第 1 章 绪论
1.1 课题背景及研究目的和意义
伴随着新技术的发展,软件产品已经在社会中的不同领域发挥着重要的作用。软件行业是国家战略性新兴行业,是社会信息重要的组成部分。国内的众多软件产品的根本目标都是为了服务用户。在软件产品中,数据的重要性是不言而喻的。数据之于软件就像发动机之于汽车一样,数据是软件的驱动器。无论是软件的本身构成还是推荐信息都需要以数据为载体。数字信息化背景下,数据的重要性,价值性在企业与个人的意识中日益凸显,网络资源共享问题作为研究对象在网络研究领域的出现率日益升高[1]。信息的定义是什么,如何高效的对信息进行存储、处理、传输和利用。存在众多的科学工程问题需要围绕信息进行研究[2]。在互联网技术迅速发展的大环境下,信息化时代已然到来,网络信息化时代之下,人类社会的改变正悄然而生。
目前,产品名称的提取与产品的个性化推荐只是针对于电商网站。在知识经济时代,互联网的作用与影响不言而喻,而构成这张巨大知识信息网络的正是数以百万计的网页。电子商务网站的构成也离不了这些网页。电商在市场这一激烈的竞争漩涡中,其商品的价格,设计,服务及质量都将进一步决定自身用户品牌忠诚度[4]。在电子商务网站上,检索产品信息是十分方便的,许多研究者在电子商务网站上产品名称识别与产品的个性化推荐提出了好的思路。但电子商务网站主要特点是买卖关系,卖方提供商品信息,买方则根据这些信息来购买自己所需要的商品。这就决定了电子商务网站的局限性。买方只能根据卖方提供的商品信息进行选择,如果卖方没有发布商品消息,则商品的信息是缺失的。通常发布的商品信息都是通过中间商发布的,买方无法得知商品的直接供应商和生成厂商。这就造成了商品信息缺失的现象。在个性化推荐方面,传统的协同过滤算法缺点是依赖于用户评分矩阵。如果该矩阵数据比较稀疏,则用户相似度计算的不准确。同时,增加新用户和新项目会造成冷启动问题。
......................
3.1 同花顺网站的介绍及产品大类的抽取.......................... 171.1 课题背景及研究目的和意义
伴随着新技术的发展,软件产品已经在社会中的不同领域发挥着重要的作用。软件行业是国家战略性新兴行业,是社会信息重要的组成部分。国内的众多软件产品的根本目标都是为了服务用户。在软件产品中,数据的重要性是不言而喻的。数据之于软件就像发动机之于汽车一样,数据是软件的驱动器。无论是软件的本身构成还是推荐信息都需要以数据为载体。数字信息化背景下,数据的重要性,价值性在企业与个人的意识中日益凸显,网络资源共享问题作为研究对象在网络研究领域的出现率日益升高[1]。信息的定义是什么,如何高效的对信息进行存储、处理、传输和利用。存在众多的科学工程问题需要围绕信息进行研究[2]。在互联网技术迅速发展的大环境下,信息化时代已然到来,网络信息化时代之下,人类社会的改变正悄然而生。
目前,产品名称的提取与产品的个性化推荐只是针对于电商网站。在知识经济时代,互联网的作用与影响不言而喻,而构成这张巨大知识信息网络的正是数以百万计的网页。电子商务网站的构成也离不了这些网页。电商在市场这一激烈的竞争漩涡中,其商品的价格,设计,服务及质量都将进一步决定自身用户品牌忠诚度[4]。在电子商务网站上,检索产品信息是十分方便的,许多研究者在电子商务网站上产品名称识别与产品的个性化推荐提出了好的思路。但电子商务网站主要特点是买卖关系,卖方提供商品信息,买方则根据这些信息来购买自己所需要的商品。这就决定了电子商务网站的局限性。买方只能根据卖方提供的商品信息进行选择,如果卖方没有发布商品消息,则商品的信息是缺失的。通常发布的商品信息都是通过中间商发布的,买方无法得知商品的直接供应商和生成厂商。这就造成了商品信息缺失的现象。在个性化推荐方面,传统的协同过滤算法缺点是依赖于用户评分矩阵。如果该矩阵数据比较稀疏,则用户相似度计算的不准确。同时,增加新用户和新项目会造成冷启动问题。
......................
