第一章 绪论
1.1 研究背景及意义
卷积神经网络是深度学习中最具有代表性的一种模型[1],典型的卷积神经网络通过层级结构来提取不同层次的特征。传统的机器学习是依据人的先验知识来构造特征,而卷积神经网络可以自动提取出具有丰富表达能力的特征,在图像分类[2],目标检测[3]以及图像分割[4]等任务中取得了显著的成果。深度卷积神经网络的应用主要分为训练和推理两个阶段。网络在训练过程中需要利用大量的标记样本进行有监督的学习,训练完成的网络模型可以在训练样本上获得较高的识别准确率。网络的推理过程就是把新的样本输入到训练完成的模型,经过前向传播计算得到输出结果。
为了增强模型的特征提取能力,卷积神经网络在结构设计上主要呈现从深度和宽度两个方面不断扩展的趋势[5]。增加网络的深度是一种常见的提高模型性能的方式,更深的网络可以获取到更加丰富的特征,并且在各种任务中都可以表现出良好的泛化能力。但加深模型的同时,也会出现梯度消失的现象,增加卷积神经网络训练的难度。Resnet[6]通过跨层连接的方式很好的解决了这个问题,该方法可以减少网络逐层连接造成的信息损失,并将卷积神经网络的层数增加到成百甚至上千层,显著提高了模型精度,但是其计算复杂度也越来越大。除了扩展深度,增加模型的宽度也是一种常用的优化方式,通过增加模型的宽度,网络在特征提取方面可以获取更多细节,同时也增强了数据表达能力。Gpipe[7]网络中以增大模型宽度的方式,在 ImageNet 数据集上取得了较大的准确率提升。
......................
1.2 国内外研究现状
1.2.1 深度卷积神经网络的并行化研究现状
训练卷积神经网络是一个耗时的过程,由于硬件设备计算能力不断进步,以及各种深度学习软件框架如 Caffe、Tensorfolw、Mxnet、CNTK、Theano[8-12]等的发展,深度卷积神经网络的训练速度大幅度提升。数据并行与模型并行[13]是两种常用的加速深度卷积神经网络训练的手段。模型并行是将网络模型分解,并将分解之后的模型分发到不同的计算设备上。这种方法适用于模型较大但计算设备内存不够的情况,如 AlexNet[14]将模型平分为两个部分放到两个 GPU 上进行训练,在解决内存不足问题的同时也提升了计算速度,这是 2012 年最早的并行化方法。数据并行则是将训练数据集进行划分,将划分之后的数据集分发到各个设备上进行训练,每个子网络的权值更新通过参数服务器来进行交互[15]。
使用高性能的计算设备是加速卷积神经网络的常用方法。文献[16]使用了 256 块 GPU,在一个小时内完成了 ImageNet 数据集的训练。在计算设备的支持下,将一个批次的数据个数提高到了 8192,并提出了一个学习率缩放的准则,既保证了模型的精度不会损失,又可以充分利用丰富的计算资源,减少神经网络的训练时间。文献[17]使用包含 16000 个 CPU 核的并行计算平台训练了超过 10 亿个神经元的深度神经网络,在语音识别和图像识别等领域取得了突破性的进展。文献[18]在谷歌的支持下使用 1000 台 CPU 服务器完成了模型并行和数据并行的深度神经网络训练,其优势在于利用大规模分布式计算集群的强大计算能力达到快速训练深层模型的目的。文献[19]使用 OpenCL并行编程语言在 FPGA 上实现了 VGGNet 和 AlexNet,通过数据重新排列的方式将卷积操作变换为矩阵乘法,最终提高了网络的吞吐量。文献[20]使用 OpenCL 在 FPGA 上加速了卷积神经网络算法,并且通过增加数据重用和减少片外存储访问需求来优化内存访问,提高了网络的性能。
................................
