第一章 绪论
1.1 研究背景及研究意义
随着大数据以及云计算等相关技术的快速发展,传统的数据计算和数据存储方式已经无法满足发展需求,以 Hive、Hbase、Zookeeper 等软件为核心的 Hadoop 生态系统成为解决大数据问题的首选方案,Hadoop 的核心技术是 Map-Reduce 编程框架,Map-Reduce 在计算过程中会将中间数据输出到硬盘存储,在数据迁移过程中容易发生遗漏或错误,还会产生较高的延迟,为此,一个开源性基于内存计算的分布式大数据计算框架——Spark 应运而生,通过扩展早期的 Map-Reduce 编程框架解决了其 I/O 开销过大、容错性差等性能瓶颈,通过基于内存的计算模式,优化了大数据计算中的批处理、交互查询和流式计算等核心问题,并与 Hadoop 及其生态圈完美兼容。
当下,Spark 受限于 CPU 有限的运算效率和内存空间,其应用需求与系统性能间差异日益加大,以 CPU 作为 Spark 的计算平台已无法满足高效运算的需求。而 GPU 较之 CPU 在高性能并行计算领域存在先天性的优势,通过利用 GPU 上的并行计算资源可大力提升 Spark 系统的任务处理效率,解决 CPU 带来的瓶颈问题。
1.1 研究背景及研究意义
随着大数据以及云计算等相关技术的快速发展,传统的数据计算和数据存储方式已经无法满足发展需求,以 Hive、Hbase、Zookeeper 等软件为核心的 Hadoop 生态系统成为解决大数据问题的首选方案,Hadoop 的核心技术是 Map-Reduce 编程框架,Map-Reduce 在计算过程中会将中间数据输出到硬盘存储,在数据迁移过程中容易发生遗漏或错误,还会产生较高的延迟,为此,一个开源性基于内存计算的分布式大数据计算框架——Spark 应运而生,通过扩展早期的 Map-Reduce 编程框架解决了其 I/O 开销过大、容错性差等性能瓶颈,通过基于内存的计算模式,优化了大数据计算中的批处理、交互查询和流式计算等核心问题,并与 Hadoop 及其生态圈完美兼容。
当下,Spark 受限于 CPU 有限的运算效率和内存空间,其应用需求与系统性能间差异日益加大,以 CPU 作为 Spark 的计算平台已无法满足高效运算的需求。而 GPU 较之 CPU 在高性能并行计算领域存在先天性的优势,通过利用 GPU 上的并行计算资源可大力提升 Spark 系统的任务处理效率,解决 CPU 带来的瓶颈问题。
目前,国内外研究人员对 Spark on GPU 课题进行了一系列的讨论和研究,基于 GPU实现对 Spark 计算框架进行建模分析与研究是未来大数据领域的一个重要方向。
1.1.1 Spark
2009 年加州伯克利大学(UC Berkeley) 的 AMP 实验室开发了 Spark 大数据计算框架,于 2010 年将 Spark 提交给 Apache 基金会,使 Spark 作为顶级项目实现了开源,2013 年 Spark 成长为 Apache 旗下在大数据领域最活跃的开源项目之一,2014 年升级为Apache 基金的顶级项目[1]。 Spark 在交互式查询、流计算、图计算等相关信息领域占有十分重要的地位,应用领域非常广泛,概括起来主要有以下几个方面。
2009 年加州伯克利大学(UC Berkeley) 的 AMP 实验室开发了 Spark 大数据计算框架,于 2010 年将 Spark 提交给 Apache 基金会,使 Spark 作为顶级项目实现了开源,2013 年 Spark 成长为 Apache 旗下在大数据领域最活跃的开源项目之一,2014 年升级为Apache 基金的顶级项目[1]。 Spark 在交互式查询、流计算、图计算等相关信息领域占有十分重要的地位,应用领域非常广泛,概括起来主要有以下几个方面。
(1) 快速查询。Spark 基于内存计算,非常有利于快速查询。Spark SQL 的提出更加增强了 Spark 这种优势,Spark 的响应时间短、查询速度快,在数据的快速查询领域得到很好的应用。
(2) 实时推荐。以 Map-Reduce 作为编程框架的推荐系统延迟性很高,而 Spark将小时和天级别的模型训练转变为分钟级,能够对热点分析、个性化推荐进行有效地优化。
...............................