1.2 国内外研究现状
1.2.1 自然语言处理概念
与计算机的交流无障碍是人们理想化的选择,语言作为描述人类思维的工具将人类语言和计算机结合,这使人类离梦想更进一步[6]。NLP(Natural LanguageProcessing,自然语言处理)作为一门研究人类语言与计算机语言交融性的学科在物联网智能领域作用突出[7]。NLP 是大数据和数据挖掘的基础技术之一,文本形式是目前为止网络上的信息的存储方式之一。自然语言处理技术就是为了能让计算机自动化,像人的大脑一样理解、识别、翻译这些文本信息。在计算机领域,NLP 就是研究如何让计算机理解甚至生成人类的语言,从而实现计算机和人类互相平等的沟通交流。
现如今,自然语言处理存在一种广泛的定义:其被定义为如何使人类与计算机在人机交互过程中高效地进行通信的理论知识与科学手段[8]。NLP 基础技术有:分词、词性标注、词法分析、句法分析、语义分析、命名实体识别,以及信息抽取领域的实体关系抽取等。其中命名实体识别技术就在文本中识别出具体的名实体,例如:人名、地名、机构名等。自然语言处理研究逐渐从词汇语义成分的具体意思理解转化为有词语组成的句子或描述事件的理解。我们通常所说的自然语言理解,是一个完全的智能识别过程,真正的使计算机理解人类的语言,并且像人类一样互相交流。最终使计算机有人的智慧,类似于人的大脑一样。文本挖掘,信息提取,人机交互等方向对信息的需求增长迅速,自然语言处理给我们生活带来的影响,必定会是积极地,不可替代的[9]。本文主要用到自然语言处理技术中的命名实体识别技术和信息抽取。
命名实体识别主要包括人名、地名、机构名、专有名词等,其含义是某些特定含义的实体在文本中的识别[11]。通常包括:(1)实体边界识别;(2)确定实体类别。命名实体识别被广泛应用在自然语言处理领域,是信息抽取的重要的一步。命名实体识别的方法大多由特定的领域文本特定所决定,在特定的多种领域上命名实体识别已经取得了较好的识别效果[12]。在本课题中,抽取企业特定的产品大类本文所采用的命名实体识别技术为条件随机场,自己构建 A 股上市企业产品的语料库,专门针对企业年报中出现的产品大类进行识别。
................................
第 2 章 相关技术研究
1.2.1 自然语言处理概念
与计算机的交流无障碍是人们理想化的选择,语言作为描述人类思维的工具将人类语言和计算机结合,这使人类离梦想更进一步[6]。NLP(Natural LanguageProcessing,自然语言处理)作为一门研究人类语言与计算机语言交融性的学科在物联网智能领域作用突出[7]。NLP 是大数据和数据挖掘的基础技术之一,文本形式是目前为止网络上的信息的存储方式之一。自然语言处理技术就是为了能让计算机自动化,像人的大脑一样理解、识别、翻译这些文本信息。在计算机领域,NLP 就是研究如何让计算机理解甚至生成人类的语言,从而实现计算机和人类互相平等的沟通交流。
现如今,自然语言处理存在一种广泛的定义:其被定义为如何使人类与计算机在人机交互过程中高效地进行通信的理论知识与科学手段[8]。NLP 基础技术有:分词、词性标注、词法分析、句法分析、语义分析、命名实体识别,以及信息抽取领域的实体关系抽取等。其中命名实体识别技术就在文本中识别出具体的名实体,例如:人名、地名、机构名等。自然语言处理研究逐渐从词汇语义成分的具体意思理解转化为有词语组成的句子或描述事件的理解。我们通常所说的自然语言理解,是一个完全的智能识别过程,真正的使计算机理解人类的语言,并且像人类一样互相交流。最终使计算机有人的智慧,类似于人的大脑一样。文本挖掘,信息提取,人机交互等方向对信息的需求增长迅速,自然语言处理给我们生活带来的影响,必定会是积极地,不可替代的[9]。本文主要用到自然语言处理技术中的命名实体识别技术和信息抽取。
命名实体识别主要包括人名、地名、机构名、专有名词等,其含义是某些特定含义的实体在文本中的识别[11]。通常包括:(1)实体边界识别;(2)确定实体类别。命名实体识别被广泛应用在自然语言处理领域,是信息抽取的重要的一步。命名实体识别的方法大多由特定的领域文本特定所决定,在特定的多种领域上命名实体识别已经取得了较好的识别效果[12]。在本课题中,抽取企业特定的产品大类本文所采用的命名实体识别技术为条件随机场,自己构建 A 股上市企业产品的语料库,专门针对企业年报中出现的产品大类进行识别。
................................
