新闻的效率。由于新闻文本数据的特殊性,其聚类也就比传统文本聚类更加复杂,其基本流程如图 2.1 所示。
...........................
2.2 预处理技术
2.2.1 中文分词
中文分词是汉语言中特有的文本预处理操作,也是中文文本处理中不可或缺的基础工作,其目的是在文字序列中添加分界符,使之成为一个个单独的词语,因此分词的质量将直接影响后续的词性标注、句法分析等文本分析工作。目前中文分词技术主要包括基于字符串匹配的分词方法和基于统计模型的分词方法两大类。
2.2.1 中文分词
中文分词是汉语言中特有的文本预处理操作,也是中文文本处理中不可或缺的基础工作,其目的是在文字序列中添加分界符,使之成为一个个单独的词语,因此分词的质量将直接影响后续的词性标注、句法分析等文本分析工作。目前中文分词技术主要包括基于字符串匹配的分词方法和基于统计模型的分词方法两大类。
(1)基于字符串匹配的分词方法
基于字符串匹配的分词方法也称基于词典的分词方法,其原理是构造一个足够全面的词典,然后按照一定的策略将文字序列与词典中的词语进行匹配,如果匹配到某个词,则添加一个分隔符,完成一次分词。该方法原理易懂、操作简单且速度较快,是最早被提出的方法,也是应用最广泛的方法。
基于字符串匹配的分词方法也称基于词典的分词方法,其原理是构造一个足够全面的词典,然后按照一定的策略将文字序列与词典中的词语进行匹配,如果匹配到某个词,则添加一个分隔符,完成一次分词。该方法原理易懂、操作简单且速度较快,是最早被提出的方法,也是应用最广泛的方法。
基于字符串匹配的分词方法可以解决百分之七十以上的分词问题,在一般性的文本分析中可以取得相对不错的效果,但是它存在致命的不足——无法解决二义性问题,例如“南京大学生”的正确分词结果应该是“南京/大学生”,而该方法将其切分成“南京/大学/生”,为解决这一问题,一些改进算法被提出,主要算法如表 2.1 所示。

.............................
.............................
3.1 引言 ................................... 24
3.2 相关工作 ..................................... 25
第四章 基于图嵌入的语义关系图聚类算法 ................................................. 44
4.1 引言 ............................. 44
4.2 相关工作 ................................ 45
第五章 新闻事件聚类原型系统 ............................... 57
5.1 引言 ................................... 57
5.2 需求分析 ............................................ 57
第五章 新闻事件聚类原型系统
5.1 引言
新闻事件聚类系统将新闻数据在事件粒度上进行聚类,对杂乱无章的新闻数据进行分类管理,基于新闻聚类的典型的应用有 Hackernews、Techmeme 以及 Readhub 等。其中 Hackernews是一款由英国计算机科学家 Paul Graham 的投资基金和创业孵化器 Y Combinator 运营的新闻社交网站,其关注的主要新闻类型为计算机科学,该网站根据新闻信息的权重进行推送,其权重计算依据包括用户点击以及事件发生的时间,所有用户在 web 端接收的信息是相同的;Techmeme 是美国知名的信息聚合网站,其内容来源包括科技新闻网站和博客,该新闻聚类系统根据新闻和博客内容计算事件的权重,只以一条新闻或博客来概括事件,但是给出相关事件的新闻或博客的链接;Readhub 是由杭州无码科技开发的一个科技类新闻聚类网站,通过从科技类媒体采集新闻并进行聚合与清洗,每个事件会以一条新闻进行概括,同时提供不同媒体关于该事件的新闻链接。
以上这些系统的核心技术均是新闻聚类,且只提供新闻聚类结果的展示,而隐藏了聚类过程中可进行二次开发与扩展的中间环节,因此其只能为最底层的用户提供新闻浏览服务,而对于新闻的二次开发来说,聚类结果只是其中的一项需求,更多的是基于聚类过程的中间环节进行相应的开发与扩展,这也是对新闻事件聚类更充分的利用。因此本文将开发一款包含文本预处理、语义相似度计算、语义关系图构建等聚类中间环节的新闻事件聚类系统,以最大限度的满足用户的需求。
..................................
..................................
第六章 总结与展望
6.1 论文工作总结
随着通信技术的发展以及移动应用的普及,新闻类 app 以及网站数量日益增长,为用户获取新闻提供了快捷的方式,但是新闻数量的激增也为用户的浏览带来了困难,而按照用户感兴趣的新闻事件为其推送则可以大幅提高用户体验,因此对新闻进行事件粒度的聚类在推荐系统、舆情系统中具有重要意义。新闻事件聚类不同于常见的新闻话题分类,其粒度更细,事件表示更复杂,使得新闻聚类具有较大的困难。因此本文主要研究新闻聚类中的事件表示及对应的聚类算法,分别提出了一种基于语义关系图的事件表示算法和基于图嵌入的语义关系图聚类算法,设计并实现了新闻事件聚类原型系统。
6.1 论文工作总结
随着通信技术的发展以及移动应用的普及,新闻类 app 以及网站数量日益增长,为用户获取新闻提供了快捷的方式,但是新闻数量的激增也为用户的浏览带来了困难,而按照用户感兴趣的新闻事件为其推送则可以大幅提高用户体验,因此对新闻进行事件粒度的聚类在推荐系统、舆情系统中具有重要意义。新闻事件聚类不同于常见的新闻话题分类,其粒度更细,事件表示更复杂,使得新闻聚类具有较大的困难。因此本文主要研究新闻聚类中的事件表示及对应的聚类算法,分别提出了一种基于语义关系图的事件表示算法和基于图嵌入的语义关系图聚类算法,设计并实现了新闻事件聚类原型系统。
针对新闻事件表示粒度过大及信息冗余的问题,本文提出一种基于语义关系图的事件表示算法,语义关系图是对新闻事件中语义环境的一种描述,也即对事件信息的表示。首先,对新闻进行句子划分,提取新闻中有效的句子,计算句子间的语义相似度,并将语义相似的句子合并为相同的语义单元;然后,计算语义单元的的权重,提取每条新闻中权重最大的语义单元作为新闻事件的描述;最后,根据语义单元中词项间的语序关联构建语义关系图,得到事件的表示。
针对图聚类需要全局搜索和人工标记等问题,提出一种基于图嵌入的语义关系图聚类算法,图嵌入是将图结构转换成向量的方法,可以有效计算图结构的关联。针对传统图嵌入算法无法捕获高阶信息的问题,提出对图进行采样构建全局子图的方法;针对无法在图嵌入空间中还原簇信息的问题,提出基于伪聚类的结点序列采集算法,使得在图嵌入空间中相同簇的结点间距离更近,而不同簇的结点间距离较远。对语义关系图进行图嵌入后,使用弱聚类算法即可实现结点的聚类。
参考文献(略)
针对图聚类需要全局搜索和人工标记等问题,提出一种基于图嵌入的语义关系图聚类算法,图嵌入是将图结构转换成向量的方法,可以有效计算图结构的关联。针对传统图嵌入算法无法捕获高阶信息的问题,提出对图进行采样构建全局子图的方法;针对无法在图嵌入空间中还原簇信息的问题,提出基于伪聚类的结点序列采集算法,使得在图嵌入空间中相同簇的结点间距离更近,而不同簇的结点间距离较远。对语义关系图进行图嵌入后,使用弱聚类算法即可实现结点的聚类。
参考文献(略)