1.2 国内外研究现状
Apache Spark 是一个开源的分布式并行计算框架,采用弹性分布式数据集(RDD)作为内部的数据结构,技术上主要依靠 RDD 血统(Lineage)[6]和检查点机制(Checkpoint)[7]来确保避免 Spark 计算框架系统内部的容错等技术瓶颈。在编程模型方面,主要采用了 Scala 函数式编程语言,在多阶段作业流程跟踪方面做了非常大的简化,更便于计算机的周期性检查机制,以及重新执行任务等复杂工作。在计算模型方面,主要参考了Map-Reduce 来实现 Spark 专属的分布式计算框架体系,参考流处理模型实现了 Spark 流式计算框架 Spark Streaming[8],基于数据仓库实现 Spark SQL 查询系统[9],面向机器学习设计了算法库 MLlib[10],面向图计算领域设计了算法库 Graph X[11]。
2.1 Spark 分布式计算框架概述
2.1.1 Spark 任务执行机制
Spark 任务执行机制中有以下相关概念。
RDD(Resillient Distributed Dataset):弹性分布式数据集。Spark 应用程序通过使用 Spark 的转换 API,可以将 RDD 封装为一系列具有血缘关系的 RDD,也就是 DAG。只有通过 Spark 的动作 API 才会将 RDD 及其 DAG 提交到 DAGScheduler。RDD 的祖先一定是一个跟数据源相关的 RDD,负责从数据源迭代读取数据。
DAG(Directed Acycle Graph):有向无环图。在图论中,如果一个有向图从某个顶点出发经过若干条边无法回到该顶点,则这个图称为有向无环图(DAG 图)。Spark使用 DAG 来反映各 RDD 之间的依赖或血缘关系。
Partition:数据分区,即一个 RDD 的数据可以划分为多少个分区。Spark 根据 Partition的数量来确定 Task 的数量。
NarrowDependency:窄依赖,即子 RDD 依赖于父 RDD 中所有的分区。窄依赖分为一对一和一对多两种。
ShuffleDependency:Shuffle 依赖,也称为宽依赖,即子 RDD 对父 RDD 中的所有分区都可能产生依赖。子 RDD 对父 RDD 各个 Partition 的依赖将取决于分区计算器(Partitioner)的算法。
...............................
1.2 国内外研究现状
Apache Spark 是一个开源的分布式并行计算框架,采用弹性分布式数据集(RDD)作为内部的数据结构,技术上主要依靠 RDD 血统(Lineage)[6]和检查点机制(Checkpoint)[7]来确保避免 Spark 计算框架系统内部的容错等技术瓶颈。在编程模型方面,主要采用了 Scala 函数式编程语言,在多阶段作业流程跟踪方面做了非常大的简化,更便于计算机的周期性检查机制,以及重新执行任务等复杂工作。在计算模型方面,主要参考了Map-Reduce 来实现 Spark 专属的分布式计算框架体系,参考流处理模型实现了 Spark 流式计算框架 Spark Streaming[8],基于数据仓库实现 Spark SQL 查询系统[9],面向机器学习设计了算法库 MLlib[10],面向图计算领域设计了算法库 Graph X[11]。
国内外对 Spark 系统性能优化的研究主要集中在两大方向:一是 Spark 内存计算模型的扩展和完善,二是 Spark 内存计算模型的性能优化。对于前者,这些研究主要包括提出了简单而高效的并行流水线编程模型[12],提出了分析关系型大数据的基本架构[13],提出了图计算的并行化设计方案[14],提出了集群资源的细粒度共享策略[15],提出了差分数据流与响应及时反馈并行的运算模式[16],提出了计算机内存运算框架分布式调度的重要云计算方法[17],实现了高性能的 SQL 查询系统[18],基于 Bit Torrent 实现了内存计算框架的广播通信技术[19],这些重要的研究思路极大地提升了系统的可扩展性。对于后者,其研究成果集中体现在充分利用数据访问的时间、空间局限性上,设计了一种策略,可以提高本地数据访问[20],通过分析并行的任务度会对缓存的有效性产生影响,设计出一种协调缓存算法可以符合内存计算需求[21],针对一些相对较慢的任务节点问题,研究者提出了多种不同的优化方案以供选择,为保障连续执行作业提供了更多的参考[22],通过两种策略(确定性执行、批处理事务),使系统具有良好的可靠性和扩展性 [23]。
.............................
