第 1 章 绪论
1.1 研究背景与意义
得益于机器学习技术的发展和计算机算力的进步,人工智能成为推动生产力发展的重要因素之一,已经渗入社会的方方面面并且不断的改变着人类固有的生活方式。为了在全球人工智能发展的浪潮中占得先机,2015 年 5 月文件《中国制造 2025》中明确表示着力发展智能装备以及智能产品,推进生产过程的自动化、智能化。2016 年 7 月文件《“十三五”国家科技创新规划》中明确表示首先发展新一代的信息技术,在人工智能方面,需要重点发展大数据驱动的类人智能技术方法,在基于大数据分析的类人智能方向取得重大突破。2017 年政府的工作报告中,更是首次将工智能写入,重点表明要应用大数据、云计算、物联网等现代技术加快改造提升传统产业,把发展人工智能制造作为主要研究方向。上述文件充分体现了我国政府重视人工智能技术的进步与产业发展,人工智能已然上升为国家战略。
文字是承载人类知识,交流思想的核心工具,文字的重要性不言而喻。文字识别同样也是计算机视觉研究领域的重要组成部分,其中主要包含光学字符识别 OCR(OpticalCharacter Recognition)和场景文字识别 STR(Scene Text Recognition),光学字符识别通俗易懂的解释是利用计算机技术和光学技术把印在或写在纸上的文字识别出来,随后统一转换成一种计算机能够接受并且人又可以理解的形式。平常的生活中,我们也可以切实感受到这个技术所带来的便利,如使用手机 APP 扫描名片、身份证并且识别出里面的信息。保险医疗行业中使用文字识别的方法录入票据信息。而场景文字识别是指识别自然场景图片中的信息,例如使用计算机识别手机拍摄图片中包含的文字信息,理解这些语义信息可以对定位、驾驶等等应用产生巨大的帮助。
传统的扫描文档识别文字因为研究时间长、图像背景简单且文字规整,所以应用和理论均非常成熟而且识别率高,目前的研究内容基本上集中在特殊的语言以及手写体的识别领域。相比于传统的扫描文档识别文字,由于多种图像背景以及多变的字体和风格等因素,场景文字识别复杂度远远高于传统的扫描文档进行文字识别。
.........................
1.2 国内外研究现状
1.2.1 场景文字识别研究现状
2012 年之前传统的文字识别是一个典型的模式识别问题,跟其他模式一样,传统的文字识别主要包括预处理、特征提取、分类这三个步骤,随着深度学习使用 CNN(Convolutional Neural Networks)[1]卷积神经网络在分类问题上取得重大突破,以及 GPU算力的不断提升,研究方向转向到以训练深度学习模型识别为主要方式。目前对于场景文字识别问题主要的研究思路分为两种,第一种方案首先检测图片中文本行的位置,然后识别检测出的文本行中的字符内容,研究内容的重点聚焦在文本检测与识别上。第二种方案是将这两个过程合并到一个神经网络之中,进行端到端的快速检测识别。当前较好的端到端算法为 FOTS(Fast Oriented Text Spotting with a Unified Network)[2]、和 MaskTextSpotter[3],相比于分阶段进行检测、识别任务。端到端的算法可以在检测和识别之间共享卷积特征和视觉信息,减少模型的训练参数以及时间损耗,但是由于当前深度学习算法的约束,最终识别准确率较低。所以目前主要的研究工作集中于第一种方案。
关于文本行检测阶段,近期较好的检测算法为 PSENet(Shape Robust Text Detectionwith Progressive Scale Expansion Network)[4]以及 CRAFT(Character Region Awareness forText Detection)[5]。PSENet 是一种新的实例分割网络,它有两方面的优势。首先,该模型能够对任意形状的文本进行定位。其次,该模型提出了一种渐进的尺度扩展算法,可以成功地识别相邻文本实例。CRAFT 主要贡献有两点,首先提出了字符级别的文本行检测,更符合目标检测这一核心概念,不是把文本框当做目标,这样使用小感受野也能预测大文本和长文本,只需要关注字符级别的内容而不需要关注整个文本实例。其次提出了如何利用现有文本检测数据集合成数据得到真实数据的单字标注的弱监督方法。
..........................
第 2 章 相关工作
2.1 卷积神经网络
不同于典型的 BP(back propagation)[24]算法全连接神经网络,卷积神经网络是一种局部链接的网络,并且具有权值共享的特点。这种结构的神经网络不仅仅大规模的减少了训练所需的参数,而且提取的特征更符合生物特性,即图像中距离越相近的像素相关性越大。卷积神经网络通过共享权重构成不同的卷积核心,并使用这些卷积核对图像进行卷积运算提取所需的关键特征。
2.1.1 卷积
卷积神经网络的核心操作便是卷积操作,卷积神经网络通过卷积这种特殊的线性运算,提取数据的局部特征。简单卷积操作过程如图(2-1)所示。
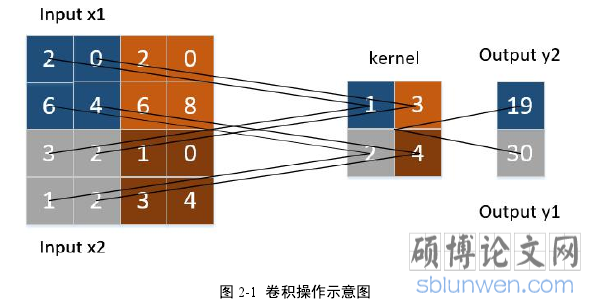
..........................