第 2 章 相关技术研究
2.1 产品名称识别相关技术
产品名称的识别也属于命名实体识别的一部分。产品名称识别作为命名实体识别的基础任务,在一定程度上也会影响自然语言处理任务、情感分析和知识挖掘等模块[29]。但由于产品名称不同于传统的命名实体如:人名、地名、机构名等,它有着自己独特的特点。一般产品名称的定义都比较随意,往往是根据厂家自己的喜好来命名的。同时,不同领域的产品名称差距很大,这就加大了产品名称识别的难度。目前产品名称的识别的研究还有待提高。
产品名称的识别也属于命名实体识别的一部分。产品名称识别作为命名实体识别的基础任务,在一定程度上也会影响自然语言处理任务、情感分析和知识挖掘等模块[29]。但由于产品名称不同于传统的命名实体如:人名、地名、机构名等,它有着自己独特的特点。一般产品名称的定义都比较随意,往往是根据厂家自己的喜好来命名的。同时,不同领域的产品名称差距很大,这就加大了产品名称识别的难度。目前产品名称的识别的研究还有待提高。
2.1.1 命名实体识别
命名实体识别(named entity recognition,NER)是自然语言处理中的一项重要技术。其目的是识别出文本信息中表示命名实体的部分,并对该实体部分进行分类。因此,有时也称为命名实体识别和分类(named entity recognition andclassification,NERC)[30]。目前,传统的命名识别和深度学习的方法这两种方法是命名实体识别的重要技术组成。其中,基于规则和统计机器学习的方法组成了传统的命名识别[31]。采用模式匹配的方式进行命名实体识别是基于规则的命名实体识别的方法之一。基于统计机器学习的方法采用训练模型的方法,让机器学习模型来识别命名实体,统计机器学习的方法通常有最大熵模型[32]、隐马尔可夫模型[33]、条件随机场[34]等。随着深度学习理论的不断创新,这几年基于深度学习的方法识别命名实体也得到不断的发展。
命名实体识别的过程一般有两个判断标准:(1)实体边界确定是否正确;(2)实体类型是否标准正确[35]。两个判断标准缺一不可。通常的识别错误包括边界确定错误、实体类型判断错误、边界及实体类型均判断错误。由于每天都会出现新的命名实体,所有不能把所有的命名实体存在一个词典中;由于一个单词往往会对应不同的命名实体,比如:中山,这个词有可能是人名的组成部分,同时这个词也有可能是地名的组合部分;由于不同领域的专业词语的差距,所以对于不同领域的命名实体识别往往方法是不同的。所以说命名实体识别是一个比较困难的事情,有很多难点需要攻破.
.........................
.........................
2.2 网页信息抽取相关技术
2.2.1 信息抽取
信息抽取的任务是从大量数据中准确、快速地获取目标信息,提高信息的利用率[44]。从文本信息中获取用户所需的信息,并且结构化的将数据展示出来。信息抽取的抽取对象并不只仅仅只针对文本,其他形式存在的信息也是信息抽取的对象,而抽取的结果则变为统一的、结构化数据[45]。信息抽取是为了解决在信息爆炸的时代下,怎样从海量的信息中快速的找到用户自己所需要的信息。信息抽取所研究的对象主要有:结构化文本、自由文本、半结构化文本。
2.2.2 web 信息抽取
Web 信息抽取是信息抽取的技术的一个重要的分支,web 的本意是网的意思,在网页设计中成为网页。web 信息抽取是将互联网上的网页作为信息来源的一类抽取。网页主题信息的快速高效的获取,使得 web 信息抽取成为信息领域的研究热点[46]。文本理解是 web 信息抽取的前身,开始于 20 世纪 60 年代中期。文本理解的主要目的是从文本中获取结构化信息,是信息抽取技术的初始研究内容[47]。web 信息抽取与普通的文本抽取不同,web 信息都是根据一定的模板编写的。web 信息抽取的核心是根据用户的需求在网页上抽取特定的信息。抽取过程一般分为预处理网页阶段、信息模式描述要抽取的目的信息、对文本进行分析、识别信息、进行上下文推理、对输出进行优化。
2.2.1 信息抽取
信息抽取的任务是从大量数据中准确、快速地获取目标信息,提高信息的利用率[44]。从文本信息中获取用户所需的信息,并且结构化的将数据展示出来。信息抽取的抽取对象并不只仅仅只针对文本,其他形式存在的信息也是信息抽取的对象,而抽取的结果则变为统一的、结构化数据[45]。信息抽取是为了解决在信息爆炸的时代下,怎样从海量的信息中快速的找到用户自己所需要的信息。信息抽取所研究的对象主要有:结构化文本、自由文本、半结构化文本。
2.2.2 web 信息抽取
Web 信息抽取是信息抽取的技术的一个重要的分支,web 的本意是网的意思,在网页设计中成为网页。web 信息抽取是将互联网上的网页作为信息来源的一类抽取。网页主题信息的快速高效的获取,使得 web 信息抽取成为信息领域的研究热点[46]。文本理解是 web 信息抽取的前身,开始于 20 世纪 60 年代中期。文本理解的主要目的是从文本中获取结构化信息,是信息抽取技术的初始研究内容[47]。web 信息抽取与普通的文本抽取不同,web 信息都是根据一定的模板编写的。web 信息抽取的核心是根据用户的需求在网页上抽取特定的信息。抽取过程一般分为预处理网页阶段、信息模式描述要抽取的目的信息、对文本进行分析、识别信息、进行上下文推理、对输出进行优化。
web 是由一个个网页组成的,不同的网页往往结构差距很大。信息与文本信息不同,网页中的信息不仅包括主题信息而且还包括许多噪音。例如:导航行和广告等信息。由于噪音信息的存在这就加大了 web 抽取的难度,不能用一种特定的模板就能识别对 web 信息的抽取。也不可能要求所有的 web 设计者都按照统一设计模式来进行网页的设计。目前能满足所有的 web 页面的抽取过程和方法的技术还不存在。但是由于 web 信息是海量的,将这些数据按照一定的方法提取出来还是非常有必要的。web 信息的抽取技术一般可分为:基于模块的、基于统计理论的、基于视觉特征的、基于 DOM 树等几种技术手段。
............................