第二章 相关理论基础与技术探讨.............................
2.1 Spark 分布式计算框架概述
2.1.1 Spark 任务执行机制
Spark 任务执行机制中有以下相关概念。
RDD(Resillient Distributed Dataset):弹性分布式数据集。Spark 应用程序通过使用 Spark 的转换 API,可以将 RDD 封装为一系列具有血缘关系的 RDD,也就是 DAG。只有通过 Spark 的动作 API 才会将 RDD 及其 DAG 提交到 DAGScheduler。RDD 的祖先一定是一个跟数据源相关的 RDD,负责从数据源迭代读取数据。
DAG(Directed Acycle Graph):有向无环图。在图论中,如果一个有向图从某个顶点出发经过若干条边无法回到该顶点,则这个图称为有向无环图(DAG 图)。Spark使用 DAG 来反映各 RDD 之间的依赖或血缘关系。
Partition:数据分区,即一个 RDD 的数据可以划分为多少个分区。Spark 根据 Partition的数量来确定 Task 的数量。
NarrowDependency:窄依赖,即子 RDD 依赖于父 RDD 中所有的分区。窄依赖分为一对一和一对多两种。
ShuffleDependency:Shuffle 依赖,也称为宽依赖,即子 RDD 对父 RDD 中的所有分区都可能产生依赖。子 RDD 对父 RDD 各个 Partition 的依赖将取决于分区计算器(Partitioner)的算法。
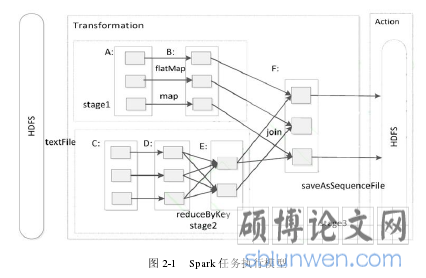
Spark 在应用中,整个执行流程抽象为通用的有向无环图 DAG。Spark 根据 RDD 之间的不同点依赖关系切分成不同的阶段(Stage),其中 Stage1 和 Stage2 由于没有依赖关系是可以并行执行的。图 2-1 描述了一个 Spark 程序,从 HDFS 上读取数据产生 RDD-A 然后 flatmap 操作到 RDD-B,读取另一部分数据到 RDD-C,然后 map 操作到 RDD-D,RDD-D 聚合操作 RDD-E,RDD-B 和 RDD-E 执行 join 操作后得到 RDD-F,这个过程会执行 Shuffle,然后再将结果存储到 HDFS 上。
................................
................................