第二章 卷积神经网络及流水线简介
2.1 深度卷积神经网络
卷积神经网络是一种典型的深度神经网络结构,引入了局部感受野的结构,使得网络权值能够共享,相较于传统的全连接神经网络结构,可以大大降低网络结构复杂度以及自由参数个数,主要在视频图像处理和语音识别领域具有很高的识别效果。卷积神经网络的基本结构由输入层、卷积层、池化层、全连接层以及输出层构成。
卷积层和池化层一般会取若干个,采用卷积层和池化层交替设置,即一个卷积层连接一个池化层,池化层后再连接一个卷积层,依此类推。卷积操作是卷积神经网络中的核心操作,也是在整个算法执行过程中,最为耗时的操作。卷积层通过卷积核从输入特征图中提取诸如边缘、角和交叉的各种特征,然后将他们组合到更抽象的输出特征图中。每个特征图的特征具有三个维度:长、宽和通道数。随着 GPU 等硬件的发展,一次卷积可以处理多张图像,因此将一定数量的图像组成一个批次输入网络,此时每个特征图被组织成四维数组,分别为批次、通道数、长和宽。
在卷积神经网络发展的过程中,出现了许多经典的模型架构,并且呈现出越来越深的趋势。AlexNet[14]是一种经典的卷积神经网络结构,该模型一共分为 8 层,其中有 5 个卷积层以及 3 个全连接层,并把卷积神经网络分为两个部分,在双 GPU 上进行训练。VGGNet[43]网络使用了 3x3 和 1x1 的卷积核,并将网络层数堆叠到 16 层~19 层,提升了网络的泛化能力。2014年谷歌研发团队设计了 22 层的 GoogLeNet[44]采用了网中网的思想,将网络中的基本结构单元变为子网络,进一步提高了网络的表现能力。2015 年微软亚洲研究院的何凯明等人[6]提出了152 层的深度残差网络 ResNet,而最新改进后的 Resnet 网络深度可达到 1202 层,这种网络基于残差学习的思想引入了跨层的捷径连接,有助于增强信息在不同网络层之间的流动,缓解深度模型训练中的过拟合问题,将卷积神经网络的层数带到了一个新的高度。
.............................
2.2 并行计算简介
2.2.1 并行与并行计算
一般来讲,并行性是指可以同时进行的操作,并行处理即同时完成两种或两种以上性质相同或性质不同的工作。注意,这里的“同时”具有两重含义:同一时刻与并发。在并行处理系统中,我们主要是通过利用多个功能部件或多个处理机同时工作来提高机器的运行速度和可靠性。并行计算是指同时使用多种计算资源解决计算问题的过程,实现并行的方法主要有时间重叠、资源重复和资源共享三种。多核技术的出现,为实现资源重复的方法提供了硬件支持,编程人员可以在同一时刻使用计算资源中包含的多个计算核,这为提高程序运行速度提供了一个良好的解决方案。对于解决某个科学问题,编程人员可以将复杂问题分解为多个简单的问题,然后将这些问题分别交给多个处理器进行计算,处理器之间也可以进行相互协作通信,最终求出正确的结果,以快速解决大型且复杂的计算问题。在并行计算中,数据的相关性和线程之间的同步性是两个需要处理的关键问题。
2.2.2 相关性
在设计并行程序时,程序员经常会遇到数据相关性问题,数据相关是由于执行当前指令需要前面指令的执行结果引起的相关。如果在多核操作系统中运行多线程程序,那么多个指令可能在同一时间发生,这会令数据的访问顺序变得不确定。当有多个并发执行单元(同时访问同一块内存,并且这些访问中至少有一个是写操作的时候,就会出现数据竞争[46]。此时,读出的数据不一定就是前一次写操作的数据,而写入的数据也可能并不是程序所需要的,那么结果将是不可预知的[47]。数据相关性给并行程序设计带来了一定的困难,因此在程序中使用并行语句时,要处理好数据竞争的问题。
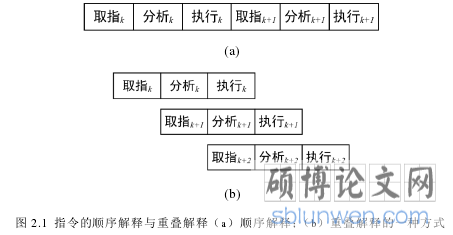
第三章 基于软件流水的卷积神经网络前向传播并行化方法................................. 13
3.1 卷积神经网络前向传播简介 ......................................... 13