2.2 文字识别相关概念
2.2.1 循环神经网络
卷积神经网络在处理一系列的数据时,表现出来的性能往往较差。例如数据为一个音频剪辑,包含一段人类说过的话。再比如数据是一个英文句子,句中包含一系列的单词。为了解决数据不定长问题所带来的误差,同时充分的利用系列数据中包含的上下文环境,发明了循环神经网络 RNN 来处理类似的问题。
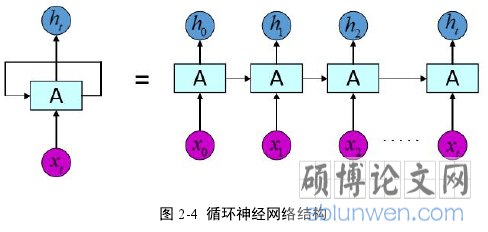
RNN 网络的核心结构示意图如(2-4)所示,图中等号左边是一个典型的 RNN 网络,其中包含输入信息tX ,神经网络单元 A 和一个输出th 。但是与通常的卷积神经网络不同之处是,神经网络单元 A 不仅仅接受在时间 t 输入tX 传入的信息,同样接受了上个时间 t-1 经过神经网络单元处理后的信息。这就表明了循环神经网络的输出信息是根据上一时刻的输入信息和当前的输入信息共同决定的,以这种结构为基础的网络架构,可以充分利用上文包含的语音信息。事实证明,将 RNN 网络应用在语音识别、语言模型、机器翻译等问题中,取得了显著的成功。
.........................
第 3 章 基于预训练模型的课程学习方法............................17
3.1 CRNN 算法................................. 17
3.1.1 CRNN 算法结构.............................. 17
3.1.2 CTC 翻译算法............................18
第 4 章 基于人类经验的课程学习方法.........................31
4.1 人类视角中的图片难度......................31
4.1.1 图片难度信息采集..........................33
4.1.2 相关性评估方法..........................33
第 5 章 总结与展望.........................41
5.1 工作总结........................41
5.2 工作展望.............................41
第 4 章 基于人类经验的课程学习方法
4.1 人类视角中的图片难度
人类天生就可以理解图像中的内容,人类的视觉感知系统几乎可以在毫秒内判断出图片中物体的数量、种类、以及位置[35][36]。虽然计算机在数学运算速度上远超人类,相比于人类的反应时间以及准确率,计算机视觉领域目前研究出的算法在判断效果方面与人类的判断结果相比依旧相距甚远。
图片在其难度上并不是均等的,一些图片可以十分轻易并且迅速的判断其中的内容,另一些图片可能需要耗费更长的时间去探究,人类进行判断所耗费的时间一定程度上反映了图片的难度[37][38][39]。根据人类的直觉感受,判断一张图片的内容难度可能和这些因素有关。例如图片所在场景的复杂程度,背景是否混乱,其中包含物体的种类,其中的物体是否被遮挡等等。
为了更深入的分析增加计算视觉问题难度的原因,文献[40]提出了一种衡量图像在视觉理解方面难易程度的方法。众所周知人在进行视觉搜索时,首先对被搜索图像进行观察,获取图像中有特征的重要主体,再在大脑中搜寻其对应的物体种类,即先对图像进行抽象,再进行分类。在当前的研究中,研究方向主要集中于如何提高精度。与此不同的是这篇文章通过具体分析了,什么样的图片是容易被识别的,什么样的是难被识别的。
联想到课程学习方法所需要的两个关键条件,首先如何使用一种合理的方式判断训练集样本的难度,其次如何在难度提升的训练集上训练模型。这种难度分析方法可能对场景文字难度定义提供新的思路。
..........................
第 5 章 总结与展望
5.1 工作总结
为了进一步提高场景文字识别模型的识别效果,本文提出了使用课程学习方法优化文字识别模型。文中首先介绍了国内外场景文字识别研究的发展研究现状以及课程学习方法的应用情况,然后将文字识别以及课程学习的基本理论进行概述。随后使用不同的方式得到课程学习序列训练场景文字识别模型,并通过对比试验进行分析,对算法的效果进行评估。本文的主要工作内容有以下几点:
(1)提出了一种基于预训练模型判断的样本难度,并使用课程学习对场景文字识别算法进行优化的办法,该方法首先使用 Synthtext80K、ICDAR2013、ICDAR2015 数据集预训练一个场景识别文字模型,随后使用这个预训练的对 COCO-Text 数据集做识别,根据识别结果得到一组难度提升的课程学习序列,最终根据课程学习中样本的序列,使用从简单到困难的顺序训练模型。在具体的训练过程中,通过改变评价尺度、改变训练集子集数对实验过程进行不断优化。最后通过对实验结果的对比分析可以看出本文提出的方法可以有效地提升场景文字识别算法的准确率并在训练初期减少模型的收敛时间,并且使用不同的训练集子集进行课程学习训练,最终使得 ASTER 算法在 COCO-Text 数据集上最高得到 1.8%的提升,CRNN 算法在 COCO-Text 数据集上得到 1.13%的提升,充分证明了算法的有效性。
(2)提出了一种基于人类视角中导致图片困难的关键特征判断样本难度,并使用课程学习对场景文字识别算法进行优化的办法。该方法通过使用不同维度的图片特征对数据集图片进行难度判断,从而以难度提升的样本顺序对场景文字识别算法进行课程学习训练。文章首先使用低层特征,例如图片样本的标签文字个数、图片样本的大小、图片样本的方向,对 COCO-Text 训练集进行简单的样本分析,其次使用神经网络提取物体数量、边缘强度、部分个数这三种中层特征拟合人类标注的难度分数对训练集进行难度判断。使用这两种不同的方式判断样本难度并使用课程学习方法进行 CRNN 模型训练,结果分别提升 0.23%、0.57%,同样证明了算法的有效性。
参考文献(略)