2.2 Spark+GPU 性能建模相关研究工作
本节首先对基于 GPU 的 Spark 计算框架性能建模前期工作进行调研和详细分析,
本节首先对基于 GPU 的 Spark 计算框架性能建模前期工作进行调研和详细分析,
其次对 CPU-GPU 异构并行系统进行了研究探讨,最后就基于排队论在云计算领域所做的性能建模工作进行了深入思考钻研,对本文的排队论建模工作有了很好的启发。
2.2.1 Spark+GPU 性能建模研究工作
2.2.1 Spark+GPU 性能建模研究工作
目前针对 Spark 的性能建模工作,仅有文献[34]中提出了 Spark Streaming 流式计算系统性能建模。而基于 GPU 的 Spark 计算框架性能建模工作尚属空白。
国内外学术界对于 GPU 通用计算的研究工作基本上集中在对应用程序的开发建设方面,而对 GPU 性能剖析与分析工具的研究相对较少。市面上能够找到的商业程序分析工具也比较少,较为著名的比如 ATI Stream Profiler、NVIDIA Parallel Nsight 等,这些都建立在 GPU 的计算功能模拟器之上的重要程序分析工具,而这些产品均只对程序的运行时间进行统计,却不关注性能的分析。因此,对于 GPU 程序执行过程的建模分析,尚属空白,既没有对 GPU 程序执行过程的精度分析进行充分的研究和探讨,也缺少对GPU 调优相关问题的探索,这为基于 GPU 理论与研究基础去探索 Spark 的建模分析工作提供了较少的线索和参考。本文所探讨和研究的课题——Spark+GPU 性能建模分析,是一个全新的探索性课题,一方面要基于 GPU 广泛被使用的程序分析工具的理论基础和实践经验来探索 Spark 中的 GPU 应用,另一方面还要研究如何使用 GPU 来加速 Spark运行,以一种全新的计算模式来分析和讨论 GPU 与 Spark 两大强势工具“联姻”的成果。因此,目前对基于 GPU 的 Spark 的性能建模研究以及相关方法的讨论也基本上是处于一个初始的研究阶段。
国内外学术界对于 GPU 通用计算的研究工作基本上集中在对应用程序的开发建设方面,而对 GPU 性能剖析与分析工具的研究相对较少。市面上能够找到的商业程序分析工具也比较少,较为著名的比如 ATI Stream Profiler、NVIDIA Parallel Nsight 等,这些都建立在 GPU 的计算功能模拟器之上的重要程序分析工具,而这些产品均只对程序的运行时间进行统计,却不关注性能的分析。因此,对于 GPU 程序执行过程的建模分析,尚属空白,既没有对 GPU 程序执行过程的精度分析进行充分的研究和探讨,也缺少对GPU 调优相关问题的探索,这为基于 GPU 理论与研究基础去探索 Spark 的建模分析工作提供了较少的线索和参考。本文所探讨和研究的课题——Spark+GPU 性能建模分析,是一个全新的探索性课题,一方面要基于 GPU 广泛被使用的程序分析工具的理论基础和实践经验来探索 Spark 中的 GPU 应用,另一方面还要研究如何使用 GPU 来加速 Spark运行,以一种全新的计算模式来分析和讨论 GPU 与 Spark 两大强势工具“联姻”的成果。因此,目前对基于 GPU 的 Spark 的性能建模研究以及相关方法的讨论也基本上是处于一个初始的研究阶段。
随着近年来 Spark 技术的不断推广应用,国内外许多研究学者都在努力探索通过GPU 来加速 Spark 计算,并且取得了较多的突出成果,其中最为典型的两个 Spark+GPU项目就是 cuSpark 和 SparkCL,其中 cuSpark 是将 CUDA 和 Spark 进行结合,借鉴了 Spark中的 RDD 技术,通过 CPU 调控,将数据进行分片,将分片之后的数据存储在主存或显存中,然后通过流水线(Pipeline)进行延长操作的转换函数和计算动作的函数调用。它们将 GPU 成功应用到 Spark 计算中,并且采用了 CPU-GPU 异构并行模式,来优化系统运行。
.............................
.............................