3.1.1 单个神经元 ......................................... 13
3.1.2 多层前馈神经网络 ................................ 14
第四章 基于软件流水的卷积神经网络并行化训练方法......................... 22
4.1 基于软件流水的卷积神经网络反向传播算法............................. 22
4.1.1 卷积神经网络反向传播算法 ................................. 22
4.1.2 基于软件流水的卷积神经网络反向传播算法主要思想........................... 24
第五章 基于改进 Focal Loss 损失函数的卷积神经网络................................ 33
5.1 Focal Loss 简介............................ 33
5.2 基于 Sigmoid 改进的 Focal Loss 函数 ....................... 35
第五章 基于改进 Focal Loss 损失函数的卷积神经网络
5.1 Focal Loss 简介
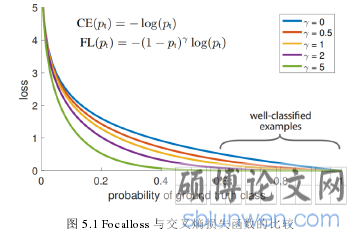
Focal Loss 损失函数最初是在目标检测任务提出的,目标检测主要有两种主流框架,一阶段检测器和两阶段检测器。一级检测器结构简单,执行速度快,但是准确率却远远比不上二级检测器,其主要原因在于前景和背景这两个类别在样本数量上存在很大的不平衡。为了解决这种不平衡,文献[50]改进了交叉熵损失,提出了 Focal Loss。这种损失函数可以对容易分类的样本产生抑制作用,使得损失集中在数量较少的难分类样本上。
一般来讲,对一个容易识别的样本进行分类,会得到很高的置信度。例如,若预测物体为负样本的概率为 98%,则在预测正确的情况下会产生一个较小的损失,但是如果训练过程中正负样本存在极大的不平衡,大量容易分类的样本所产生的损失会远远超过少量难以分类的样本产生的损失,从而导致模型训练困难。使用 Focal Loss 损失函数则可以很好的解决样本不平衡的问题,这种情况下一阶段检测器的精度可以达到甚至超越两阶段检测器的精度。
第六章 总结与展望
6.1 总结
本文提出了一种通用的加速卷积神经网络的方法 PipeCNN,采用软件流水线的思想来加速梯度计算的过程,前向传播与反向传播的计算任务可以灵活地分配在不同的计算设备中,提高了设备利用的效率。为了提高训练的精度,同时也对网络的损失函数进行了改进,即在原始损失函数的基础上添加了动态变化的权值,增大了困难样本与简单样本之间的区分度。综上,本文一共从三个方面对卷积神经网络进行改进:
(1)第一个方面是使用软件流水技术加速卷积神经网络的前向计算,将网络前向传播中每一层的计算看作最小任务单元,提出任务分配算法将任务单元分为若干个工作段,所有的工作段可以并行执行,使用循环队列的数据结构进行相邻工作段的数据通信,以流水的方式完成前向传播的过程。
(2)第二个方面是使用软件流水技术加速卷积神经网络的训练过程,消除了 GPipe 中不可避免的空闲阶段,同时也保证了模型训练的正确性。 根据梯度更新方式的不同,PipeCNN可以分为间断与连续两种类型,其中连续型PipeCNN可更大程度减少流水线的空闲等待时间。在 MNIST 数据集和 Cifar10 数据集的实验中,PipeCNN 加速了卷积神经网络的训练过程,取得了良好的加速比以及设备利用率,这表明 PipeCNN 是一种通用的并行化卷积神经网络的方法。
(3)第三个方面是从损失函数的角度对卷积神经网络进行优化,首先详细研究了 Focalloss 损失函数并指出其中存在的不足,然后基于 Sigmoid 函数给出了相应的优化方法,通过对比实验发现该方法可以提升模型训练的精度。
参考文献(略)