............................
第 3 章产品信息提取.................................. 15
3.1.1 同花顺简介............................... 17
3.1.2 同花顺网站上企业产品类别的获取.............................. 17
第 4 章数据分析与个性化推荐................................. 33
4.1 产品信息的分析与补充................................. 34
4.1.1 产品信息的过滤.......................................... 34
4.1.2 产品信息的补充和分级.......................... 35
第 5 章总结与展望........................... 47
5.1 总结................................ 47
5.2 展望............................. 48
第 4 章 数据分析与个性化推荐
4.1 产品信息的分析与补充
该模块主要是分析公司产品信息,过滤上一章提取出来的错误信息。并按照第三章所定义的产品大类、具体产品名称将产品分为两个类别。比如:牵引车动力 WP12 开头的牵引车动力就是产品的大类。并且补充产品图片简介等信息。
4.1.1 产品信息的过滤
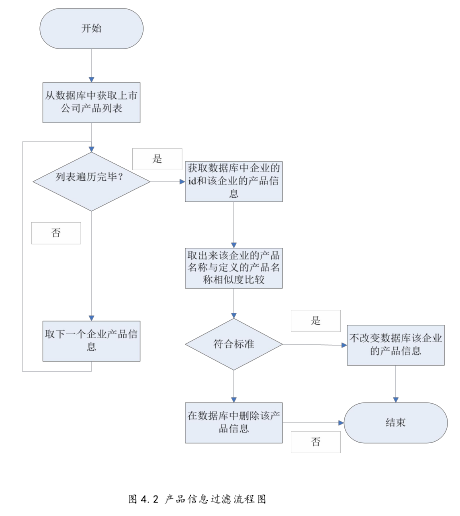
由于第三章提取产品信息存在抽取率问题,会导致抽取到错误的信息即不是产品信息的内容。本节主要是删除无用的信息。具体流程如下图 4.2:
............................
第 5 章 总结与展望
5.1 总结
本文采用的信息提取方法、数据分析方法和个性化推荐方法能够完整的解决用户可以根据自己的喜好个性化的搭配不同企业的产品的问题,这不仅是解决汽车零部件领域的 A 股上市公司急需解决的问题。更重要的是为其他领域有相似需求的用户提供了可行、有效的个性化推荐产品的完整方案和方法。本文的主要工作集中体现在以下几点:
(1)提取上市公司年度报告中的产品类别。公司产品类别信息主要出现在公司年度报告中的营运收入、公司的业务概要模块。营运收入模块的产品类别信息金融网站上(同花顺)已经列出。公司业务概要模块的产品类别信息获取方法:首先定位到本公司描述产品的句子,然后根据句子进行 CRF 识别产品类别。
(2)验证并修改公司年度报告中提取产品类别。我们定义上市公司官网上的产品名称及产品类别是规范的。根据公司年度报告中提取出来的产品类别去公司官网上验证产品类别是否正确,对于不规范的产品类别用公司官网上的产品类别名称替换。
(3)补充上市公司官网上的产品类别。对于从上市公司年报中提取的产品信息不全的情况,我们需要从上市公司官网中补充产品信息。得到公司的全部产品类别。
(4)根据得到产品类别找到具体的产品。
(5)分析抽取出来的产品,根据分析后的数据搭建平台,供用户浏览产品信息。
(6)在传统的协同过滤算法基础上,增加了基于用户的信任和产品的偏好的方法进行个性化推荐产品。
参考文献(略)