第三章 数学建模理论基础——排队论 ............................... 21
3.1 排队论理论基础 ............................................ 21
3.1.1 排队论基本构成 ..................................... 21
3.1.2 排队系统运行指标 ................................... 23
第四章 基于排队论的 Spark+GPU 性能模型研究 ............................ 27
4.1 Spark+GPU 工作原理 ................................... 27
4.1.1 GPU 加速 Spark 计算的运行机制 ........................... 27
4.1.2 GPU 高性能工作机制 .............................. 28
第五章 非强占有限优先权模型优化与验证 ................................ 39
5.1 模型优化 .......................................... 39
5.1.1 非强占有限优先权 M/M/n/m 模型 ............................... 39
5.1.2 优化模型计算方法 ................................. 40
第五章 非强占有限优先权模型优化与验证
5.1 模型优化
Spark 在提交应用程序到 Worker 节点时,数据会通过 CPU-GPU 异构并行计算系统进行处理,在这过程中,调用内核函数 Kernel 后,CPU 会分配数据块到 GPU 中进行并行计算,而数据块有大有小,因其在传输过程中速度不一样,最后到达 GPU 的顺序也不一样。在已建立的多服务窗混合制排队模型 M/M/n/m 中未考虑数据到达的顺序,对多种应用的数据处理不做区分地遵循先来先服务原则,忽略了实际应用固有的优先级特性。而在实际应用中数据处理是有优先级的,比如生活中的一些场景:信件有普通件和挂号件,快递有一般快递和顺丰快递,医院看病有普通门诊和急诊,普通车让道救护车、消防车等都是优先服务的例子。由此可见,在有优先权排队模型中,顾客是分等级的。因此本文在已建立的 M/M/n/m 排队模型中,加入顾客优先级(数据块大小优先级)来对模型做进一步优化。
Spark 在提交应用程序到 Worker 节点时,数据会通过 CPU-GPU 异构并行计算系统进行处理,在这过程中,调用内核函数 Kernel 后,CPU 会分配数据块到 GPU 中进行并行计算,而数据块有大有小,因其在传输过程中速度不一样,最后到达 GPU 的顺序也不一样。在已建立的多服务窗混合制排队模型 M/M/n/m 中未考虑数据到达的顺序,对多种应用的数据处理不做区分地遵循先来先服务原则,忽略了实际应用固有的优先级特性。而在实际应用中数据处理是有优先级的,比如生活中的一些场景:信件有普通件和挂号件,快递有一般快递和顺丰快递,医院看病有普通门诊和急诊,普通车让道救护车、消防车等都是优先服务的例子。由此可见,在有优先权排队模型中,顾客是分等级的。因此本文在已建立的 M/M/n/m 排队模型中,加入顾客优先级(数据块大小优先级)来对模型做进一步优化。

..............................
第六章 总结与展望
6.1 总结
Apache Spark 是一个有代表性的开源性分布式内存处理系统,其性能优于 Hadoop。通过利用 CPU-GPU 异构并行系统 Spark 性能得到充分的发挥。基于 GPU 的 Spark 计算框架性能分析也是未来大数据领域的一个重要方向。
现有针对 Spark 计算框架性能分析的研究主要集中在采用基于观测的方法,对系统整体或局部组件进行性能监控和结果分析,该性能分析方法对系统的数据动态变化无法做出量化分析。针对这个问题,本文提出了基于排队论的 Spark+GPU 性能建模方法。
本文的研究内容,有以下创新点
(1)针对基于 GPU 的 Spark 计算框架性能建模工作尚属空白,首次采用排队论作为建模工具,构建多服务窗混合制 M/M/n/m 排队模型,结合 GPU 多线程并行特点做出模型假设,得到系统平均排队等待时间计算方法;
(2)CPU 分配给 GPU 的数据块有大有小,数据块到达 GPU 的速度和顺序也不一样,而多服务窗混合制 M/M/n/m 排队模型忽略了数据传输过程中的优先级特性,针对此问题,本文提出了非强占有限优先权 M/M/n/m 模型,通过让高优先级数据优先享受服务机制可减少数据在系统中的平均排队等待时间。
(3)为实现充分合理利用 GPU 资源,基于多服务窗混合制 M/M/n/m 排队模型,通过 Matlab 仿真数据实验,求得最优的 GPU 开启线程数。
(2)CPU 分配给 GPU 的数据块有大有小,数据块到达 GPU 的速度和顺序也不一样,而多服务窗混合制 M/M/n/m 排队模型忽略了数据传输过程中的优先级特性,针对此问题,本文提出了非强占有限优先权 M/M/n/m 模型,通过让高优先级数据优先享受服务机制可减少数据在系统中的平均排队等待时间。
(3)为实现充分合理利用 GPU 资源,基于多服务窗混合制 M/M/n/m 排队模型,通过 Matlab 仿真数据实验,求得最优的 GPU 开启线程数。
参考文献(略)