第 1 章 绪论
1.1 课题背景及研究意义
1.1.1 课题背景
...........................
视觉-语言匹配任务通常分为短语级(匹配输入短语和对应的图片区域), 句子级(匹配输入句子与对应的图片),如图1-1所示,下面我们将分别进行介绍这两种不同级别的匹配任务。
短语级的视觉-语言匹配任务定义为如下形式,给定一系列的图像区域 O ={oi}Ni=1和一个待匹配的短语文本 q,我们希望寻找到语义上最符合 q 的图像区域oi。通常我们有两种方法来解决这个问题,一种是使用 CNN-LSTM 形式的结构[2–5]来为每个短语-图像区域对评分,该评分即 P(q|o),即寻找一个图像区域 o 使得P(q|o) 最大。另外一种方法[6–8] 直接通过构建联合概率 P(q, o) 来给每一个短语-图像对评分,通常直接根据联合概率空间内短语和图像特征的距离 (欧几里得距离或余弦距离) 来进行评分。
句子级的视觉语言匹配通常定义为:给定许多张图片 O = Ij 和一个句子 S,其目的是寻找图片 Ij,使得图片 Ij和句子 S 之间的语言相关性最高。为了解决这个问题,学习模态之间的相关性是一个通常的做法。常用的方法例如典型相关型分析 (CCA)[9], 典型相关型分析试图求取两个集合变量之间的相关性,典型相关分析也是一种经典的学习不同领域特征投影公共空间方程的方法。后来许多工作基于典型相关型分析对其进行了扩展,例如利用核方法来更好地进行非线性投影的Kernel CCA[10]; 利用深度学习来学习投影方程的 Deep CCA[11]。与将文本特征 p 和图片特征 r 投影到共同空间来学习联合概率分布 P(r, p) 所不同的是,Yu 等人[2] 通过对每个图片进行包括类别,方位和关系等多个属性判断,判断最符合属性要求的图片,即建立 p(r|p), 并寻找使其概率值最大的 r。
第 2 章 视觉-语言匹配的相关理论基础
2.1 人工神经网络

..............................
图像或视频的维度通常较高,若采用人工神经网络的方式提取特征(即全部使用全连接层)参数会十分冗杂,针对图片这个特殊的数据形态,卷积神经网络应运而生,并使用局部连接和权值共享等操作,使得模型的规模和参数量大大下降,
2.2.1 模型背景介绍
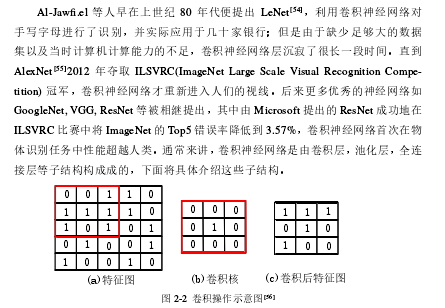
............................
第 3 章 基于层次化奖励反馈的视觉-语言匹配 .......................23
3.1 问题背景介绍 ............................ 24
3.1.1 模型目标在训练和推理时的隔阂 .................................. 24
3.1.2 交叉熵损失处理类别不平衡数据的低效性 ................................... 24
第 4 章 基于知识库的难负样本感知的视觉-语言匹配 ................................45
4.1 问题背景介绍 .................................... 45
4.1.1 难负样本挖掘 ................................... 45
4.1.2 上下文物体的先验知识 .................................... 47
第 5 章 弱监督的开词集句子级视觉-语言匹配 .........................................59
5.1 问题的定义 .............................. 60
5.2 框架总览 ............................. 60
第 5 章 弱监督的开词集句子级视觉-语言匹配
5.1 问题的定义
...........................
结论
随着人机交互的大力推广与发展,单模态的信息已不能满足人们的需求。视觉-语言匹配任务作为这两个模态高级任务的基石,可以促进几乎所有跨视觉-语言模态的任务的发展。视觉-语言匹配与物体检测任务有一定的相似性,但后者类别通常较少且粗略,而前者类别中的短语和句子有近乎无穷的变换,因此该任务对模型的泛化能力提出了更高的要求。
本文首先将论文分为了开词集和闭词集两大部分,其中第三,四章围绕闭词集进行,第五章围绕开词集进行。在第三章,本文分析了交叉熵损失被直接应用于数据标注不完整,样本不均匀的视觉语言匹配任务时的问题,针对这些问题问题,在现有工作的基础上,本文提出了一种层次化奖励函数;针对模型在训练随机采样的不足,第四章本文进一步提出了一种难负样本挖掘策略,并首次将知识库模型应用于监督学习的视觉-语言匹配任务中来提供更丰富的类别信息。第五章本文在现有的基于互联网的开词集框架基础上,通过挖掘高质量图像区域来提高匹配精度,并提出游记配图应用,为了验证该应用性能,我们提出了相关数据集TVN25。
第三章首先我们分析了在物体检测领域表现优异的交叉熵损失被直接应用到视觉-语言匹配任务中的问题:第一,模型目标在训练和推理时存在隔阂;第二,交叉熵损失在类别不平衡数据集上表现较差;第三,由于数据集标注不完整与单短语输入造成的歧义性,将可能与正样本存在较大语义关联的上下文物体视为与背景物体一样的负样本,会造成样本标注错误形式的后果。为缓解这些问题,我们提出了层次化奖励函数,该方法有效主要由于以下几点:第一,训练目标与推理目标相近,减少了模型训练与推理直接的隔阂;第二,通动态学习率,侧面的对数据集正负样本数量进行调整,缓解了正负样本数量不平衡的问题;第三,针对Flickr30K Entities 数据集标注的特殊性,对与目标物体语义相近的负样本较少的惩罚,保留了上下文物体和正样本的语义关系。此外,我们改进了描述性短语定位领域常用的三元组损失函数来引导投影模块产生更有判别力的投影特征,为了防止难负样本引起梯度动荡,我们提出了混淆矩阵来实现由简到难的学习。最后,我们在 Flickr30K Entities 数据集上验证了我们性能的有效性和广泛的适用性。
参考文献(略)